






















































An ANN is a collection of tensors (weights) and mathematical operations, arranged in such a way to loosely replicate the functioning of a human brain. It can be viewed as a mathematical function that takes in one or more tensors as inputs and predicts one or more tensors as outputs. The arrangement of operations that connects these inputs to outputs is referred to as the architecture of the neural network – which we can customize based on the task at hand, that is, based on whether the problem contains structured (tabular) or unstructured (image, text, audio) data (which is the list of input and output tensors).
An ANN is made up of the following:
- Input layers: These layers take the independent variables as input.
- Hidden (intermediate) layers: These layers connect the input and output layers while performing transformations on top of input data. Furthermore, the hidden layers contain nodes (units/circles in the following diagram) to modify their input values into higher-/lower-dimensional values. The functionality to achieve a more complex representation is achieved by using various activation functions that modify the values of the nodes of intermediate layers.
- Output layer: This contains the values the input variables are expected to result in.
With this in mind, the typical structure of a neural network is as follows:
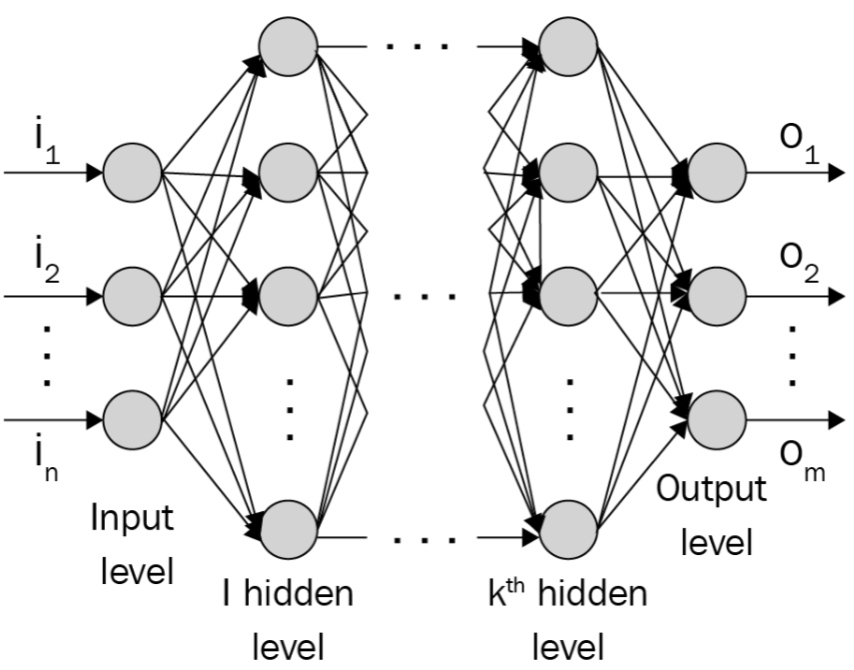
The number of nodes (circles in the preceding diagram) in the output layer depends on the task at hand and whether we are trying to predict a continuous variable or a categorical variable. If the output is a continuous variable, the output has one node. If the output is categorical with m possible classes, there will be m nodes in the output layer. Let's zoom into one of the nodes/neurons and see what's happening. A neuron transforms its inputs as follows:
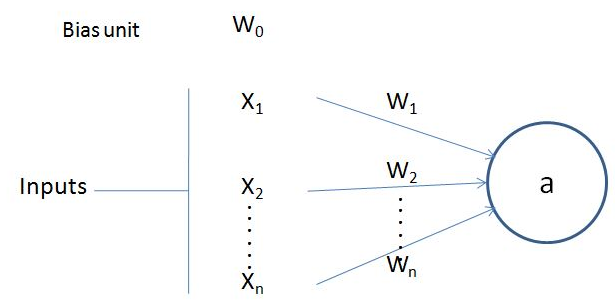
In the preceding diagram, x1,x2, ..., xn are the input variables, and w0 is the bias term (similar to the way we have a bias in linear/logistic regression).
Note that w1,w2, ..., wn are the weights given to each of the input variables and w0 is the bias term. The output value a is calculated as follows:
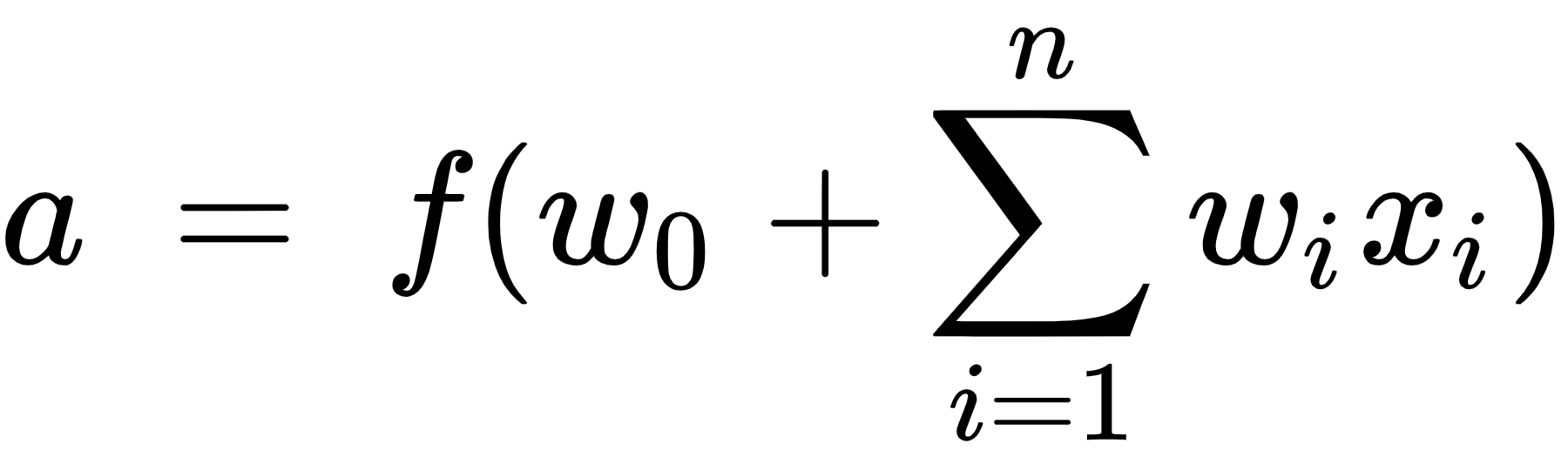
As you can see, it is the sum of the products of weight and input pairs followed by an additional function f (the bias term + sum of products). The function f is the activation function that is used to apply non-linearity on top of this sum of products. More details on the activation functions will be provided in the next section, on feedforward propagation. Further, higher nonlinearity can be achieved by having more than one hidden layer, stacking multitudes of neurons.
At a high level, a neural network is a collection of nodes where each node has an adjustable float value and the nodes are interconnected as a graph to return outputs in a format that is dictated by the architecture of the network. The network constitutes three main parts: the input layer, the hidden layer(s), and the output layer. Note that you can have a higher number (n) of hidden layers, with the term deep learning referring to the greater number of hidden layers. Typically, more hidden layers are needed when the neural network has to comprehend something complicated such as image recognition.
With the architecture of a neural network understood, in the next section, we will learn about feedforward propagation, which helps in estimating the amount of error (loss) the network architecture has.




