






















































ML approaches are based on a set of statistical and mathematical algorithms in order to carry out tasks such as classification, regression analysis, concept learning, predictive modeling, clustering, and mining of useful patterns. Thus, with the use of ML, we aim at improving the learning experience such that it becomes automatic. Consequently, we may not need complete human interactions, or at least we can reduce the level of such interactions as much as possible.
A soft introduction to ML
Working principles of ML algorithms
We now refer to a famous definition of ML by Tom M. Mitchell (Machine Learning, Tom Mitchell, McGraw Hill), where he explained what learning really means from a computer science perspective:
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."
Based on this definition, we can conclude that a computer program or machine can do the following:
- Learn from data and histories
- Improve with experience
- Iteratively enhance a model that can be used to predict outcomes of questions
Since they are at the core of predictive analytics, almost every ML algorithm we use can be treated as an optimization problem. This is about finding parameters that minimize an objective function, for example, a weighted sum of two terms like a cost function and regularization. Typically, an objective function has two components:
- A regularizer, which controls the complexity of the model
- The loss, which measures the error of the model on the training data.
On the other hand, the regularization parameter defines the trade-off between minimizing the training error and the model's complexity in an effort to avoid overfitting problems. Now, if both of these components are convex, then their sum is also convex; it is non-convex otherwise. More elaborately, when using an ML algorithm, the goal is to obtain the best hyperparameters of a function that return the minimum error when making predictions. Therefore, using a convex optimization technique, we can minimize the function until it converges towards the minimum error.
Given that a problem is convex, it is usually easier to analyze the asymptotic behavior of the algorithm, which shows how fast it converges as the model observes more and more training data. The challenge of ML is to allow training a model so that it can recognize complex patterns and make decisions not only in an automated way but also as intelligently as possible. The entire learning process requires input datasets that can be split (or are already provided) into three types, outlined as follows:
- A training set is the knowledge base coming from historical or live data used to fit the parameters of the ML algorithm. During the training phase, the ML model utilizes the training set to find optimal weights of the network and reach the objective function by minimizing the training error. Here, the back-prop rule (or another more advanced optimizer with a proper updater; we'll see this later on) is used to train the model, but all the hyperparameters are need to be set before the learning process starts.
- A validation set is a set of examples used to tune the parameters of an ML model. It ensures that the model is trained well and generalizes towards avoiding overfitting. Some ML practitioners refer to it as a development set or dev set as well.
- A test set is used for evaluating the performance of the trained model on unseen data. This step is also referred to as model inferencing. After assessing the final model on the test set (that is, when we're fully satisfied with the model's performance), we do not have to tune the model any further but the trained model can be deployed in a production-ready environment.
A common practice is splitting the input data (after necessary pre-processing and feature engineering) into 60% for training, 10% for validation, and 20% for testing, but it really depends on use cases. Also, sometimes we need to perform up-sampling or down-sampling on the data based on the availability and quality of the datasets.
Moreover, the learning theory uses mathematical tools that derive from probability theory and information theory. Three learning paradigms will be briefly discussed:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
The following diagram summarizes the three types of learning, along with the problems they address:
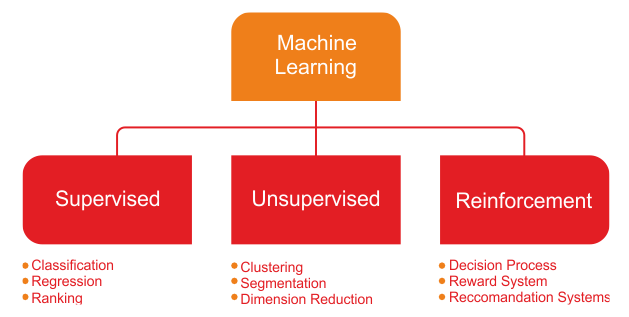
Types of learning and related problems
Supervised learning
Supervised learning is the simplest and most well-known automatic learning task. It is based on a number of pre-defined examples, in which the category to which each of the inputs should belong is already known. Figure 2 shows a typical workflow of supervised learning.
An actor (for example, an ML practitioner, data scientist, data engineer, ML engineer, and so on) performs Extraction Transformation Load (ETL) and the necessary feature engineering (including feature extraction, selection, and so on) to get the appropriate data having features and labels. Then he does the following:
- Splits the data into training, development, and test sets
- Uses the training set to train an ML model
- The validation set is used to validate the training against the overfitting problem and regularization
- He then evaluates the model's performance on the test set (that is unseen data)
- If the performance is not satisfactory, he can perform additional tuning to get the best model based on hyperparameter optimization
- Finally, he deploys the best model in a production-ready environment
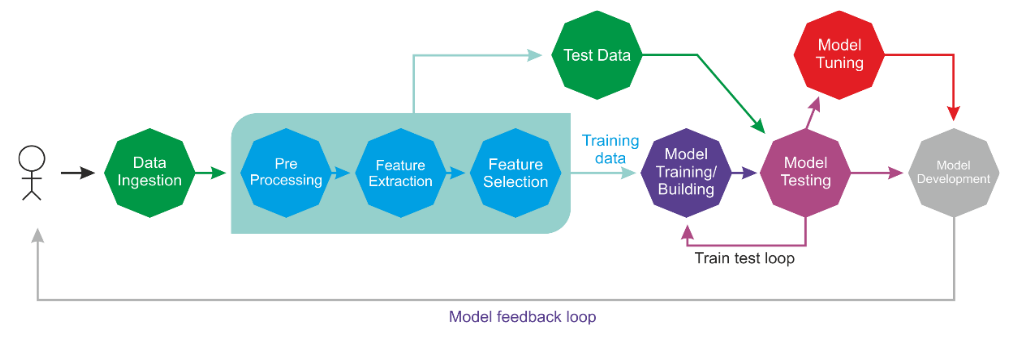
Supervised learning in action
In the overall life cycle, there might be many actors involved (for example, a data engineer, data scientist, or ML engineer) to perform each step independently or collaboratively.
The supervised learning context includes classification and regression tasks; classification is used to predict which class a data point is part of (discrete value), while regression is used to predict continuous values. In other words, a classification task is used to predict the label of the class attribute, while a regression task is used to make a numeric prediction of the class attribute.
In the context of supervised learning, unbalanced data refers to classification problems where we have unequal instances for different classes. For example, if we have a classification task for only two classes, balanced data would mean 50% pre-classified examples for each of the classes.
If the input dataset is a little unbalanced (for example, 60% data points for one class and 40% for the other class), the learning process will require for the input dataset to be split randomly into three sets, with 50% for the training set, 20% for the validation set, and the remaining 30% for the testing set.
Unsupervised learning
In unsupervised learning, an input set is supplied to the system during the training phase. In contrast with supervised learning, the input objects are not labeled with their class. For classification, we assumed that we are given a training dataset of correctly labeled data. Unfortunately, we do not always have that advantage when we collect data in the real world.
For example, let's say you have a large collection of totally legal, not pirated, MP3 files in a crowded and massive folder on your hard drive. In such a case, how could we possibly group songs together if we do not have direct access to their metadata? One possible approach could be to mix various ML techniques, but clustering is often the best solution.
Now, what if you can build a clustering predictive model that helps automatically group together similar songs and organize them into your favorite categories, such as country, rap, rock, and so on? In short, unsupervised learning algorithms are commonly used in clustering problems. The following diagram gives us an idea of a clustering technique applied to solve this kind of problem:
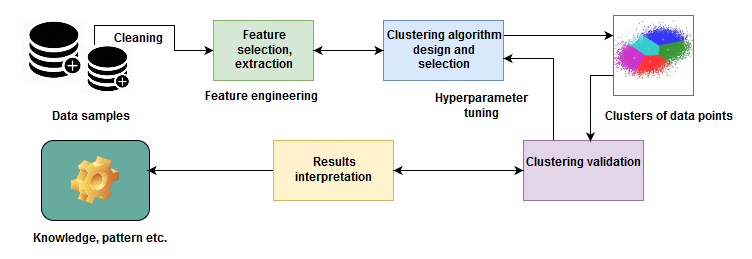
Clustering techniques – an example of unsupervised learning
Although the data points are not labeled, we can still do the necessary feature engineering and grouping of a set of objects in such a way that objects in the same group (called a cluster) are brought together. This is not easy for a human. Rather, a standard approach is to define a similarity measure between two objects and then look for any cluster of objects that are more similar to each other than they are to the objects in the other clusters. Once we've done the clustering of the data points (that is, MP3 files) and the validation is completed, we know the pattern of the data (that is, what type of MP3 files fall in which group).
Reinforcement learning
Reinforcement learning is an artificial intelligence approach that focuses on the learning of the system through its interactions with the environment. In reinforcement learning, the system's parameters are adapted based on the feedback obtained from the environment, which in turn provides feedback on the decisions made by the system. The following diagram shows a person making decisions in order to arrive at their destination.
Let's take an example of the route you take from home to work. In this case, you take the same route to work every day. However, out of the blue, one day you get curious and decide to try a different route with a view to finding the shortest path. This dilemma of trying out new routes or sticking to the best-known route is an example of exploration versus exploitation:
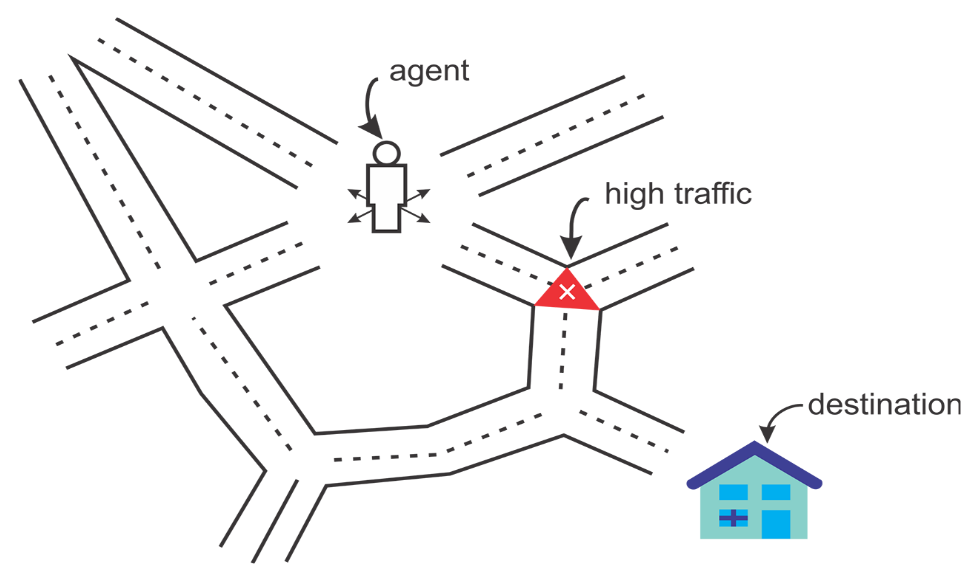
An agent always tries to reach the destination
We can take a look at one more example in terms of a system modeling a chess player. In order to improve its performance, the system utilizes the result of its previous moves; such a system is said to be a system learning with reinforcement.
Putting ML tasks altogether
We have seen the basic working principles of ML algorithms. Then we have seen what the basic ML tasks are and how they formulate domain-specific problems. Now let's take a look at how can we summarize ML tasks and some applications in the following diagram:
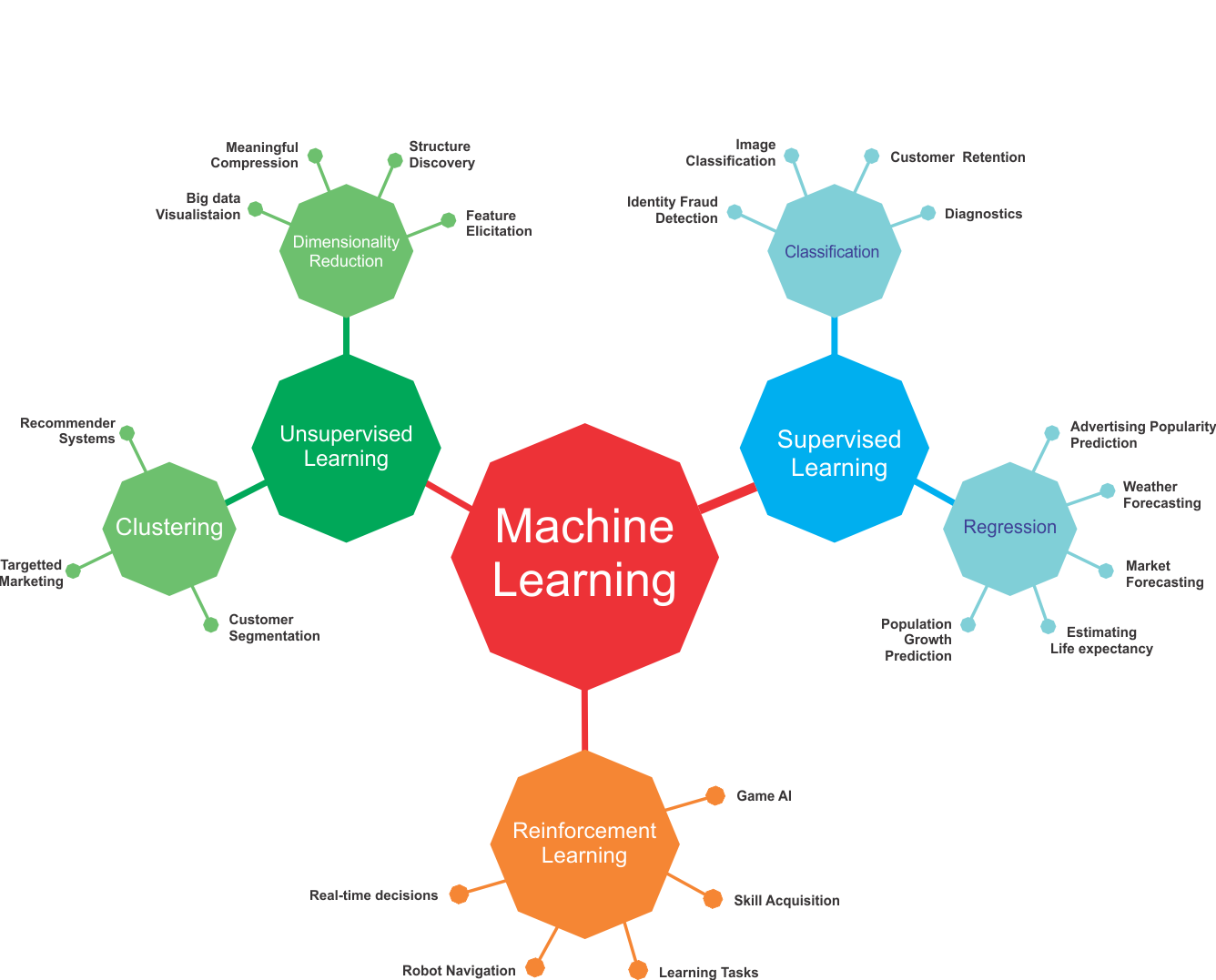
ML tasks and some use cases from different application domains
However, the preceding figure lists only a few use cases and applications using different ML tasks. In practice, ML is used in numerous use cases and applications. We will try to cover a few of those throughout this book.








