






















































Prediction and control tasks
In reinforcement learning, we perform two important tasks, and they are:
- The prediction task
- The control task
Prediction task
In the prediction task, a policy 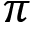 is given as an input and we try to predict the value function or Q function using the given policy. But what is the use of doing this? Our goal is to evaluate the given policy. That is, we need to determine whether the given policy is good or bad. How can we determine that? If the agent obtains a good return using the given policy then we can say that our policy is good. Thus, to evaluate the given policy, we need to understand what the return the agent would obtain if it uses the given policy. To obtain the return, we predict the value function or Q function using the given policy.
is given as an input and we try to predict the value function or Q function using the given policy. But what is the use of doing this? Our goal is to evaluate the given policy. That is, we need to determine whether the given policy is good or bad. How can we determine that? If the agent obtains a good return using the given policy then we can say that our policy is good. Thus, to evaluate the given policy, we need to understand what the return the agent would obtain if it uses the given policy. To obtain the return, we predict the value function or Q function using the given policy.
That is, we learned that the value function or value of a state denotes the expected return an agent would obtain starting from that state following some policy 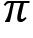 . Thus, by predicting...
. Thus, by predicting...




