






















































Assigning data to windows
We have already touched on (but have not yet defined) the concept of a window. A window is a specific, bounded range of data within a data stream. Beam has several types of pre-defined window functions:
- Tumbling windows
- Sliding windows
- Session windows
Tumbling windows are for assigning data elements into a single window of a pre-defined length, as follows:
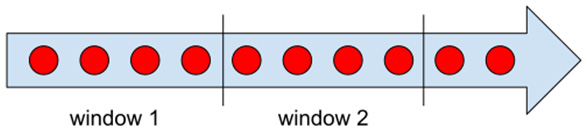
Figure 1.9 – Tumbling windows
Tumbling windows can each have exactly the same fixed length (for example, 1 hour or 1 day in what are called fixed windows), or different lengths (for example, 1 month in what are called calendar windows). The common property of tumbling windows is that the event time of each element can be assigned to exactly one window, and that these windows cover a continuous, (possibly) infinite time range, without any gaps.
Sliding windows are windows that assign data elements into multiple windows, shifted by a time period called a slide, as shown in the following figure:
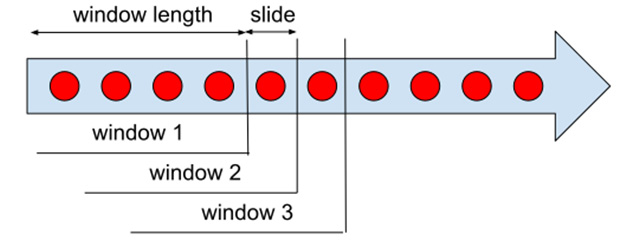
Figure 1.10 – Sliding windows
Sliding windows have the same fixed window length (for example, 1 hour) and the same fixed slide (for example, 10 minutes). A sliding window of 1 hour with a slide of 10 minutes assigns each event time into six distinct windows, each shifted by 10 minutes.
The last type of window is called a session window. This type of window is special in several ways. Unlike both previous types, session windows are key unaligned. What does that mean? Neither tumbling nor sliding windows depend on the data itself – each data element is assigned to a window (or several windows) based solely on the element's timestamp. The boundary of all the windows in the stream is exactly aligned for all the data. This is not the case for session windows. Session windows split the stream into independent sub-streams based on a user-provided key for each element in the stream. We can imagine the key as a color representing each stream element. Session windows group only elements having the same color, therefore, windows in the stream are no longer aligned on the same boundary. We can illustrate this as follows:
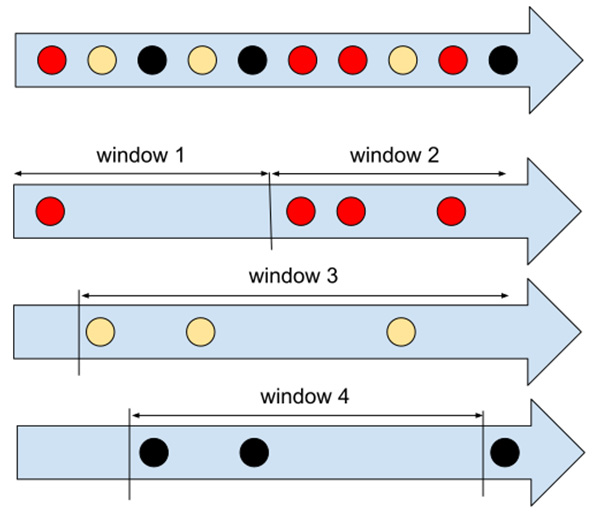
Figure 1.11 – Session windows
We can see from Figure 1.11 that different keys (types) of elements are grouped in different windows. There, one other parameter that has to be specified: a session gap duration. This duration is a timeout (in the event time) that has to elapse between the timestamps of two successive elements with the same key in order to prevent assigning them in the same window. That is to say, as long as elements for a key arrive with a frequency higher than the gap duration, all are placed in the same window. Once there is a delay of at least the gap duration, the window is closed, and another window will be created when a new element arrives. This type of window is frequently used when analyzing user sessions in web clickstreams (which is where the name session window came from).
There is one more special window type called a global window. This very special type of window assigns all data elements into a single window, regardless of their timestamp. Therefore, the window spans a complete time interval from –infinity to +infinity. This window is used as a default window before any other window is applied. We'll look into this later in this chapter.
Defining the life cycle of a state in terms of windows
Windows are actually a way of scoping a state in computation. Each state is valid within the context of a window, and each window has its own independent state.
Figure 1.12 illustrates state scoping:
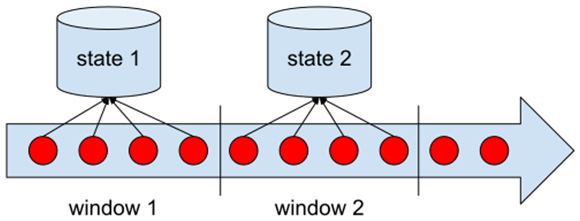
Figure 1.12 – Scoping state within windows
The scoping of states by windows brings up another crucial concept of stream processing: late data elements. One such element is shown in Figure 1.7.
We can state the problem as follows: when can we clear and discard the state that belongs to a particular window? Obviously, it is impractical to keep all states of all windows open forever, because each window carries a non-zero memory footprint, and keeping the window around for an unbounded time would cause the memory to be depleted over time. On the other hand, deleting the state right after the watermark passes the timestamp that marks the end of the window would mean we need a perfect watermark (a watermark that never produces late data). Any possible late data would mean we would produce incorrect outputs – the state would be cleared before all the data elements belonging to the respective window could be processed and therefore would have to be dropped or would produce a completely wrong outcome.
One option would be to define semantics that would require the watermark to advance only when the probability of late data is sufficiently low. We would drop all data that arrived after the watermark and pretend that we didn't see it. If the watermark produces a sufficiently low number of this late data, the error introduced by dropping the late data would be negligible. The crucial problem with this approach is that it necessarily introduces very high latency due to the out-of-orderness of stream processing. We would therefore face a latency versus correctness trade-off, when our goal ideally should be to have both high correctness and low latency.
To resolve this dilemma, stream processing engines introduce an additional concept called allowed lateness. This defines a timeout (in the event time) after which the state in a window can be cleared and all remaining data can be cleared. This option gives us the possibility to achieve the following:
- Enable the watermark heuristic to advance sufficiently quickly to not incur unnecessary latency.
- Enable an independent measure of how many states are to be kept around, even after their maximal timestamp has already passed.
We illustrate this concept in Figure 1.13, which shows a simple watermark heuristic that just shifts the processing time by a constant duration (which will define minimal latency) and a late data boundary, which shifts the watermark by an additional allowed lateness duration. This might introduce data that will be actually dropped but can now be tuned independently:
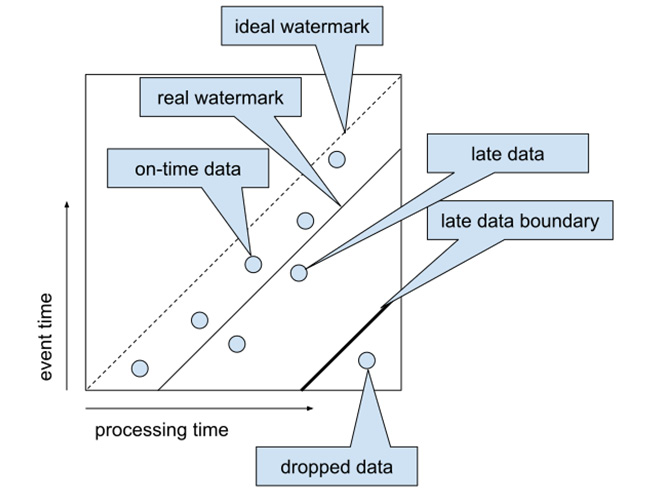
Figure 1.13 – Allowed lateness
Important note
Practical watermark implementations do not typically use a fixed shift between the watermark and processing time, but rather use statistics inferred from consumed data to produce a watermark that is non-linear in terms of the processing time.
The definition of on-time and late data brings up one last technical term that appears in the context of triggers (see the States, triggers, and timers section as a reminder). When a trigger condition is met and the trigger causes output data to be emitted downstream, three possible conditions can occur:
- The watermark has not yet reached the end timestamp of a window.
- The watermark has crossed the window end timestamp, and this is the first activation of a trigger since then.
- The watermark has passed the window end timestamp, and this is not the first activation of a trigger.
According to these three conditions, we can mark the resulting downstream data element as one of the following:
- Early: The data is emitted prior to terminating the respective window's end timestamp – this means that we output speculative partial results.
- On-time: This marks data that was calculated once the window's end timestamp was reached.
- Late: This contains any output with late data incorporated.
Beam calls data emitted as a result of trigger firings a pane and puts the information about lateness or earliness of such firing into the PaneInfo object.
Pane accumulation
When a trigger fires and causes data to be output from the current window(s) to downstream processing, there are several options that can be used with both the state associated with the window and with the resulting value itself.
After a trigger fires and data is output downstream, we have essentially two options:
- Reset the state to an empty (initial) state (discard).
- Keep the state intact (accumulate).
This concept might be a little confusing, so we'll demonstrate it with an example. Let's assume that we want to count the number of elements in a stream every minute in the processing time. In general, window functions are based on event time, so to get something that would resemble a processing time window, we can use the following:
// Window into single window and specify trigger PCollection<String> windowed = words.apply( Window.<String>into(new GlobalWindows()) .triggering( Repeatedly.forever( AfterProcessingTime.pastFirstElementInPane() .plusDelayOf(Duration.standardSeconds(1)))) .discardingFiredPanes());
Please investigate the complete source code in the com.packtpub.beam.chapter1.ProcessingTimeWindow class.
We can run this pipeline using the following:
chapter1$ ../mvnw exec:java \ -Dexec.mainClass=com.packtpub.beam.chapter1.ProcessingTimeWindow
Please feel free to experiment with changing discardingFiredPanes to accumulatingFiredPanes to see how the output differs. In the accumulation mode, the output contains the sum of the elements from the beginning, while in the discarding mode, it contains only increments from the last trigger firing.
Now that we have discussed all the key properties of data streams, let's see how we can use this knowledge to close the gap between batch processing and real-time stream processing!

