






















































Overcoming real-life issues using the three-step approach
The key point of this chapter is to avoid writing code that will never be used. First, begin by understanding the subject as a subject matter expert. Then, write the analysis with words and mathematics to make sure your reasoning reflects the subject and, most of all, that the program will make sense in real life. Finally, in step 3, only write the code when you are sure about the whole project.
Too many developers start writing code without stopping to think about how the results of that code are going to manifest themselves within real-life situations. You could spend weeks developing the perfect code for a problem, only to find out that an external factor has rendered your solution useless. For instance, what if you coded a solar-powered robot to clear snow from the yard, only to discover that during winter, there isn't enough sunlight to power the robot!
In this chapter, we are going to tackle the MDP (Q function) and apply it to reinforcement learning with the Bellman equation. We are going to approach it a little differently to most, however. We'll be thinking about practical application, not simply code execution. You can find tons of source code and examples on the web. The problem is, much like our snow robot, such source code rarely considers the complications that come about in real-life situations. Let's say you find a program that finds the optimal path for a drone delivery. There's an issue, though; it has many limits that need to be overcome due to the fact that the code has not been written with real-life practicality in mind. You, as an adaptive thinker, are going to ask some questions:
- What if there are 5,000 drones over a major city at the same time? What happens if they try to move in straight lines and bump into each other?
- Is a drone-jam legal? What about the noise over the city? What about tourism?
- What about the weather? Weather forecasts are difficult to make, so how is this scheduled?
- How can we resolve the problem of coordinating the use of charging and parking stations?
In just a few minutes, you will be at the center of attention among theoreticians who know more than you, on one hand, and angry managers who want solutions they cannot get on the other. Your real-life approach will solve these problems. To do that, you must take the following three steps into account, starting with really getting involved in the real-life subject.
In order to successfully implement our real-life approach, comprised of the three steps outlined in the previous section, there are a few prerequisites:
- Be a subject matter expert (SME): First, you have to be an SME. If a theoretician geek comes up with a hundred TensorFlow functions to solve a drone trajectory problem, you now know it is going to be a tough ride in which real-life parameters are constraining the algorithm. An SME knows the subject and thus can quickly identify the critical factors of a given field. AI often requires finding a solution to a complex problem that even an expert in a given field cannot express mathematically. Machine learning sometimes means finding a solution to a problem that humans do not know how to explain. Deep learning, involving complex networks, solves even more difficult problems.
- Have enough mathematical knowledge to understand AI concepts: Once you have the proper natural language analysis, you need to build your abstract representation quickly. The best way is to look around and find an everyday life example and make a mathematical model of it. Mathematics is not an option in AI, but a prerequisite. The effort is worthwhile. Then, you can start writing a solid piece of source code or start implementing a cloud platform ML solution.
- Know what source code is about as well as its potential and limits: MDP is an excellent way to go and start working on the three dimensions that will make you adaptive: describing what is around you in detail in words, translating that into mathematical representations, and then implementing the result in your source code.
With those prerequisites in mind, let's look at how you can become a problem-solving AI expert by following our practical three-step process. Unsurprisingly, we'll begin at step 1.
Step 1 – describing a problem to solve: MDP in natural language
Step 1 of any AI problem is to go as far as you can to understand the subject you are asked to represent. If it's a medical subject, don't just look at data; go to a hospital or a research center. If it's a private security application, go to the places where they will need to use it. If it's for social media, make sure to talk to many users directly. The key concept to bear in mind is that you have to get a "feel" for the subject, as if you were the real "user."
For example, transpose it into something you know in your everyday life (work or personal), something you are an SME in. If you have a driver's license, then you are an SME of driving. You are certified. This is a fairly common certification, so let's use this as our subject matter in the example that will follow. If you do not have a driver's license or never drive, you can easily replace moving around in a car by imagining you are moving around on foot; you are an SME of getting from one place to another, regardless of what means of transport that might involve. However, bear in mind that a real-life project would involve additional technical aspects, such as traffic regulations for each country, so our imaginary SME does have its limits.
Getting into the example, let's say you are an e-commerce business driver delivering a package in a location you are unfamiliar with. You are the operator of a self-driving vehicle. For the time being, you're driving manually. You have a GPS with a nice color map on it. The locations around you are represented by the letters A to F, as shown in the simplified map in the following diagram. You are presently at F. Your goal is to reach location C. You are happy, listening to the radio. Everything is going smoothly, and it looks like you are going to be there on time. The following diagram represents the locations and routes that you can cover:

Figure 1.2: A diagram of delivery routes
The guidance system's state indicates the complete path to reach C. It is telling you that you are going to go from F to B to D, and then to C. It looks good!
To break things down further, let's say:
- The present state is the letter s. s is a variable, not an actual state. It can be one of the locations in L, the set of locations:
L = {A, B, C, D, E, F}
We say present state because there is no sequence in the learning process. The memoryless process goes from one present state to another. In the example in this chapter, the process starts at location F.
- Your next action is the letter a (action). This action a is not location A. The goal of this action is to take us to the next possible location in the graph. In this case, only B is possible. The goal of a is to take us from s (present state) to s' (new state).
- The action a (not location A) is to go to location B. You look at your guidance system; it tells you there is no traffic, and that to go from your present state, F, to your next state, B, will take you only a few minutes. Let's say that the next state B is the letter B. This next state B is s'.
At this point, you are still quite happy, and we can sum up your situation with the following sequence of events:
s, a, s'
The letter s is your present state, your present situation. The letter a is the action you're deciding, which is to go to the next location; there, you will be in another state, s'. We can say that thanks to the action a, you will go from s to s'.
Now, imagine that the driver is not you anymore. You are tired for some reason. That is when a self-driving vehicle comes in handy. You set your car to autopilot. Now, you are no longer driving; the system is. Let's call that system the agent. At point F, you set your car to autopilot and let the self-driving agent take over.
Watching the MDP agent at work
The self-driving AI is now in charge of the vehicle. It is acting as the MDP agent. This now sees what you have asked it to do and checks its mapping environment, which represents all the locations in the previous diagram from A to F.
In the meantime, you are rightly worried. Is the agent going to make it or not? You are wondering whether its strategy meets yours. You have your policy P—your way of thinking—which is to take the shortest path possible. Will the agent agree? What's going on in its machine mind? You observe and begin to realize things you never noticed before.
Since this is the first time you are using this car and guidance system, the agent is memoryless, which is an MDP feature. The agent doesn't know anything about what went on before. It seems to be happy with just calculating from this state s at location F. It will use machine power to run as many calculations as necessary to reach its goal.
Another thing you are watching is the total distance from F to C to check whether things are OK. That means that the agent is calculating all the states from F to C.
In this case, state F is state 1, which we can simplify by writing s1; B is state 2, which we can simplify by writing s2; D is s3; and C is s4. The agent is calculating all of these possible states to make a decision.
The agent knows that when it reaches D, C will be better because the reward will be higher for going to C than anywhere else. Since it cannot eat a piece of cake to reward itself, the agent uses numbers. Our agent is a real number cruncher. When it is wrong, it gets a poor reward or nothing in this model. When it's right, it gets a reward represented by the letter R, which we'll encounter during step 2. This action-value (reward) transition, often named the Q function, is the core of many reinforcement learning algorithms.
When our agent goes from one state to another, it performs a transition and gets a reward. For example, the transition can be from F to B, state 1 to state 2, or s1 to s2.
You are feeling great and are going to be on time. You are beginning to understand how the machine learning agent in your self-driving car is thinking. Suddenly, you look up and see that a traffic jam is building up. Location D is still far away, and now you do not know whether it would be good to go from D to C or D to E, in order to take another road to C, which involves less traffic. You are going to see what your agent thinks!
The agent takes the traffic jam into account, is stubborn, and increases its reward to get to C by the shortest way. Its policy is to stick to the initial plan. You do not agree. You have another policy.
You stop the car. You both have to agree before continuing. You have your opinion and policy; the agent does not agree. Before continuing, your views need to converge. Convergence is the key to making sure that your calculations are correct, and it's a way to evaluate the quality of a calculation.
A mathematical representation is the best way to express this whole process at this point, which we will describe in the following step.
Step 2 – building a mathematical model: the mathematical representation of the Bellman equation and MDP
Mathematics involves a whole change in your perspective of a problem. You are going from words to functions, the pillars of source coding.
Expressing problems in mathematical notation does not mean getting lost in academic math to the point of never writing a single line of code. Just use mathematics to get a job done efficiently. Skipping mathematical representation will fast-track a few functions in the early stages of an AI project. However, when the real problems that occur in all AI projects surface, solving them with source code alone will prove virtually impossible. The goal here is to pick up enough mathematics to implement a solution in real-life companies.
It is necessary to think through a problem by finding something familiar around us, such as the itinerary model covered early in this chapter. It is a good thing to write it down with some abstract letters and symbols as described before, with a meaning an action, and s meaning a state. Once you have understood the problem and expressed it clearly, you can proceed further.
Now, mathematics will help to clarify the situation by means of shorter descriptions. With the main ideas in mind, it is time to convert them into equations.
From MDP to the Bellman equation
In step 1, the agent went from F, or state 1 or s, to B, which was state 2 or s'.
A strategy drove this decision—a policy represented by P. One mathematical expression contains the MDP state transition function:
Pa(s, s')
P is the policy, the strategy made by the agent to go from F to B through action a. When going from F to B, this state transition is named the state transition function:
- a is the action
- s is state 1 (F), and s' is state 2 (B)
The reward (right or wrong) matrix follows the same principle:
Ra(s, s')
That means R is the reward for the action of going from state s to state s'. Going from one state to another will be a random process. Potentially, all states can go to any other state.
Each line in the matrix in the example represents a letter from A to F, and each column represents a letter from A to F. All possible states are represented. The 1 values represent the nodes (vertices) of the graph. Those are the possible locations. For example, line 1 represents the possible moves for letter A, line 2 for letter B, and line 6 for letter F. On the first line, A cannot go to C directly, so a 0 value is entered. But, it can go to E, so a 1 value is added.
Some models start with -1 for impossible choices, such as B going directly to C, and 0 values to define the locations. This model starts with 0 and 1 values. It sometimes takes weeks to design functions that will create a reward matrix (see Chapter 2, Building a Reward Matrix – Designing Your Datasets).
The example we will be working on inputs a reward matrix so that the program can choose its best course of action. Then, the agent will go from state to state, learning the best trajectories for every possible starting location point. The goal of the MDP is to go to C (line 3, column 3 in the reward matrix), which has a starting value of 100 in the following Python code:
# Markov Decision Process (MDP) - The Bellman equations adapted to
# Reinforcement Learning
import numpy as ql
# R is The Reward Matrix for each state
R = ql.matrix([ [0,0,0,0,1,0],
[0,0,0,1,0,1],
[0,0,100,1,0,0],
[0,1,1,0,1,0],
[1,0,0,1,0,0],
[0,1,0,0,0,0] ])
Somebody familiar with Python might wonder why I used ql instead of np. Some might say "convention," "mainstream," "standard." My answer is a question. Can somebody define what "standard" AI is in this fast-moving world! My point here for the MDP is to use ql as an abbreviation of "Q-learning" instead of the "standard" abbreviation of NumPy, which is np. Naturally, beyond this special abbreviation for the MDP programs, I'll use np. Just bear in mind that conventions are there to break so as to set ourselves free to explore new frontiers. Just make sure your program works well!
There are several key properties of this decision process, among which there is the following:
- The Markov property: The process does not take the past into account. It is the memoryless property of this decision process, just as you do in a car with a guidance system. You move forward to reach your goal.
- Unsupervised learning: From this memoryless Markov property, it is safe to say that the MDP is not supervised learning. Supervised learning would mean that we would have all the labels of the reward matrix R and learn from them. We would know what A means and use that property to make a decision. We would, in the future, be looking at the past. MDP does not take these labels into account. Thus, MDP uses unsupervised learning to train. A decision has to be made in each state without knowing the past states or what they signify. It means that the car, for example, was on its own at each location, which is represented by each of its states.
- Stochastic process: In step 1, when state D was reached, the agent controlling the mapping system and the driver didn't agree on where to go. A random choice could be made in a trial-and-error way, just like a coin toss. It is going to be a heads-or-tails process. The agent will toss the coin a significant number of times and measure the outcomes. That's precisely how MDP works and how the agent will learn.
- Reinforcement learning: Repeating a trial-and-error process with feedback from the agent's environment.
- Markov chain: The process of going from state to state with no history in a random, stochastic way is called a Markov chain.
To sum it up, we have three tools:
- Pa(s, s'): A policy, P, or strategy to move from one state to another
- Ta(s, s'): A T, or stochastic (random) transition, function to carry out that action
- Ra(s, s'): An R, or reward, for that action, which can be negative, null, or positive
T is the transition function, which makes the agent decide to go from one point to another with a policy. In this case, it will be random. That's what machine power is for, and that is how reinforcement learning is often implemented.
Randomness
Randomness is a key property of MDP, defining it as a stochastic process.
The following code describes the choice the agent is going to make:
next_action = int(ql.random.choice(PossibleAction,1))
return next_action
The code selects a new random action (state) at each episode.
The Bellman equation
The Bellman equation is the road to programming reinforcement learning.
The Bellman equation completes the MDP. To calculate the value of a state, let's use Q, for the Q action-reward (or value) function. The pseudo source code of the Bellman equation can be expressed as follows for one individual state:

The source code then translates the equation into a machine representation, as in the following code:
# The Bellman equation
Q[current_state, action] = R[current_state, action] +
gamma * MaxValue
The source code variables of the Bellman equation are as follows:
- Q(s): This is the value calculated for this state—the total reward. In step 1, when the agent went from F to B, the reward was a number such as 50 or 100 to show the agent that it's on the right track.
- R(s): This is the sum of the values up to that point. It's the total reward at that point.
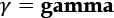 : This is here to remind us that trial and error has a price. We're wasting time, money, and energy. Furthermore, we don't even know whether the next step is right or wrong since we're in a trial-and-error mode. Gamma is often set to 0.8. What does that mean? Suppose you're taking an exam. You study and study, but you don't know the outcome. You might have 80 out of 100 (0.8) chances of clearing it. That's painful, but that's life. The gamma penalty, or learning rate, makes the Bellman equation realistic and efficient.
: This is here to remind us that trial and error has a price. We're wasting time, money, and energy. Furthermore, we don't even know whether the next step is right or wrong since we're in a trial-and-error mode. Gamma is often set to 0.8. What does that mean? Suppose you're taking an exam. You study and study, but you don't know the outcome. You might have 80 out of 100 (0.8) chances of clearing it. That's painful, but that's life. The gamma penalty, or learning rate, makes the Bellman equation realistic and efficient.- max(s'): s' is one of the possible states that can be reached with Pa(s, s'); max is the highest value on the line of that state (location line in the reward matrix).
At this point, you have done two-thirds of the job: understanding the real-life (process) and representing it in basic mathematics. You've built the mathematical model that describes your learning process, and you can implement that solution in code. Now, you are ready to code!
Step 3 – writing source code: implementing the solution in Python
In step 1, a problem was described in natural language to be able to talk to experts and understand what was expected. In step 2, an essential mathematical bridge was built between natural language and source coding. Step 3 is the software implementation phase.
When a problem comes up—and rest assured that one always does—it will be possible to go back over the mathematical bridge with the customer or company team, and even further back to the natural language process if necessary.
This method guarantees success for any project. The code in this chapter is in Python 3.x. It is a reinforcement learning program using the Q function with the following reward matrix:
import numpy as ql
R = ql.matrix([ [0,0,0,0,1,0],
[0,0,0,1,0,1],
[0,0,100,1,0,0],
[0,1,1,0,1,0],
[1,0,0,1,0,0],
[0,1,0,0,0,0] ])
Q = ql.matrix(ql.zeros([6,6]))
gamma = 0.8
R is the reward matrix described in the mathematical analysis.
Q inherits the same structure as R, but all values are set to 0 since this is a learning matrix. It will progressively contain the results of the decision process. The gamma variable is a double reminder that the system is learning and that its decisions have only an 80% chance of being correct each time. As the following code shows, the system explores the possible actions during the process:
agent_s_state = 1
# The possible "a" actions when the agent is in a given state
def possible_actions(state):
current_state_row = R[state,]
possible_act = ql.where(current_state_row >0)[1]
return possible_act
# Get available actions in the current state
PossibleAction = possible_actions(agent_s_state)
The agent starts in state 1, for example. You can start wherever you want because it's a random process. Note that the process only takes values > 0 into account. They represent possible moves (decisions).
The current state goes through an analysis process to find possible actions (next possible states). You will note that there is no algorithm in the traditional sense with many rules. It's a pure random calculation, as the following random.choice function shows:
def ActionChoice(available_actions_range):
if(sum(PossibleAction)>0):
next_action = int(ql.random.choice(PossibleAction,1))
if(sum(PossibleAction)<=0):
next_action = int(ql.random.choice(5,1))
return next_action
# Sample next action to be performed
action = ActionChoice(PossibleAction)
Now comes the core of the system containing the Bellman equation, translated into the following source code:
def reward(current_state, action, gamma):
Max_State = ql.where(Q[action,] == ql.max(Q[action,]))[1]
if Max_State.shape[0] > 1:
Max_State = int(ql.random.choice(Max_State, size = 1))
else:
Max_State = int(Max_State)
MaxValue = Q[action, Max_State]
# Q function
Q[current_state, action] = R[current_state, action] +
gamma * MaxValue
# Rewarding Q matrix
reward(agent_s_state,action,gamma)
You can see that the agent looks for the maximum value of the next possible state chosen at random.
The best way to understand this is to run the program in your Python environment and print() the intermediate values. I suggest that you open a spreadsheet and note the values. This will give you a clear view of the process.
The last part is simply about running the learning process 50,000 times, just to be sure that the system learns everything there is to find. During each iteration, the agent will detect its present state, choose a course of action, and update the Q function matrix:
for i in range(50000):
current_state = ql.random.randint(0, int(Q.shape[0]))
PossibleAction = possible_actions(current_state)
action = ActionChoice(PossibleAction)
reward(current_state,action,gamma)
# Displaying Q before the norm of Q phase
print("Q :")
print(Q)
# Norm of Q
print("Normed Q :")
print(Q/ql.max(Q)*100)
The process continues until the learning process is over. Then, the program will print the result in Q and the normed result. The normed result is the process of dividing all values by the sum of the values found. print(Q/ql.max(Q)*100) norms Q by dividing Q by q1.max(Q)*100. The result comes out as a normed percentage.
You can run the process with mdp01.py.



