






















































Kick Starting an NLP Project
We can divide an NLP project into several sub-projects or phases. These phases are followed sequentially. This tends to increase the overall efficiency of the process as each phase is generally carried out by specialized resources. An NLP project has to go through six major phases, which are outlined in the following figure:
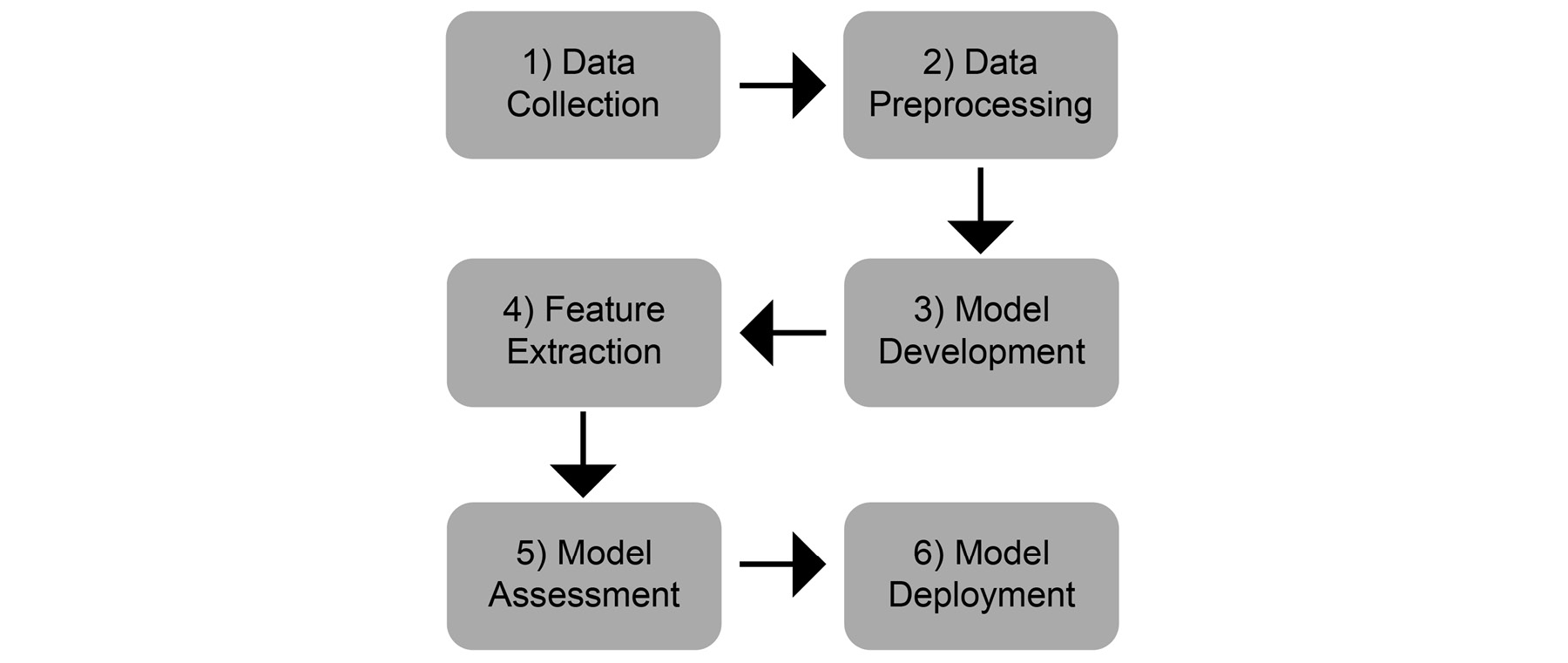
Figure 1.30: Phases of an NLP project
Suppose you are working on a project in which you need to collect tweets and analyze their sentiments. We will explain how this is carried out by discussing each phase in the coming section.
Data Collection
This is the initial phase of any NLP project. Our sole purpose is to collect data as per our requirements. For this, we may either use existing data, collect data from various online repositories, or create our own dataset by crawling the web. In our case, we will collect tweets.
Data Preprocessing
Once the data is collected, we need to clean it. For the process of cleaning, we make use of the different pre-processing steps that we have used in this chapter. It is necessary to clean the collected data, as dirty data tends to reduce effectiveness and accuracy. In our case, we will remove the unnecessary URLs, words, and more from the collected tweets.
Feature Extraction
Computers understand only binary digits: 0 and 1. Thus, every instruction we feed into a computer gets transformed into binary digits. Similarly, machine learning models tend to understand only numeric data. As such, it becomes necessary to convert the text data into its equivalent numerical form. In our case, we represent the cleaned tweets using different kinds of matrices, such as bag of words and TF-IDF. We will be learning more about these matrices in later chapters.
Model Development
Once the feature set is ready, we need to develop a suitable model that can be trained to gain knowledge from the data. These models are generally statistical, machine learning-based, deep learning-based, or reinforcement learning-based. In our case, we will build a model that is capable of extracting sentiments from numeric matrices.
Model Assessment
After developing a model, it is essential to benchmark it. This process of benchmarking is known as model assessment. In this step, we will evaluate the performance of our model by comparing it to others. This can be done by using different parameters or metrics. These parameters include F1, precision, recall, and accuracy. In our case, we will evaluate the newly created model by checking how well it performs when extracting the sentiments of the tweets.
Model Deployment
This is the final stage for most industrial NLP projects. In this stage, the models are put into production. They are either integrated into an existing system or new products are created by keeping this model as a base. In our case, we will deploy our model to production, such that it can extract sentiments from tweets in real time.



