






















































When routing does matter
In this section, we will discuss one of the most powerful control mechanisms that we have in our hands—routing. To be concise, it allows us to choose a shard that will be used to index or search data. It doesn't sound interesting, right? So, before continuing with some use cases I'll try to show you how the standard, distributed search and indexing works in ElasticSearch.
How does indexing work?
During an index operation, when you send a document for indexing, ElasticSearch looks at its identifier to choose the shard in which the document should be indexed. By default, ElasticSearch calculates the hash value of the document's identifier and on the basis of that, puts the document in one of the available primary shards. Then those documents are redistributed to replicas. The following diagram shows a simple illustration of how indexing works by default:
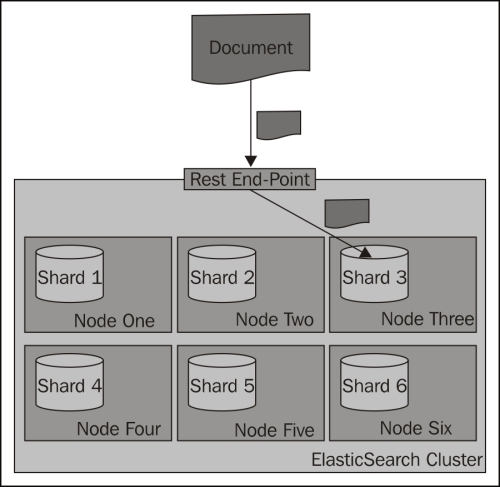
How does searching work?
Searching is a bit different from indexing, because in most situations you need to ask all the shards to get the data you are interested in. Imagine the situation when you have the following mappings describing your index:
{
"mappings" : {
"post" : {
"properties" : {
"id" : { "type" : "long", "store" : "yes",
"precision_step" : "0" },
"name" : { "type" : "string", "store" : "yes",
"index" : "analyzed" },
"contents" : { "type" : "string", "store" : "no",
"index" : "analyzed" },
"userId" : { "type" : "long", "store" : "yes",
"precision_step" : "0" }
}
}
}
}As you can see, our index consists of four fields—the identifier (the id field), the name of the document (the name field), the contents of the document (the contents field), and the identifier of the user to which the documents belong (the userId field). To get all the documents for a particular user—one with userId equal to 12—you can run the following query:
curl –XGET 'http://localhost:9200/posts/_search?q=userId:12'
The preceding request is run against the _search endpoint, which allows us to send queries to ElasticSearch. All the queries we send to ElasticSearch will be sent to that endpoint. The following diagram shows a simple illustration of how searching works by default:
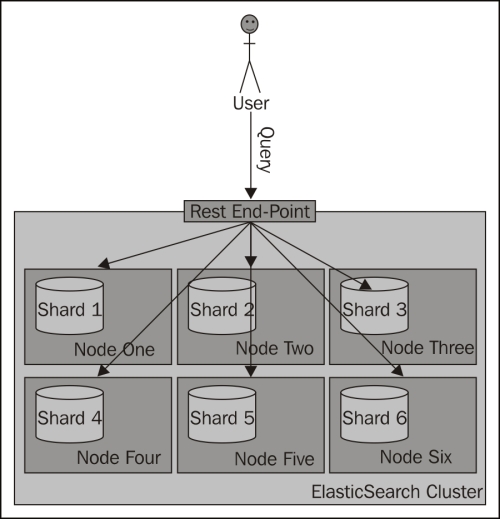
What if we could put all the documents for a single user into a single shard and query on that shard? Wouldn't that be performance wise? Yes, that is handy, and that is what routing allows you do to.
Routing
Routing can be used to control to which shard your documents and queries will be forwarded. As we have already mentioned, by default, ElasticSearch uses the value of the document's identifier to calculate the hash value, which is then used to place the document in a given shard. With such behavior, all the shards get a similar amount of data indexed and during search all those shards are queried. By now you would probably have guessed that in ElasticSearch you can specify the routing value both at index-time and during querying, and in fact if you decide to specify explicit routing values, you'll probably do that during both indexing and searching.
In our case, we would use the userId value to set routing during indexing and the same value during searching. You can imagine that for the same userId value, the same hash value will be calculated and thus all the documents for that particular user will be placed in the same shard. Using the same value during searching will result in searching a single shard instead of the whole index.
Please remember that when using routing, you should still add a filter for the same value as the routing one. This is because you'll probably have more distinct routing values than the number of shards of which your index will be built. Because of that, a few distinct values can point to the same shard; if you were to omit the filtering, you would get data not for a single value you route on, but for all those that reside in a particular shard. The following diagram shows a simple illustration of how searching works with a custom routing value provided:
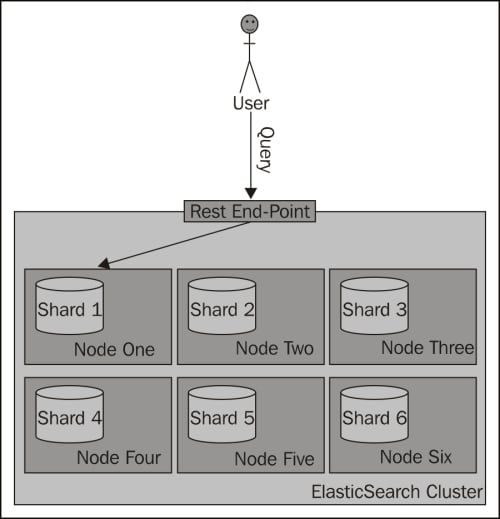
Now let's look at how we can specify the routing values.
Routing parameters
The simplest way (but not always the most convenient one) to provide routing values is to use the routing parameter. When indexing or querying, you should just add the routing parameter to your HTTP or set it by using the client library of your choice.
So, to index a sample document to the previously shown index, we would use the following command:
curl -XPUT 'http://localhost:9200/posts/post/1?routing=12' -d '{
"id": "1",
"name": "Test document",
"contents": "Test document",
"userId": "12"
}'This is what our previous query would look like, if we were to add the routing parameter:
curl –XGET 'http://localhost:9200/posts/_search?routing=12&q=userId:12'
As you can see, the same routing value was used during indexing and querying. We did that because we knew that during indexing we have used the value 12. We wanted to point our query to the same shard, therefore we used exactly the same value.
Please note that you can specify multiple routing values, which should be separated by comma characters. For example, if we want the preceding query to be additionally routed with the use of the section parameter (if such existed) and we also want to filter by this parameter, our query will look like the following:
curl –XGET 'http://localhost:9200/posts/_search?routing=12,6654&q=userId:12+AND+section:6654'
Routing fields
Specifying the routing value with each request that we send to ElasticSearch works, but it is not convenient. In fact, ElasticSearch allows us to define a field whose value will be used as the routing value during indexing, so we only need to provide the routing parameter during querying. To do that, we need to add the following section to our type definition:
"_routing" : {
"required" : true,
"path" : "userId"
}The preceding definition means that the routing value needs to be provided (the "required": true property); without it, an index request will fail. In addition to that we specified the path attribute, which decides which field value of the document will be used as the routing value. In our case, the userId field value will be used. These two parameters mean that each document we send for indexing needs to have the userId field defined. This is convenient, because we can now use batch indexing without the limitation of having all the documents from a single branch using the same routing value (which would be the case with the routing parameter). However, please remember that when using the routing field, ElasticSearch needs to do some additional parsing. Therefore, it's a bit slower than the use of the routing parameter.
After adding the routing part, the whole updated mappings file will be as follows:
{
"mappings" : {
"post" : {
"_routing" : {
"required" : true,
"path" : "userId"
},
"properties" : {
"id" : { "type" : "long", "store" : "yes",
"precision_step" : "0" },
"name" : { "type" : "string", "store" : "yes",
"index" : "analyzed" },
"contents" : { "type" : "string", "store" : "no",
"index" : "analyzed" },
"userId" : { "type" : "long", "store" : "yes",
"precision_step" : "0" }
}
}
}
}