






















































About the Book
Where there's data, there's insight. With so much data being generated, there is immense scope to extract meaningful information that'll boost business productivity and profitability. By learning to convert raw data into game-changing insights, you'll open new career paths and opportunities.
The Data Science Workshop, Second Edition, begins by introducing different types of projects and showing you how to incorporate machine learning algorithms in them. You'll learn to select a relevant metric and even assess the performance of your model. To tune the hyperparameters of an algorithm and improve its accuracy, you'll get hands-on with approaches such as grid search and random search.
Finally, you'll learn dimensionality reduction techniques to easily handle many variables at once, before exploring how to use model ensembling techniques and create new features to enhance model performance.
By the end of this book, you'll have the skills to start working on data science projects confidently.
Audience
This is one of the most useful data science books for aspiring data analysts, data scientists, database engineers, and business analysts. It is aimed at those who want to kick-start their careers in data science by quickly learning data science techniques without going through all the mathematics behind machine learning algorithms. Basic knowledge of the Python programming language will help you easily grasp the concepts explained in this book.
About the Chapters
Chapter 1, Introduction to Data Science in Python, will introduce you to the field of data science and walk you through an overview of Python's core concepts and their application in the world of data science.
Chapter 2, Regression, will acquaint you with linear regression analysis and its application to practical problem solving in data science.
Chapter 3, Binary Classification, will teach you a supervised learning technique called classification to generate business outcomes.
Chapter 4, Multiclass Classification with RandomForest, will show you how to train a multiclass classifier using the Random Forest algorithm.
Chapter 5, Performing Your First Cluster Analysis, will introduce you to unsupervised learning tasks, where algorithms have to automatically learn patterns from data by themselves as no target variables are defined beforehand.
Chapter 6, How to Assess Performance, will teach you to evaluate a model and assess its performance before you decide to put it into production.
Chapter 7, The Generalization of Machine Learning Models, will teach you how to make best use of your data to train better models, by either splitting the data or making use of cross-validation.
Chapter 8, Hyperparameter Tuning, will guide you to find further predictive performance improvements via the systematic evaluation of estimators with different hyperparameters.
Chapter 9, Interpreting a Machine Learning Model, will show you how to interpret a machine learning model's results and get deeper insights into the patterns it found.
Chapter 10, Analyzing a Dataset, will introduce you to the art of performing exploratory data analysis and visualizing the data in order to identify quality issues, potential data transformations, and interesting patterns.
Chapter 11, Data Preparation, will present the main techniques you can use to handle data issues in order to ensure your data is of a high enough quality for successful modeling.
Chapter 12, Feature Engineering, will teach you some of the key techniques for creating new variables on an existing dataset.
Chapter 13, Imbalanced Datasets, will equip you to identify use cases where datasets are likely to be imbalanced, and formulate strategies for dealing with imbalanced datasets.
Chapter 14, Dimensionality Reduction, will show how to analyze datasets with high dimensions and deal with the challenges posed by these datasets.
Chapter 15, Ensemble Learning, will teach you to apply different ensemble learning techniques to your dataset.
Note
There are also three bonus chapters, Chapter 16, Machine Learning Pipelines, Chapter 17, Automated Feature Engineering, and Chapter 18, Model as a Service with Flask, which you can find at http://packt.live/2ZagB9y.
Conventions
Code words in text, database table names, folder names, filenames, file extensions, path names, dummy URLs, user input, and Twitter handles are shown as follows:
"sklearn has a class called train_test_split, which provides the functionality for splitting data."
Words that you see on the screen, for example, in menus or dialog boxes, also appear in the same format.
A block of code is set as follows:
import pandas as pd from sklearn.model_selection import train_test_split
New terms and important words are shown like this:
"A dictionary contains multiple elements, like a list, but each element is organized as a key-value pair."
Code Presentation
Lines of code that span multiple lines are split using a backslash ( \ ). When the code is executed, Python will ignore the backslash, and treat the code on the next line as a direct continuation of the current line.
For example:
history = model.fit(X, y, epochs=100, batch_size=5, verbose=1, \ validation_split=0.2, shuffle=False)
Comments are added into code to help explain specific bits of logic. Single-line comments are denoted using the # symbol, as follows:
# Print the sizes of the datasets
print("Number of Examples in the Dataset = ", X.shape[0])
print("Number of Features for each example = ", X.shape[1])
Multi-line comments are enclosed by triple quotes, as shown below:
""" Define a seed for the random number generator to ensure the result will be reproducible """ seed = 1 np.random.seed(seed) random.set_seed(seed)
Setting up Your Environment
Before we explore the book in detail, we need to set up specific software and tools. In the following section, we shall see how to do that.
How to Set Up Google Colab
There are many integrated development environments (IDE) for Python. The most popular one for running data science projects is Jupyter Notebook from Anaconda but this is not the one we are recommending for this book. As you are starting your journey into data science, rather than asking you to setup a Python environment from scratch, we think it is better for you to use a plug-and-play solution so that you can fully focus on learning the concepts we are presenting in this book. We want to remove as many difficulties as we can and ensure your first step into data science is as straightforward as possible.
Luckily such a tool does exist, and it is called Google Colab. It is a free tool provided by Google that is run on the cloud, so you don't need to buy a new laptop or computer or upgrade its specs. The other benefit of using Colab is most of the Python packages we are using in this book are already installed so you can use them straight away. The only thing you need is a Google account. If you don't have one, you can create one here: https://packt.live/37mea5X.
Then, you will need to subscribe to the Colab service:
- First, log into Google Drive: https://packt.live/2TM1v8w
- Then, go to the following url: https://packt.live/2NKaAuP
You should see the following screen:

Figure 0.1: Google Colab Introduction page
- Then, you can click on
NEW PYTHON 3 NOTEBOOKand you should see a new Colab notebook
Figure 0.2: New Colab notebook
You just added Google Colab to your Google account and now you are ready to write and execute your own Python code.
How to Use Google Colab
Now that you have added Google Colab to your account, let's see how to use it. Google Colab is very similar to Jupyter Notebook. It is actually based on Jupyter, but run on Google servers with additional integrations with their services such as Google Drive.
To open a new Colab notebook, you need to login into your Google Drive account and then click on + New icon:

Figure 0.3: Option to open new notebook
On the menu displayed, select More and then Google Colaboratory
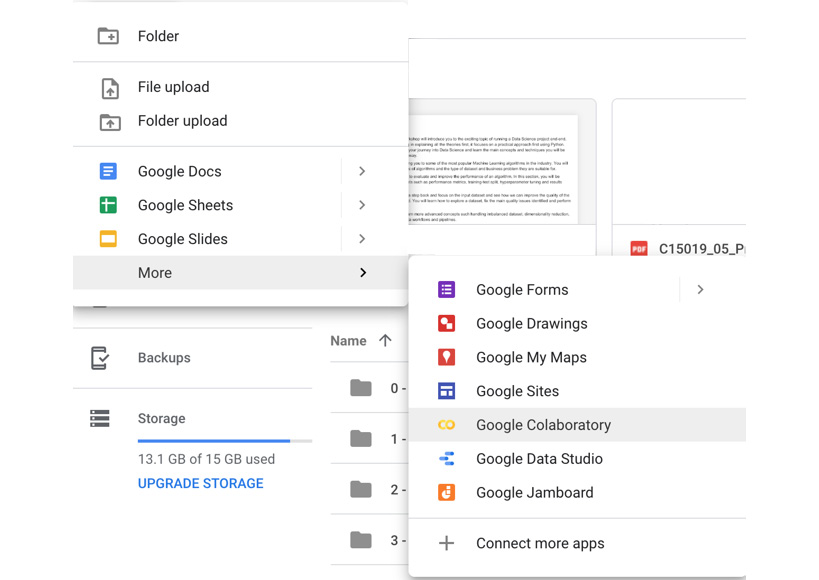
Figure 0.4: Option to open Colab notebook from Google Drive
A new Colab notebook will be created.
Figure 0.5: New Colab notebook
A Colab notebook is an interactive IDE where you can run Python code or add text using cells. A cell is a container where you will add your lines of code or any text information related to your project. In each cell, you can put as many lines of code or text as you want. A cell can display the output of your code after running it, so it is a very powerful way of testing and checking the results of your work. It is a good practice to not overload each cell with tons of code. Try to split it into multiple cells so you will be able to run them independently and check step by step if your code is working.
Let us now see how we can write some Python code in a cell and run it. A cell is composed of 4 main parts:
- The text box where you will write your code
- The
Runbutton for running your code - The options menu that will provide additional functionalities
- The output display

Figure 0.6: Parts of the Colab notebook cell
In this preceding example, we just wrote a simple line of code that adds 2 to 3. Now, we either need to click on the Run button or use the shortcut Ctrl + Enter to run the code. The result will then be displayed below the cell. If your code breaks (when there is an error), the error message will be displayed below the cell:
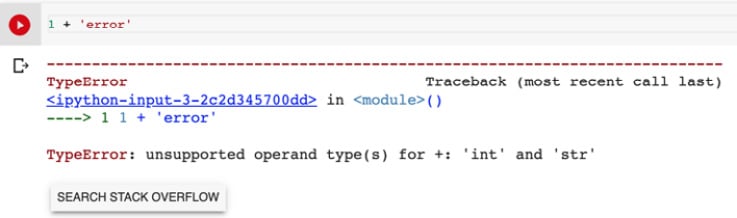
Figure 0.7: Error message on Google Colab
As you can see, we tried to add an integer to a string which is not possible as their data types are not compatible and this is exactly what this error message is telling us.
To add a new cell, you just need to click on either + Code or + Text on the option bar at the top:

Figure 0.8: New cell button
If you add a new Text cell, you have access to specific options for editing your text such as bold, italic, and hypertext links and so on:

Figure 0.9: Different options on cell
This type of cell is actually Markdown compatible. So, you can easily create a title, sub-title, bullet points and so on. Here is a link for learning more about the Markdown options: https://packt.live/2NVgVDT.
With the cell option menu, you can delete a cell or move it up or down in the notebook:

Figure 0.10: Cell options
If you need to install a specific Python package that is not available in Google Colab, you just need to run a cell with the following syntax:
!pip install <package_name>
Note
The '!' is a magic command to run shell commands.

Figure 0.11: Using "!" command
You just learnt the main functionalities provided by Google Colab for running Python code. There are many more functionalities available, but you now know enough for going through the contents of this book.
Accessing the Code Files
You can find the complete code files of this book at https://packt.live/2ucwsId. You can also run many activities and exercises directly in your web browser by using the interactive lab environment at https://packt.live/3gfsH76.
We've tried to support interactive versions of all activities and exercises, but we recommend executing the code on Google Colab as well for instances where this support isn't available.
The high-quality color images used in book can be found at https://packt.live/30O91Bd.
If you have any issues or questions about installation, please email us at workshops@packt.com.



