






















































At first, computation in TensorFlow may seem needlessly complicated. But there is a reason for it: because of how TensorFlow treats computation, developing more complicated algorithms is relatively easy. This recipe will guide us through the pseudocode of a TensorFlow algorithm.
How TensorFlow works
Getting ready
Currently, TensorFlow is supported on Linux, macOS, and Windows. The code for this book has been created and run on a Linux system, but should run on any other system as well. The code for the book is available on GitHub at https://github.com/nfmcclure/tensorflow_cookbook as well as the Packt repository: https://github.com/PacktPublishing/TensorFlow-Machine-Learning-Cookbook-Second-Edition.
Throughout this book, we will only concern ourselves with the Python library wrapper of TensorFlow, although most of the original core code for TensorFlow is written in C++. This book will use Python 3.6+ (https://www.python.org) and TensorFlow 1.10.0+ (https://www.tensorflow.org). While TensorFlow can run on the CPU, most algorithms run faster if processed on the GPU, and it is supported on graphics cards with Nvidia Compute Capability v4.0+ (v5.1 recommended).
Popular GPUs for TensorFlow are Nvidia Tesla architectures and Pascal architectures with at least 4 GB of video RAM. To run on a GPU, you will also need to download and install the Nvidia CUDA toolkit as well as version 5.x+ (https://developer.nvidia.com/cuda-downloads).
Some of the recipes in this chapter will rely on a current installation of the SciPy, NumPy, and scikit-learn Python packages. These accompanying packages are also included in the Anaconda package (https://www.continuum.io/downloads).
How to do it...
Here, we will introduce the general flow of TensorFlow algorithms. Most recipes will follow this outline:
- Import or generate dataset: All of our machine learning algorithms will depend on datasets. In this book, we will either generate data or use an outside source of datasets. Sometimes, it is better to rely on generated data because we just want to know the expected outcome. Most of the time, we will access public datasets for the given recipe. The details on accessing these datasets are in additional resources, section 8 of this chapter.
- Transform and normalize data: Normally, input datasets do not come into the picture. TensorFlow expects that we need to transform TensorFlow so that they get the accepted shape. The data is usually not in the correct dimension or type that our algorithms expect. We will have to transform our data before we can use it. Most algorithms also expect normalized data and we will look at this here as well. TensorFlow has built-in functions that can normalize data for you, as follows:
import tensorflow as tf
data = tf.nn.batch_norm_with_global_normalization(...)
- Partition the dataset into train, test, and validation sets: We generally want to test our algorithms on different sets that we have trained on. Also, many algorithms require hyperparameter tuning, so we set aside a validation set for determining the best set of hyperparameters.
- Set algorithm parameters (hyperparameters): Our algorithms usually have a set of parameters that we hold constant throughout the procedure. For example, this can be the number of iterations, the learning rate, or other fixed parameters of our choosing. It is considered good practice to initialize these together so that the reader or user can easily find them, as follows:
learning_rate = 0.01 batch_size = 100 iterations = 1000
- Initialize variables and placeholders: TensorFlow depends on knowing what it can and cannot modify. TensorFlow will modify/adjust the variables (model weights/biases) during optimization to minimize a loss function. To accomplish this, we feed in data through placeholders. We need to initialize both variables and placeholders with size and type so that TensorFlow knows what to expect. TensorFlow also needs to know the type of data to expect. For most of this book, we will use float32. TensorFlow also provides float64 and float16. Note that more bytes used for precision results in slower algorithms, but less used results in less precision. See the following code:
a_var = tf.constant(42) x_input = tf.placeholder(tf.float32, [None, input_size]) y_input = tf.placeholder(tf.float32, [None, num_classes])
- Define the model structure: After we have the data, and have initialized our variables and placeholders, we have to define the model. This is done by building a computational graph. We will talk more in depth about computational graphs in the Operations in a Computational Graph TensorFlow recipe in Chapter 2, The TensorFlow Way. The model for this example will be a linear model (
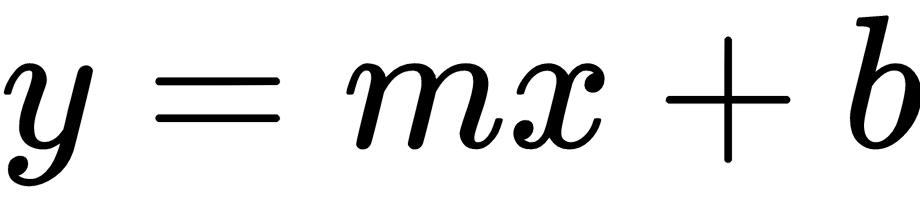 ):
):
y_pred = tf.add(tf.mul(x_input, weight_matrix), b_matrix)
- Declare the loss functions: After defining the model, we must be able to evaluate the output. This is where we declare the loss function. The loss function is very important as it tells us how far off our predictions are from the actual values. The different types of loss functions are explored in greater detail in the Implementing Back Propagation recipe in Chapter 2, The TensorFlow Way. Here, we implement the mean squared error for n-points, that is,
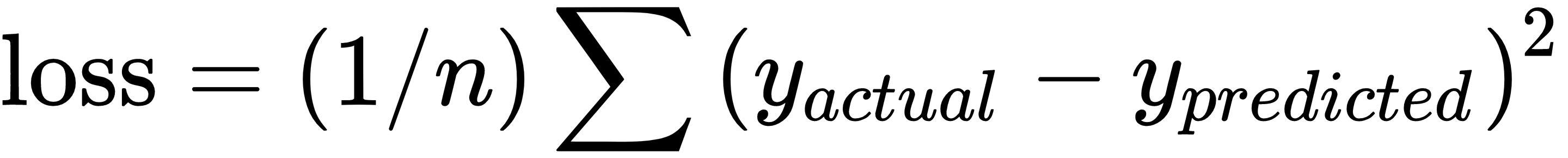 :
:
loss = tf.reduce_mean(tf.square(y_actual - y_pred))
- Initialize and train the model: Now that we have everything in place, we need to create an instance of our graph, feed in the data through the placeholders, and let TensorFlow change the variables to better predict our training data. Here is one way to initialize the computational graph:
with tf.Session(graph=graph) as session: ... session.run(...) ...
Note that we can also initiate our graph with:
session = tf.Session(graph=graph) session.run(...)
- Evaluate the model: Once we have built and trained the model, we should evaluate the model by looking at how well it does with new data through some specified criteria. We evaluate on the train and test set and these evaluations will allow us to see if the model is under overfitting. We will address this in later recipes.
- Tune hyperparameters: Most of the time, we will want to go back and change some of the hyperparameters based on the model's performance. We then repeat the previous steps with different hyperparameters and evaluate the model on the validation set.
- Deploy/predict new outcomes: It is also important to know how to make predictions on new and unseen data. We can do this with all of our models once we have them trained.
How it works...
In TensorFlow, we have to set up the data, variables, placeholders, and model before we can tell the program to train and change the variables to improve predictions. TensorFlow accomplishes this through computational graphs. These computational graphs are directed graphs with no recursion, which allows for computational parallelism. To do this, we need to create a loss function for TensorFlow to minimize. TensorFlow accomplishes this by modifying the variables in the computational graph. TensorFlow knows how to modify the variables because it keeps track of the computations in the model and automatically computes the variable gradients (how to change each variable) to minimize the loss. Because of this, we can see how easy it can be to make changes and try different data sources.
See also
For more TensorFlow introduction and resources, see the official documentation and tutorials as well:
- A better place to start is the official Python API documentation: https://www.tensorflow.org/api_docs/python/
- There are also tutorials available: https://www.tensorflow.org/tutorials/
- An unofficial collection of TensorFlow tutorials, projects, presentations, and code repositories: https://github.com/jtoy/awesome-tensorflow






















