






















































Deploying a Kubernetes application
Deploying an application on Kubernetes is fundamentally similar to deploying an application outside of Kubernetes. All applications, whether containerized or not, must have configuration details around topics that include the following:
- Networking
- Persistent storage and file mounts
- Availability and redundancy
- Application configuration
- Security
Configuring these details on Kubernetes is done by interacting with the Kubernetes application programming interface (API).
The Kubernetes API serves as a set of endpoints that can be interacted with to view, modify, or delete different Kubernetes resources, many of which are used to configure different details of an application.
Let's discuss some of the basic API endpoints users can interact with to deploy and configure an application on Kubernetes.
Deployment
The first Kubernetes resource we will explore is called a Deployment. Deployments determine the basic details required to deploy an application on Kubernetes. One of these basic details consists of the container image that Kubernetes should deploy. Container images can be built on local workstations using tools such as docker, and jib but images can also be built right on Kubernetes using kaniko. Because Kubernetes does not expose a native API endpoint for building container images, we will not go into detail about how a container image is built prior to configuring a Deployment resource.
In addition to specifying the container image, Deployments also specify the number of replicas, or instances, of an application to deploy. When a Deployment is created, it spawns an intermediate resource, called a ReplicaSet. The ReplicaSet deploys as many instances of the application as determined by the replicas field on the Deployment. The application is deployed inside a container, which itself is deployed inside a construct called a Pod. A Pod is the smallest unit in Kubernetes and encapsulates at least one container.
Deployments can additionally define an application's resource limits, health checks, and volume mounts. When a Deployment is created, Kubernetes creates the following architecture:

Figure 1.2 - A Deployment creates a set of Pods
Another basic API endpoint in Kubernetes is used to create Service resources, which we will discuss next.
Services
While Deployments are used to deploy an application to Kubernetes, they do not configure the networking components that allow an application to be communicated with Kubernetes exposes a separate API endpoint used to define the networking layer, called a Service. Services allow users and other applications to talk to each other by allocating a static IP address to a Service endpoint. The Service endpoint can then be configured to route traffic to one or more application instances. This kind of configuration provides load balancing and high availability.
An example architecture using a Service is described in the following diagram. Notice that the Service sits in between the client and the Pods to provide load balancing and high availability:
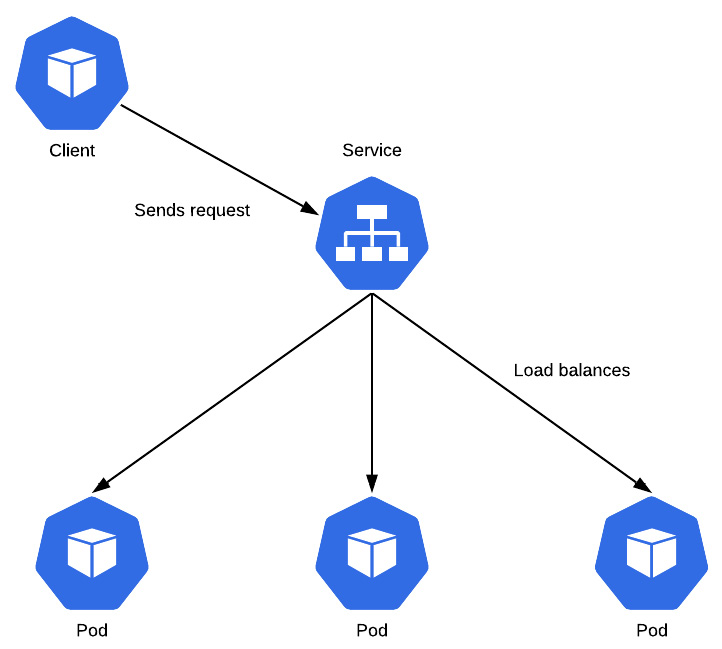
Figure 1.3 - A Service load balancing an incoming request
As a final example, we will discuss the PersistentVolumeClaim API endpoint.
PersistentVolumeClaim
Microservice-style applications embrace being self-sufficient by maintaining their state in an ephemeral manner. However, there are numerous use cases where data must live beyond the life span of a single container. Kubernetes addresses this issue by providing a subsystem for abstracting the underlying details of how storage is provided and how it is consumed. To allocate persistent storage for their application, users can create a PersistentVolumeClaim endpoint, which specifies the type and amount of storage that is desired. Kubernetes administrators are responsible for either statically allocating storage, expressed as PersistentVolume, or dynamically provisioning storage using StorageClass, which allocates PersistentVolume in response to a PersistentVolumeClaim endpoint. PersistentVolume captures all of the necessary storage details, including the type (such as network file system [NFS], internet small computer systems interface [iSCSI], or from a cloud provider), along with the size of the storage. From a user's perspective, regardless of which method of the PersistentVolume allocation method or storage backend that is used within the cluster, they do not need to manage the underlying details of managing storage. The ability to leverage persistent storage within Kubernetes increases the number of potential applications that can be deployed on the platform.
An example of persistent storage being provisioned is depicted in the following diagram. The diagram assumes that an administrator has configured dynamic provisioning via StorageClass:
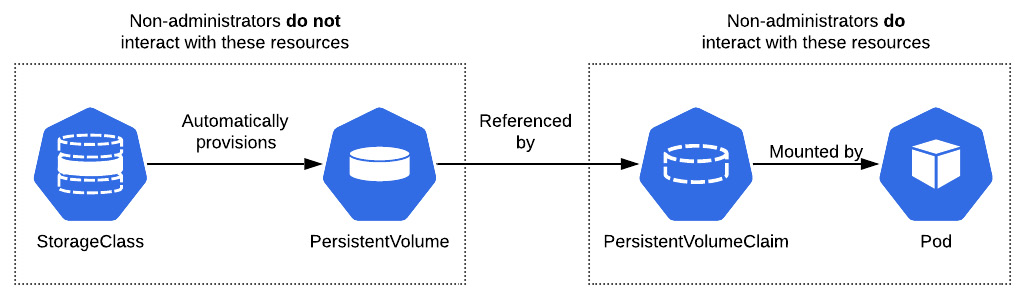
Figure 1.4 - A Pod mounting PersistentVolume created by PersistentVolumeClaim
There are many more resources in Kubernetes, but by now, you have probably got the picture. The question now is how are these resources actually created?
We will explore this question further in the next section.






















