























































The following sections describe solutions to the preceding problems. Remember that there usually isn't a single correct way to solve a particular problem. Also, remember that the explanations shown here only include the most interesting and important details needed to solve the problems. You can download the example solutions to see additional details and experiment with the programs from https://github.com/PacktPublishing/Java-Coding-Problems.
Solutions
1. Counting duplicate characters
The solution to counting the characters in a string (including special characters such as #, $, and %) implies taking each character and comparing them with the rest. During the comparison, the counting state is maintained via a numeric counter that's increased by one each time the current character is found.
There are two solutions to this problem.
The first solution iterates the string characters and uses Map to store the characters as keys and the number of occurrences as values. If the current character was never added to Map, then add it as (character, 1). If the current character exists in Map, then simply increase its occurrences by 1, for example, (character, occurrences+1). This is shown in the following code:
public Map<Character, Integer> countDuplicateCharacters(String str) {
Map<Character, Integer> result = new HashMap<>();
// or use for(char ch: str.toCharArray()) { ... }
for (int i = 0; i<str.length(); i++) {
char ch = str.charAt(i);
result.compute(ch, (k, v) -> (v == null) ? 1 : ++v);
}
return result;
}
Another solution relies on Java 8's stream feature. This solution has three steps. The first two steps are meant to transform the given string into Stream<Character>, while the last step is responsible for grouping and counting the characters. Here are the steps:
- Call the String.chars() method on the original string. This will return IntStream. This IntStream contains an integer representation of the characters from the given string.
- Transform IntStream into a stream of characters via the mapToObj() method (convert the integer representation into the human-friendly character form).
- Finally, group the characters (Collectors.groupingBy()) and count them (Collectors.counting()).
The following snippet of code glues these three steps into a single method:
public Map<Character, Long> countDuplicateCharacters(String str) {
Map<Character, Long> result = str.chars()
.mapToObj(c -> (char) c)
.collect(Collectors.groupingBy(c -> c, Collectors.counting()));
return result;
}
What about Unicode characters?
We are pretty familiar with ASCII characters. We have unprintable control codes between 0-31, printable characters between 32-127, and extended ASCII codes between 128-255. But what about Unicode characters? Consider this section for each problem that requires that we manipulate Unicode characters.
So, in a nutshell, early Unicode versions contained characters with values less than 65,535 (0xFFFF). Java represents these characters using the 16-bit char data type. Calling charAt(i) works as expected as long as i doesn't exceed 65,535. But over time, Unicode has added more characters and the maximum value has reached 1,114,111 (0x10FFFF). These characters don't fit into 16 bits, and so 32-bit values (known as code points) were considered for the UTF-32 encoding scheme.
Unfortunately, Java doesn't support UTF-32! Nevertheless, Unicode has come up with a solution for still using 16 bits to represent these characters. This solution implies the following:
- 16-bit high surrogates: 1,024 values (U+D800 to U+DBFF)
- 16-bit low surrogates: 1,024 values (U+DC00 to U+DFFF)
Now, a high surrogate followed by a low surrogate defines what is known as a surrogate pair. Surrogate pairs are used to represent values between 65,536 (0x10000) and 1,114,111 (0x10FFFF). So, certain characters, known as Unicode supplementary characters, are represented as Unicode surrogate pairs (a one-character (symbol) fits in the space of a pair of characters) that are merged into a single code point. Java takes advantage of this representation and exposes it via a suite of methods such as codePointAt(), codePoints(), codePointCount(), and offsetByCodePoints() (take a look at the Java documentation for details). Calling codePointAt() instead of charAt(), codePoints() instead of chars(), and so on helps us to write solutions that cover ASCII and Unicode characters as well.
For example, the well-known two hearts symbol is a Unicode surrogate pair that can be represented as a char[] containing two values: \uD83D and \uDC95. The code point of this symbol is 128149. To obtain a String object from this code point, call String str = String.valueOf(Character.toChars(128149)). Counting the code points in str can be done by calling str.codePointCount(0, str.length()), which returns 1 even if the str length is 2. Calling str.codePointAt(0) returns 128149 and calling str.codePointAt(1) returns 56469. Calling Character.toChars(128149) returns 2 since two characters are needed to represent this code point being a Unicode surrogate pair. For ASCII and Unicode 16- bit characters, it will return 1.
So, if we try to rewrite the first solution (that iterates the string characters and uses Map to store the characters as keys and the number of occurrences as values) to support ASCII and Unicode (including surrogate pairs), we obtain the following code:
public static Map<String, Integer>
countDuplicateCharacters(String str) {
Map<String, Integer> result = new HashMap<>();
for (int i = 0; i < str.length(); i++) {
int cp = str.codePointAt(i);
String ch = String.valueOf(Character.toChars(cp));
if(Character.charCount(cp) == 2) { // 2 means a surrogate pair
i++;
}
result.compute(ch, (k, v) -> (v == null) ? 1 : ++v);
}
return result;
}
The highlighted code can be written as follows, as well:
String ch = String.valueOf(Character.toChars(str.codePointAt(i)));
if (i < str.length() - 1 && str.codePointCount(i, i + 2) == 1) {
i++;
}
Finally, trying to rewrite the Java 8 functional style solution to cover Unicode surrogate pairs can be done as follows:
public static Map<String, Long> countDuplicateCharacters(String str) {
Map<String, Long> result = str.codePoints()
.mapToObj(c -> String.valueOf(Character.toChars(c)))
.collect(Collectors.groupingBy(c -> c, Collectors.counting()));
return result;
}
For third-party library support, please consider Guava: Multiset<String>.
Some of the following problems will provide solutions that cover ASCII, 16-bit Unicode, and Unicode surrogate pairs as well. They have been chosen arbitrarily, and so, by relying on these solutions, you can easily write solutions for problems that don't provide such a solution.
2. Finding the first non-repeated character
There are different solutions to finding the first non-repeated character in a string. Mainly, the problem can be solved in a single traversal of the string or in more complete/partial traversals.
In the single traversal approach, we populate an array that's meant to store the indexes of all of the characters that appear exactly once in the string. With this array, simply return the smallest index containing a non-repeated character:
private static final int EXTENDED_ASCII_CODES = 256;
...
public char firstNonRepeatedCharacter(String str) {
int[] flags = new int[EXTENDED_ASCII_CODES];
for (int i = 0; i < flags.length; i++) {
flags[i] = -1;
}
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
if (flags[ch] == -1) {
flags[ch] = i;
} else {
flags[ch] = -2;
}
}
int position = Integer.MAX_VALUE;
for (int i = 0; i < EXTENDED_ASCII_CODES; i++) {
if (flags[i] >= 0) {
position = Math.min(position, flags[i]);
}
}
return position == Integer.MAX_VALUE ?
Character.MIN_VALUE : str.charAt(position);
}
This solution assumes that every character from the string is part of the extended ASCII table (256 codes). Having codes greater than 256 requires us to increase the size of the array accordingly (http://www.alansofficespace.com/unicode/unicd99.htm). The solution will work as long as the array size is not extended beyond the largest value of the char type, which is Character.MAX_VALUE, that is, 65,535. On the other hand, Character.MAX_CODE_POINT returns the maximum value of a Unicode code point, 1,114,111. To cover this range, we need another implementation based on codePointAt() and codePoints().
Thanks to the single traversal approach, this is pretty fast. Another solution consists of looping the string for each character and counting the number of occurrences. Every second occurrence (duplicate) simply breaks the loop, jumps to the next character, and repeats the algorithm. If the end of the string is reached, then it returns the current character as the first non-repeatable character. This solution is available in the code bundled with this book.
Another solution that's presented here relies on LinkedHashMap. This Java map is an insertion-order map (it maintains the order in which the keys were inserted into the map) and is very convenient for this solution. LinkedHashMap is populated with characters as keys and the number of occurrences as values. Once LinkedHashMap is complete, it will return the first key that has a value equal to 1. Thanks to the insertion-order feature, this is the first non-repeatable character in the string:
public char firstNonRepeatedCharacter(String str) {
Map<Character, Integer> chars = new LinkedHashMap<>();
// or use for(char ch: str.toCharArray()) { ... }
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
chars.compute(ch, (k, v) -> (v == null) ? 1 : ++v);
}
for (Map.Entry<Character, Integer> entry: chars.entrySet()) {
if (entry.getValue() == 1) {
return entry.getKey();
}
}
return Character.MIN_VALUE;
}
In the code bundled with this book, the aforementioned solution has been written in Java 8 functional style. Moreover, the functional style solution for supporting ASCII, 16-bit Unicode, and Unicode surrogate pairs is as follows:
public static String firstNonRepeatedCharacter(String str) {
Map<Integer, Long> chs = str.codePoints()
.mapToObj(cp -> cp)
.collect(Collectors.groupingBy(Function.identity(),
LinkedHashMap::new, Collectors.counting()));
int cp = chs.entrySet().stream()
.filter(e -> e.getValue() == 1L)
.findFirst()
.map(Map.Entry::getKey)
.orElse(Integer.valueOf(Character.MIN_VALUE));
return String.valueOf(Character.toChars(cp));
}
To understand this code in more detail, please consider the What about Unicode characters? subsection of the Counting duplicate characters section.
3. Reversing letters and words
First, let's reverse only the letters of each word. The solution to this problem can exploit the StringBuilder class. The first step consists of splitting the string into an array of words using a white space as the delimiter (Spring.split(" ")). Furthermore, we reverse each word using the corresponding ASCII codes and append the result to StringBuilder. First, we split the given string by space. Then, we loop the obtained array of words and reverse each word by fetching each character via charAt() in reverse order:
private static final String WHITESPACE = " ";
...
public String reverseWords(String str) {
String[] words = str.split(WHITESPACE);
StringBuilder reversedString = new StringBuilder();
for (String word: words) {
StringBuilder reverseWord = new StringBuilder();
for (int i = word.length() - 1; i >= 0; i--) {
reverseWord.append(word.charAt(i));
}
reversedString.append(reverseWord).append(WHITESPACE);
}
return reversedString.toString();
}
Obtaining the same result in Java 8 functional style can be done as follows:
private static final Pattern PATTERN = Pattern.compile(" +");
...
public static String reverseWords(String str) {
return PATTERN.splitAsStream(str)
.map(w -> new StringBuilder(w).reverse())
.collect(Collectors.joining(" "));
}
Notice that the preceding two methods return a string containing the letters of each word reversed, but the words themselves are in the same initial order. Now, let's consider another method that reverses the letters of each word and the words themselves. Thanks to the built-in StringBuilder.reverse() method, this is very easy to accomplish:
public String reverse(String str) {
return new StringBuilder(str).reverse().toString();
}
For third-party library support, please consider the Apache Commons Lang, StringUtils.reverse().
4. Checking whether a string contains only digits
The solution to this problem relies on the Character.isDigit() or String.matches() method.
The solution relying on Character.isDigit() is pretty simple and fast—loop the string characters and break the loop if this method returns false:
public static boolean containsOnlyDigits(String str) {
for (int i = 0; i < str.length(); i++) {
if (!Character.isDigit(str.charAt(i))) {
return false;
}
}
return true;
}
In Java 8 functional style, the preceding code can be rewritten using anyMatch():
public static boolean containsOnlyDigits(String str) {
return !str.chars()
.anyMatch(n -> !Character.isDigit(n));
}
Another solution relies on String.matches(). This method returns a boolean value indicating whether or not this string matches the given regular expression:
public static boolean containsOnlyDigits(String str) {
return str.matches("[0-9]+");
}
Notice that Java 8 functional style and regular expression-based solutions are usually slow, so if speed is a requirement, then it's better to rely on the first solution using Character.isDigit().
Avoid solving this problem via parseInt() or parseLong(). First of all, it's bad practice to catch NumberFormatException and take business logic decisions in the catch block. Second, these methods verify whether the string is a valid number, not whether it contains only digits (for example, -4 is valid).
For third-party library support, please consider the Apache Commons Lang, StringUtils.isNumeric().
For third-party library support, please consider the Apache Commons Lang, StringUtils.isNumeric().
5. Counting vowels and consonants
The following code is for English, but depending on how many languages you are covering, the number of vowels and consonants may differ and the code should be adjusted accordingly.
The first solution to this problem requires traversing the string characters and doing the following:
- We need to check whether the current character is a vowel (this is convenient since we only have five pure vowels in English; other languages have more vowels, but the number is still small).
- If the current character is not a vowel, then check whether it sits between 'a' and 'z' (this means that the current character is a consonant).
Notice that, initially, the given String object is transformed into lowercase. This is useful to avoid comparisons with uppercase characters. For example, the comparison is accomplished only against 'a' instead of 'A' and 'a'.
The code for this solution is as follows:
private static final Set<Character> allVowels
= new HashSet(Arrays.asList('a', 'e', 'i', 'o', 'u'));
public static Pair<Integer, Integer>
countVowelsAndConsonants(String str) {
str = str.toLowerCase();
int vowels = 0;
int consonants = 0;
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
if (allVowels.contains(ch)) {
vowels++;
} else if ((ch >= 'a' && ch <= 'z')) {
consonants++;
}
}
return Pair.of(vowels, consonants);
}
In Java 8 functional style, this code can be rewritten using chars() and filter():
private static final Set<Character> allVowels
= new HashSet(Arrays.asList('a', 'e', 'i', 'o', 'u'));
public static Pair<Long, Long> countVowelsAndConsonants(String str) {
str = str.toLowerCase();
long vowels = str.chars()
.filter(c -> allVowels.contains((char) c))
.count();
long consonants = str.chars()
.filter(c -> !allVowels.contains((char) c))
.filter(ch -> (ch >= 'a' && ch<= 'z'))
.count();
return Pair.of(vowels, consonants);
}
The given string is filtered accordingly and the count() terminal operation returns the result. Relying on partitioningBy() will reduce the code, as follows:
Map<Boolean, Long> result = str.chars()
.mapToObj(c -> (char) c)
.filter(ch -> (ch >= 'a' && ch <= 'z'))
.collect(partitioningBy(c -> allVowels.contains(c), counting()));
return Pair.of(result.get(true), result.get(false));
Done! Now, let's see how we can count occurrences of a certain character in a string.
6. Counting the occurrences of a certain character
A simple solution to this problem consists of the following two steps:
- Replace every occurrence of the character in the given string with "" (basically, this is like removing all of the occurrences of this character in the given string).
- Subtract the length of the string that was obtained in the first step from the length of the initial string.
The code for this method is as follows:
public static int countOccurrencesOfACertainCharacter(
String str, char ch) {
return str.length() - str.replace(String.valueOf(ch), "").length();
}
The following solution covers Unicode surrogate pairs as well:
public static int countOccurrencesOfACertainCharacter(
String str, String ch) {
if (ch.codePointCount(0, ch.length()) > 1) {
// there is more than 1 Unicode character in the given String
return -1;
}
int result = str.length() - str.replace(ch, "").length();
// if ch.length() return 2 then this is a Unicode surrogate pair
return ch.length() == 2 ? result / 2 : result;
}
Another easy to implement and fast solution consists of looping the string characters (a single traversal) and comparing each character with the given character. Increase the counter by one for every match:
public static int countOccurrencesOfACertainCharacter(
String str, char ch) {
int count = 0;
for (int i = 0; i < str.length(); i++) {
if (str.charAt(i) == ch) {
count++;
}
}
return count;
}
The solution that covers the Unicode surrogate pairs is in the code that's bundled with this book. In Java 8 functional style, one solution consists of using filter() or reduce(). For example, using filter() will result in the following code:
public static long countOccurrencesOfACertainCharacter(
String str, char ch) {
return str.chars()
.filter(c -> c == ch)
.count();
}
The solution that covers the Unicode surrogate pairs is in the code that's bundled with this book.
For third-party library support, please consider Apache Commons Lang, StringUtils.countMatches(), Spring Framework, StringUtils.countOccurrencesOf(), and Guava, CharMatcher.is().countIn().
7. Converting a string into an int, long, float, or double
Let's consider the following strings (negatives can be used as well):
private static final String TO_INT = "453";
private static final String TO_LONG = "45234223233";
private static final String TO_FLOAT = "45.823F";
private static final String TO_DOUBLE = "13.83423D";
A proper solution for converting String into int, long, float, or double consists of using the following Java methods of the Integer, Long, Float, and Double classes—parseInt(), parseLong(), parseFloat(), and parseDouble():
int toInt = Integer.parseInt(TO_INT);
long toLong = Long.parseLong(TO_LONG);
float toFloat = Float.parseFloat(TO_FLOAT);
double toDouble = Double.parseDouble(TO_DOUBLE);
Converting String into an Integer, Long, Float, or Double object can be accomplished via the following Java methods—Integer.valueOf(), Long.valueOf(), Float.valueOf(), and Double.valueOf():
Integer toInt = Integer.valueOf(TO_INT);
Long toLong = Long.valueOf(TO_LONG);
Float toFloat = Float.valueOf(TO_FLOAT);
Double toDouble = Double.valueOf(TO_DOUBLE);
When a String cannot be converted successfully, Java throws a NumberFormatException exception. The following code speaks for itself:
private static final String WRONG_NUMBER = "452w";
try {
Integer toIntWrong1 = Integer.valueOf(WRONG_NUMBER);
} catch (NumberFormatException e) {
System.err.println(e);
// handle exception
}
try {
int toIntWrong2 = Integer.parseInt(WRONG_NUMBER);
} catch (NumberFormatException e) {
System.err.println(e);
// handle exception
}
For third-party library support, please consider Apache Commons BeanUtils: IntegerConverter, LongConverter, FloatConverter, and DoubleConverter.
8. Removing white spaces from a string
The solution to this problem consists of using the String.replaceAll() method with the \s regular expression. Mainly, \s removes all white spaces, including the non-visible ones, such as \t, \n, and \r:
public static String removeWhitespaces(String str) {
return str.replaceAll("\\s", "");
}
Starting with JDK 11, String.isBlank() checks whether the string is empty or contains only white space code points. For third-party library support, please consider Apache Commons Lang, StringUtils.deleteWhitespace(), and the Spring Framework, StringUtils.trimAllWhitespace().
9. Joining multiple strings with a delimiter
There are several solutions that fit well and solve this problem. Before Java 8, a convenient approach relied on StringBuilder, as follows:
public static String joinByDelimiter(char delimiter, String...args) {
StringBuilder result = new StringBuilder();
int i = 0;
for (i = 0; i < args.length - 1; i++) {
result.append(args[i]).append(delimiter);
}
result.append(args[i]);
return result.toString();
}
Starting with Java 8, there are at least three more solutions to this problem. One of these solutions relies on the StringJoiner utility class. This class can be used to construct a sequence of characters separated by a delimiter (for example, a comma).
It supports an optional prefix and suffix as well (ignored here):
public static String joinByDelimiter(char delimiter, String...args) {
StringJoiner joiner = new StringJoiner(String.valueOf(delimiter));
for (String arg: args) {
joiner.add(arg);
}
return joiner.toString();
}
Another solution relies on the String.join() method. This method was introduced in Java 8 and comes in two flavors:
String join(CharSequence delimiter, CharSequence... elems)
String join(CharSequence delimiter,
Iterable<? extends CharSequence> elems)
An example of joining several strings delimited by a space is as follows:
String result = String.join(" ", "how", "are", "you"); // how are you
Going further, Java 8 streams and Collectors.joining() can be useful as well:
public static String joinByDelimiter(char delimiter, String...args) {
return Arrays.stream(args, 0, args.length)
.collect(Collectors.joining(String.valueOf(delimiter)));
}
Pay attention to concatenating strings via the += operator, and the concat() and String.format() methods. These can be used to join several strings, but they are prone to performance penalties. For example, the following code relies on += and is much slower than relying on StringBuilder :
String str = "";
for(int i = 0; i < 1_000_000; i++) {
str += "x";
}
+= is appended to a string and reconstructs a new string, and that costs time.
For third-party library support, please consider Apache Commons Lang, StringUtils.join(), and Guava, Joiner.
String str = "";
for(int i = 0; i < 1_000_000; i++) {
str += "x";
}
+= is appended to a string and reconstructs a new string, and that costs time.
For third-party library support, please consider Apache Commons Lang, StringUtils.join(), and Guava, Joiner.
10. Generating all permutations
Problems that involve permutations commonly involve recursivity as well. Basically, recursivity is defined as a process where some initial state is given and each successive state is defined in terms of the preceding state.
In our case, the state can be materialized by the letters of the given string. The initial state contains the initial string and each successive state can be computed by the following formula—each letter of the string will become the first letter of the string (swap positions) and then permute all of the remaining letters using a recursive call. While non-recursive or other recursive solutions exist, this is a classical solution to this problem.
Representing this solution for a string, ABC, can be done like so (notice how permutations are done):
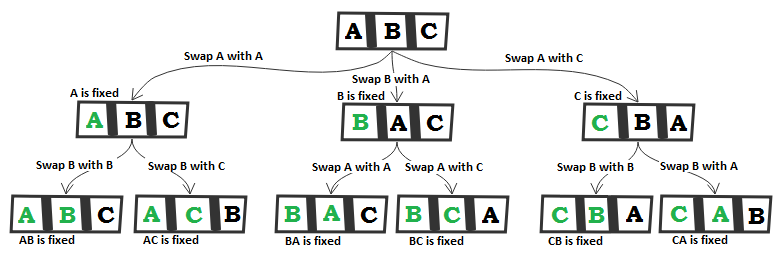
Coding this algorithm will result in something like the following:
public static void permuteAndPrint(String str) {
permuteAndPrint("", str);
}
private static void permuteAndPrint(String prefix, String str) {
int n = str.length();
if (n == 0) {
System.out.print(prefix + " ");
} else {
for (int i = 0; i < n; i++) {
permuteAndPrint(prefix + str.charAt(i),
str.substring(i + 1, n) + str.substring(0, i));
}
}
}
Initially, the prefix should be an empty string, "". At each iteration, the prefix will concatenate (fix) the next letter from the string. The remaining letters are passed through the method again.
Let's suppose that this method lives in a utility class named Strings. You can call it like so:
Strings.permuteAndStore("ABC");
This will produce the following output:
ABC ACB BCA BAC CAB CBA
Notice that this solution prints the result on the screen. Storing the result implies adding Set to the implementation. It is preferable to use Set since it eliminates duplicates:
public static Set<String> permuteAndStore(String str) {
return permuteAndStore("", str);
}
private static Set<String>
permuteAndStore(String prefix, String str) {
Set<String> permutations = new HashSet<>();
int n = str.length();
if (n == 0) {
permutations.add(prefix);
} else {
for (int i = 0; i < n; i++) {
permutations.addAll(permuteAndStore(prefix + str.charAt(i),
str.substring(i + 1, n) + str.substring(0, i)));
}
}
return permutations;
}
For example, if the passed string is TEST, then Set will cause the following output (these are all unique permutations):
ETST SETT TEST TTSE STTE STET TETS TSTE TSET TTES ESTT ETTS
Using List instead of Set will result in the following output (notice the duplicates):
TEST TETS TSTE TSET TTES TTSE ESTT ESTT ETTS ETST ETST ETTS STTE STET STET STTE SETT SETT TTES TTSE TEST TETS TSTE TSET
There are 24 permutations. It is easy to determine the number of resulted permutations by computing the n factorial (n!). For n=4 (length of the string), 4! = 1 x 2 x 3 x 4 = 24. When expressed in recursive style, this is n! = n x (n-1)!.
Since n! results in high numbers extremely fast (example, 10! = 3628800), it is advisable to avoid storing the results. For a 10-character string such as HELICOPTER, there are 3,628,800 permutations!
Trying to implement this solution in Java 8 functional style will result in something like the following:
private static void permuteAndPrintStream(String prefix, String str) {
int n = str.length();
if (n == 0) {
System.out.print(prefix + " ");
} else {
IntStream.range(0, n)
.parallel()
.forEach(i -> permuteAndPrintStream(prefix + str.charAt(i),
str.substring(i + 1, n) + str.substring(0, i)));
}
}
As a bonus, a solution that returns Stream<String> is available in the code bundled with this book.
11. Checking whether a string is a palindrome
Just as a quick reminder, a palindrome (whether a string or a number) looks unchanged when it's reversed. This means that processing (reading) a palindrome can be done from both directions and the same result will be obtained (for example, the word madam is a palindrome, while the word madame is not).
An easy to implement solution consists of comparing the letters of the given string in a meet-in-the-middle approach. Basically, this solution compares the first character with the last one, the second character with the last by one, and so on until the middle of the string is reached. The implementation relies on the while statement:
public static boolean isPalindrome(String str) {
int left = 0;
int right = str.length() - 1;
while (right > left) {
if (str.charAt(left) != str.charAt(right)) {
return false;
}
left++;
right--;
}
return true;
}
Rewriting the preceding solution in a more concise approach will consist of relying on a for statement instead of a while statement, as follows:
public static boolean isPalindrome(String str) {
int n = str.length();
for (int i = 0; i < n / 2; i++) {
if (str.charAt(i) != str.charAt(n - i - 1)) {
return false;
}
}
return true;
}
But can this solution be reduced to a single line of code? The answer is yes.
The Java API provides the StringBuilder class, which uses the reverse() method. As its name suggests, the reverse() method returns the reverse given string. In the case of a palindrome, the given string should be equal to the reverse version of it:
public static boolean isPalindrome(String str) {
return str.equals(new StringBuilder(str).reverse().toString());
}
In Java 8 functional style, there is a single line of code for this as well. Simply define IntStream ranging from 0 to half of the given string and use the noneMatch() short-circuiting terminal operation with a predicate that compares the letters by following the meet-in-the-middle approach:
public static boolean isPalindrome(String str) {
return IntStream.range(0, str.length() / 2)
.noneMatch(p -> str.charAt(p) !=
str.charAt(str.length() - p - 1));
}
Now, let's talk about removing duplicate characters from the given string.
12. Removing duplicate characters
Let's start with a solution to this problem that relies on StringBuilder. Mainly, the solution should loop the characters of the given string and construct a new string containing unique characters (it is not possible to simply remove characters from the given string since, in Java, a string is immutable).
The StringBuilder class exposes a method named indexOf(), which returns the index within the given string of the first occurrence of the specified substring (in our case, the specified character). So, a potential solution to this problem would be to loop the characters of the given string and add them one by one in StringBuilder every time the indexOf() method that's applied to the current character returns -1 (this negative means that StringBuilder doesn't contain the current character):
public static String removeDuplicates(String str) {
char[] chArray = str.toCharArray(); // or, use charAt(i)
StringBuilder sb = new StringBuilder();
for (char ch : chArray) {
if (sb.indexOf(String.valueOf(ch)) == -1) {
sb.append(ch);
}
}
return sb.toString();
}
The next solution relies on a collaboration between HashSet and StringBuilder. Mainly, HashSet ensures that duplicates are eliminated, while StringBuilder stores the resulting string. If HashSet.add() returns true, then we add the character in StringBuilder as well:
public static String removeDuplicates(String str) {
char[] chArray = str.toCharArray();
StringBuilder sb = new StringBuilder();
Set<Character> chHashSet = new HashSet<>();
for (char c: chArray) {
if (chHashSet.add(c)) {
sb.append(c);
}
}
return sb.toString();
}
The solutions we've presented so far use the toCharArray() method to convert the given string into char[]. Alternatively, both solutions can use str.charAt(position) as well.
The third solution relies on Java 8 functional style:
public static String removeDuplicates(String str) {
return Arrays.asList(str.split("")).stream()
.distinct()
.collect(Collectors.joining());
}
First, the solution converts the given string into Stream<String>, where each entry is actually a single character. Furthermore, the solution applies the stateful intermediate operation, distinct(). This operation will eliminate duplicates from the stream, so it returns a stream without duplicates. Finally, the solution calls the collect() terminal operation and relies on Collectors.joining(), which simply concatenates the characters into a string in the encounter order.
13. Removing a given character
A solution that relies on JDK support can exploit the String.replaceAll() method. This method replaces each substring (in our case, each character) of the given string that matches the given regular expression (in our case, the regular expression is the character itself) with the given replacement (in our case, the replacement is an empty string, ""):
public static String removeCharacter(String str, char ch) {
return str.replaceAll(Pattern.quote(String.valueOf(ch)), "");
}
Notice that the regular expression is wrapped in the Pattern.quote() method. This is needed to escape special characters such as <, (, [, {, \, ^, -, =, $, !, |, ], }, ), ?, *, +, ., and >. Mainly, this method returns a literal pattern string for the specified string.
Now, let's take a look at a solution that avoids regular expressions. This time, the solution relies on StringBuilder. Basically, the solution loops the characters of the given string and compares each character with the character to remove. Each time the current character is different from the character to remove, the current character is appended in StringBuilder:
public static String removeCharacter(String str, char ch) {
StringBuilder sb = new StringBuilder();
char[] chArray = str.toCharArray();
for (char c : chArray) {
if (c != ch) {
sb.append(c);
}
}
return sb.toString();
}
Finally, let's focus on a Java 8 functional style approach. This is a four-step approach:
- Convert the string into IntStream via the String.chars() method
- Filter IntStream to eliminate duplicates
- Map the resulted IntStream to Stream<String>
- Join the strings from this stream and collect them as a single string
The code for this solution can be written as follows:
public static String removeCharacter(String str, char ch) {
return str.chars()
.filter(c -> c != ch)
.mapToObj(c -> String.valueOf((char) c))
.collect(Collectors.joining());
}
Alternatively, if we want to remove a Unicode surrogate pair, then we can rely on codePointAt() and codePoints(), as shown in the following implementation:
public static String removeCharacter(String str, String ch) {
int codePoint = ch.codePointAt(0);
return str.codePoints()
.filter(c -> c != codePoint)
.mapToObj(c -> String.valueOf(Character.toChars(c)))
.collect(Collectors.joining());
}
For third-party library support, please consider Apache Commons Lang, StringUtils.remove().
Now, let's talk about how to find the character with the most appearances.
14. Finding the character with the most appearances
A pretty straightforward solution relies on HashMap. This solution consists of three steps:
- First, loop the characters of the given string and put the pairs of the key-value in HashMap where the key is the current character and the value is the current number of occurrences
- Second, compute the maximum value in HashMap (for example, using Collections.max()) representing the maximum number of occurrences
- Finally, get the character that has the maximum number of occurrences by looping the HashMap entry set
The utility method returns Pair<Character, Integer> containing the character with the most appearances and the number of appearances (notice that the white spaces are ignored). If you don't prefer to have this extra class, that is, Pair, then just rely on Map.Entry<K, V>:
public static Pair<Character, Integer> maxOccurenceCharacter(
String str) {
Map<Character, Integer> counter = new HashMap<>();
char[] chStr = str.toCharArray();
for (int i = 0; i < chStr.length; i++) {
char currentCh = chStr[i];
if (!Character.isWhitespace(currentCh)) { // ignore spaces
Integer noCh = counter.get(currentCh);
if (noCh == null) {
counter.put(currentCh, 1);
} else {
counter.put(currentCh, ++noCh);
}
}
}
int maxOccurrences = Collections.max(counter.values());
char maxCharacter = Character.MIN_VALUE;
for (Entry<Character, Integer> entry: counter.entrySet()) {
if (entry.getValue() == maxOccurrences) {
maxCharacter = entry.getKey();
}
}
return Pair.of(maxCharacter, maxOccurrences);
}
If using HashMap looks cumbersome, then another solution (that's a little faster) consists of relying on the ASCII codes. This solution starts with an empty array of 256 indexes (256 is the maximum number of extended ASCII table codes; more information can be found in the Finding the first non-repeated character section). Furthermore, this solution loops the characters of the given string and keeps track of the number of appearances for each character by increasing the corresponding index in this array:
private static final int EXTENDED_ASCII_CODES = 256;
...
public static Pair<Character, Integer> maxOccurenceCharacter(
String str) {
int maxOccurrences = -1;
char maxCharacter = Character.MIN_VALUE;
char[] chStr = str.toCharArray();
int[] asciiCodes = new int[EXTENDED_ASCII_CODES];
for (int i = 0; i < chStr.length; i++) {
char currentCh = chStr[i];
if (!Character.isWhitespace(currentCh)) { // ignoring space
int code = (int) currentCh;
asciiCodes[code]++;
if (asciiCodes[code] > maxOccurrences) {
maxOccurrences = asciiCodes[code];
maxCharacter = currentCh;
}
}
}
return Pair.of(maxCharacter, maxOccurrences);
}
The last solution we will discuss here relies on Java 8 functional style:
public static Pair<Character, Long>
maxOccurenceCharacter(String str) {
return str.chars()
.filter(c -> Character.isWhitespace(c) == false) // ignoring space
.mapToObj(c -> (char) c)
.collect(groupingBy(c -> c, counting()))
.entrySet()
.stream()
.max(comparingByValue())
.map(p -> Pair.of(p.getKey(), p.getValue()))
.orElse(Pair.of(Character.MIN_VALUE, -1L));
}
To start, this solution collects distinct characters as keys in Map, along with their number of occurrences as values. Furthermore, it uses the Java 8 Map.Entry.comparingByValue() and max() terminal operations to determine the entry in the map with the highest value (highest number of occurrences). Since max() is a terminal operation, the solution may return Optional<Entry<Character, Long>>, but this solution adds an extra step and maps this entry to Pair<Character, Long>.
15. Sorting an array of strings by length
The first thing that comes to mind when sorting is the use of a comparator.
In this case, the solution should compare lengths of strings, and so the integers are returned by calling String.length() for each string in the given array. So, if the integers are sorted (ascending or descending), then the strings will be sorted.
The Java Arrays class already provides a sort() method that takes the array to sort and a comparator. In this case, Comparator<String> should do the job.
Before Java 7, code that implemented a comparator relied on the compareTo() method. Common usage of this method was to compute a difference of the x1-x2 type, but this computation may lead to overflows. This makes compareTo() rather tedious. Starting with Java 7, Integer.compare() is the way to go (no overflow risks).
The following is a method that sorts the given array by relying on the Arrays.sort() method:
public static void sortArrayByLength(String[] strs, Sort direction) {
if (direction.equals(Sort.ASC)) {
Arrays.sort(strs, (String s1, String s2)
-> Integer.compare(s1.length(), s2.length()));
} else {
Arrays.sort(strs, (String s1, String s2)
-> (-1) * Integer.compare(s1.length(), s2.length()));
}
}
Each wrapper of a primitive numeric type has a compare() method.
Starting with Java 8, the Comparator interface was enriched with a significant number of useful methods. One of these methods is comparingInt(), which takes a function that extracts an int sort key from the generic type and returns a Comparator<T> value that compares it with that sort key. Another useful method is reversed(), which reverses the current Comparator value.
Based on these two methods, we can empower Arrays.sort() as follows:
public static void sortArrayByLength(String[] strs, Sort direction) {
if (direction.equals(Sort.ASC)) {
Arrays.sort(strs, Comparator.comparingInt(String::length));
} else {
Arrays.sort(strs,
Comparator.comparingInt(String::length).reversed());
}
}
Comparators can be chained with the thenComparing() method.
The solutions we've presented here return void, which means that they sort the given array. To return a new sorted array and not alter the given array, we can use Java 8 functional style, as shown in the following snippet of code:
public static String[] sortArrayByLength(String[] strs,
Sort direction) {
if (direction.equals(Sort.ASC)) {
return Arrays.stream(strs)
.sorted(Comparator.comparingInt(String::length))
.toArray(String[]::new);
} else {
return Arrays.stream(strs)
.sorted(Comparator.comparingInt(String::length).reversed())
.toArray(String[]::new);
}
}
So, the code creates a stream from the given array, sorts it via the sorted() stateful intermediate operation, and collects the result in another array.
16. Checking that a string contains a substring
A very simple, one line of code solution relies on the String.contains() method.
This method returns a boolean value indicating whether the given substring is present in the string or not:
String text = "hello world!";
String subtext = "orl";
// pay attention that this will return true for subtext=""
boolean contains = text.contains(subtext);
Alternatively, a solution can be implemented by relying on String.indexOf() (or String.lastIndexOf()), as follows:
public static boolean contains(String text, String subtext) {
return text.indexOf(subtext) != -1; // or lastIndexOf()
}
Another solution can be implemented based on a regular expression, as follows:
public static boolean contains(String text, String subtext) {
return text.matches("(?i).*" + Pattern.quote(subtext) + ".*");
}
Notice that the regular expression is wrapped in the Pattern.quote() method. This is needed to escape special characters such as <([{\^-=$!|]})?*+.> in the given substring.
For third-party library support, please consider Apache Commons Lang, StringUtils.containsIgnoreCase().
17. Counting substring occurrences in a string
Counting the number of occurrences of a string in another string is a problem that can have at least two interpretations:
- 11 in 111 occurs 1 time
- 11 in 111 occurs 2 times
In the first case (11 in 111 occurs 1 time), the solution can rely on the String.indexOf() method. One of the flavors of this method allows us to obtain the index within this string of the first occurrence of the specified substring, starting at the specified index (or -1, if there is no such occurrence). Based on this method, the solution can simply traverse the given string and count the given substring occurrences. The traversal starts from position 0 and continues until the substring is not found:
public static int countStringInString(String string, String toFind) {
int position = 0;
int count = 0;
int n = toFind.length();
while ((position = string.indexOf(toFind, position)) != -1) {
position = position + n;
count++;
}
return count;
}
Alternatively, the solution can use the String.split() method. Basically, the solution can split the given string using the given substring as a delimiter. The length of the resulting String[] array should be equal to the number of expected occurrences:
public static int countStringInString(String string, String toFind) {
int result = string.split(Pattern.quote(toFind), -1).length - 1;
return result < 0 ? 0 : result;
}
In the second case (11 in 111 occurs 2 times), the solution can rely on the Pattern and Matcher classes in a simple implementation, as follows:
public static int countStringInString(String string, String toFind) {
Pattern pattern = Pattern.compile(Pattern.quote(toFind));
Matcher matcher = pattern.matcher(string);
int position = 0;
int count = 0;
while (matcher.find(position)) {
position = matcher.start() + 1;
count++;
}
return count;
}
Nice! Let's continue with another problem with strings.
18. Checking whether two strings are anagrams
Two strings that have the same characters, but that are in a different order, are anagrams. Some definitions impose that anagrams are case-insensitive and/or that white spaces (blanks) should be ignored.
So, independent of the applied algorithm, the solution must convert the given string into lowercase and remove white spaces (blanks). Besides that, the first solution we mentioned sorts the arrays via Arrays.sort() and will check their equality via Arrays.equals().
Once they are sorted, if they are anagrams, they will be equal (the following diagram shows two words that are anagrams):
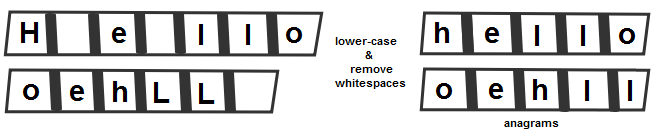
This solution (including its Java 8 functional style version) is available in the code bundled with this book. The main drawback of these two solutions is represented by the sorting part. The following solution eliminates this step and relies on an empty array (initially containing only 0) of 256 indexes (extended ASCII table codes of characters—more information can be found in the Finding the first non-repeated character section).
The algorithm is pretty simple:
- For each character from the first string, this solution increases the value in this array corresponding to the ASCII code by 1
- For each character from the second string, this solution decreases the value in this array corresponding to the ASCII code by 1
The code is as follows:
private static final int EXTENDED_ASCII_CODES = 256;
...
public static boolean isAnagram(String str1, String str2) {
int[] chCounts = new int[EXTENDED_ASCII_CODES];
char[] chStr1 = str1.replaceAll("\\s",
"").toLowerCase().toCharArray();
char[] chStr2 = str2.replaceAll("\\s",
"").toLowerCase().toCharArray();
if (chStr1.length != chStr2.length) {
return false;
}
for (int i = 0; i < chStr1.length; i++) {
chCounts[chStr1[i]]++;
chCounts[chStr2[i]]--;
}
for (int i = 0; i < chCounts.length; i++) {
if (chCounts[i] != 0) {
return false;
}
}
return true;
}
At the end of this traversal, if the given strings are anagrams, then this array contains only 0.
19. Declaring multiline strings (text blocks)
At the time of writing this book, JDK 12 had a proposal for adding multiline strings known as JEP 326: Raw String Literals. But this was dropped at the last minute.
Starting with JDK 13, the idea was reconsidered and, unlike the declined raw string literals, text blocks are surrounded by three double quotes, """, as follows:
String text = """My high school,
the Illinois Mathematics and Science Academy,
showed me that anything is possible
and that you're never too young to think big.""";
Text blocks can be very useful for writing multiline SQL statements, using polyglot languages, and so on. More details can be found at https://openjdk.java.net/jeps/355.
Nevertheless, there are several surrogate solutions that can be used before JDK 13. These solutions have a common point—the use of the line separator:
private static final String LS = System.lineSeparator();
Starting with JDK 8, a solution may rely on String.join(), as follows:
String text = String.join(LS,
"My high school, ",
"the Illinois Mathematics and Science Academy,",
"showed me that anything is possible ",
"and that you're never too young to think big.");
Before JDK 8, an elegant solution may have relied on StringBuilder. This solution is available in the code bundled with this book.
While the preceding solutions are good fits for a relatively large number of strings, the following two are okay if we just have a few strings. The first one uses the + operator:
String text = "My high school, " + LS +
"the Illinois Mathematics and Science Academy," + LS +
"showed me that anything is possible " + LS +
"and that you're never too young to think big.";
The second one uses String.format():
String text = String.format("%s" + LS + "%s" + LS + "%s" + LS + "%s",
"My high school, ",
"the Illinois Mathematics and Science Academy,",
"showed me that anything is possible ",
"and that you're never too young to think big.");
How can we process each line of a multiline string? Well, a quick approach requires JDK 11, which comes with the String.lines() method. This method splits the given string via a line separator (which supports \n, \r, and \r\n) and transforms it into Stream<String>. Alternatively, the String.split() method can be used as well (this is available starting with JDK 1.4). If the number of strings becomes significant, it is advised to put them in a file and read/process them one by one (for example, via the getResourceAsStream() method). Other approaches rely on StringWriter or BufferedWriter.newLine().
For third-party library support, please consider Apache Commons Lang, StringUtils.join(), Guava, Joiner, and the custom annotation, @Multiline.
For third-party library support, please consider Apache Commons Lang, StringUtils.join(), Guava, Joiner, and the custom annotation, @Multiline.
20. Concatenating the same string n times
Before JDK 11, a solution could be quickly provided via StringBuilder, as follows:
public static String concatRepeat(String str, int n) {
StringBuilder sb = new StringBuilder(str.length() * n);
for (int i = 1; i <= n; i++) {
sb.append(str);
}
return sb.toString();
}
Starting with JDK 11, the solution relies on the String.repeat(int count) method. This method returns a string resulting from concatenating this string count times. Behind the scenes, this method uses System.arraycopy(), which makes this very fast:
String result = "hello".repeat(5);
Other solutions that can fit well in different scenarios are listed as follows:
- Following is a String.join()-based solution:
String result = String.join("", Collections.nCopies(5, TEXT));
- Following is a Stream.generate()-based solution:
String result = Stream.generate(() -> TEXT)
.limit(5)
.collect(joining());
- Following is a String.format()-based solution:
String result = String.format("%0" + 5 + "d", 0)
.replace("0", TEXT);
- Following is a char[] based solution:
String result = new String(new char[5]).replace("\0", TEXT);
For third-party library support, please consider Apache Commons Lang, StringUtils.repeat(), and Guava, Strings.repeat().
To check whether a string is a sequence of the same substring, rely on the following method:
public static boolean hasOnlySubstrings(String str) {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < str.length() / 2; i++) {
sb.append(str.charAt(i));
String resultStr = str.replaceAll(sb.toString(), "");
if (resultStr.length() == 0) {
return true;
}
}
return false;
}
The solution loops half of the given string and progressively replaces it with "", a substring build, by appending the original string in StringBuilder, character by character. If these replacements result in an empty string, it means that the given string is a sequence of the same substring.
21. Removing leading and trailing spaces
The quickest solution to this problem probably relies on the String.trim() method. This method is capable of removing all leading and trailing spaces, that is, any character whose code point is less than or equal to U+0020 or 32 (the space character):
String text = "\n \n\n hello \t \n \r";
String trimmed = text.trim();
The preceding snippet of code will work as expected. The trimmed string will be hello. This only works because all of the white spaces that are being used are less than U+0020 or 32 (the space character). There are 25 characters (https://en.wikipedia.org/wiki/Whitespace_character#Unicode) defined as white spaces and trim() covers only a part of them (in short, trim() is not Unicode aware). Let's consider the following string:
char space = '\u2002';
String text = space + "\n \n\n hello \t \n \r" + space;
\u2002 is another type of white space that trim() doesn't recognize (\u2002 is above \u0020). This means that, in such cases, trim() will not work as expected. Starting with JDK 11, this problem has a solution named strip(). This method extends the power of trim() into the land of Unicode:
String stripped = text.strip();
This time, all of the leading and trailing white spaces are removed.
Moreover, JDK 11 comes with two flavors of strip() for removing only the leading (stripLeading()) or only the trailing (stripTrailing()) white spaces. The trim() method doesn't have these flavors.
22. Finding the longest common prefix
Let's consider the following array of strings:
String[] texts = {"abc", "abcd", "abcde", "ab", "abcd", "abcdef"};
Now, let's put these strings one below the other, as follows:
abc
abcd
abcde
ab
abcd
abcdef
A simple comparison of these strings reveals that ab is the longest common prefix. Now, let's dive into a solution for solving this problem. The solution that we've presented here relies on a straightforward comparison. This solution takes the first string from the array and compares each of its characters in the rest of the strings. The algorithm stops if either of the following happens:
- The length of the first string is greater than the length of any of the other strings
- The current character of the first string is not the same as the current character of any of the other strings
If the algorithm forcibly stops because of one of the preceding scenarios, then the longest common prefix is the substring from 0 to the index of the current character from the first string. Otherwise, the longest common prefix is the first string from the array. The code for this solution is as follows:
public static String longestCommonPrefix(String[] strs) {
if (strs.length == 1) {
return strs[0];
}
int firstLen = strs[0].length();
for (int prefixLen = 0; prefixLen < firstLen; prefixLen++) {
char ch = strs[0].charAt(prefixLen);
for (int i = 1; i < strs.length; i++) {
if (prefixLen >= strs[i].length()
|| strs[i].charAt(prefixLen) != ch) {
return strs[i].substring(0, prefixLen);
}
}
}
return strs[0];
}
Other solutions to this problem use well-known algorithms such as Binary Search or Trie. In the source code that accompanies this book, there is a solution based on Binary Search as well.
23. Applying indentation
Starting with JDK 12, we can indent text via the String.indent(int n) method.
Let's assume that we have the following String values:
String days = "Sunday\n"
+ "Monday\n"
+ "Tuesday\n"
+ "Wednesday\n"
+ "Thursday\n"
+ "Friday\n"
+ "Saturday";
Printing this String values with an indentation of 10 spaces can be done as follows:
System.out.print(days.indent(10));
The output will be as follows:

Now, let's try a cascade indentation:
List<String> days = Arrays.asList("Sunday", "Monday", "Tuesday",
"Wednesday", "Thursday", "Friday", "Saturday");
for (int i = 0; i < days.size(); i++) {
System.out.print(days.get(i).indent(i));
}
The output will be as follows:

Now, let's indent depending on the length of the String value:
days.stream()
.forEachOrdered(d -> System.out.print(d.indent(d.length())));
The output will be as follows:

How about indenting a piece of HTML code? Let's see:
String html = "<html>";
String body = "<body>";
String h2 = "<h2>";
String text = "Hello world!";
String closeH2 = "</h2>";
String closeBody = "</body>";
String closeHtml = "</html>";
System.out.println(html.indent(0) + body.indent(4) + h2.indent(8)
+ text.indent(12) + closeH2.indent(8) + closeBody.indent(4)
+ closeHtml.indent(0));
The output will be as follows:

24. Transforming strings
Let's assume that we have a string and we want to transform it into another string (for example, transform it into upper case). We can do this by applying a function such as Function<? super String, ? extends R>.
In JDK 8, we can accomplish this via map(), as shown in the following two simple examples:
// hello world
String resultMap = Stream.of("hello")
.map(s -> s + " world")
.findFirst()
.get();
// GOOOOOOOOOOOOOOOOL! GOOOOOOOOOOOOOOOOL!
String resultMap = Stream.of("gooool! ")
.map(String::toUpperCase)
.map(s -> s.repeat(2))
.map(s -> s.replaceAll("O", "OOOO"))
.findFirst()
.get();
Starting with JDK 12, we can rely on a new method named transform(Function<? super String, ? extends R> f). Let's rewrite the preceding snippets of code via transform():
// hello world
String result = "hello".transform(s -> s + " world");
// GOOOOOOOOOOOOOOOOL! GOOOOOOOOOOOOOOOOL!
String result = "gooool! ".transform(String::toUpperCase)
.transform(s -> s.repeat(2))
.transform(s -> s.replaceAll("O", "OOOO"));
While map() is more general, transform() is dedicated to applying a function to a string and returns the resulting string.
25. Computing the minimum and maximum of two numbers
Before JDK 8, a possible solution would be to rely on the Math.min() and Math.max() methods, as follows:
int i1 = -45;
int i2 = -15;
int min = Math.min(i1, i2);
int max = Math.max(i1, i2);
The Math class provides a min() and a max() method for each primitive numeric type (int, long, float, and double).
Starting with JDK 8, each wrapper class of primitive numeric types (Integer, Long, Float, and Double) comes with dedicated min() and max() methods, and, behind these methods, there are invocations of their correspondents from the Math class. See the following example (this is a little bit more expressive):
double d1 = 0.023844D;
double d2 = 0.35468856D;
double min = Double.min(d1, d2);
double max = Double.max(d1, d2);
In a functional style context, a potential solution will rely on the BinaryOperator functional interface. This interface comes with two methods, minBy() and maxBy():
float f1 = 33.34F;
final float f2 = 33.213F;
float min = BinaryOperator.minBy(Float::compare).apply(f1, f2);
float max = BinaryOperator.maxBy(Float::compare).apply(f1, f2);
These two methods are capable of returning the minimum (respectively, the maximum) of two elements according to the specified comparator.
26. Summing two large int/long values and operation overflow
Let's dive into the solution by starting with the + operator, as in the following example:
int x = 2;
int y = 7;
int z = x + y; // 9
This is a very simple approach and works fine for most of the computations that involve int, long, float, and double.
Now, let's apply this operator on the following two large numbers (sum 2,147,483,647 with itself):
int x = Integer.MAX_VALUE;
int y = Integer.MAX_VALUE;
int z = x + y; // -2
This time, z will be equal to -2, which is not the expected result, that is, 4,294,967,294. Changing only the z type from int to long will not help. However, changing the types of x and y from int to long as well will help:
long x = Integer.MAX_VALUE;
long y = Integer.MAX_VALUE;
long z = x + y; // 4294967294
But the problem will reappear if, instead of Integer.MAX_VALUE, there is Long.MAX_VALUE:
long x = Long.MAX_VALUE;
long y = Long.MAX_VALUE;
long z = x + y; // -2
Starting with JDK 8, the + operator has been wrapped in a more expressive way by each wrapper of a primitive numeric type. Therefore, the Integer, Long, Float, and Double classes have a sum() method:
long z = Long.sum(); // -2
Behind the scenes, the sum() methods uses the + operator as well, so they simply produce the same result.
But also starting with JDK 8, the Math class was enriched with two addExact() methods. There is one addExact() for summing two int variables and one for summing two long variables. These methods are very useful if the result is prone to overflowing int or long, as shown in the preceding case. In such cases, these methods throw ArithmeticException instead of returning a misleading result, as in the following example:
int z = Math.addExact(x, y); // throw ArithmeticException
The code will throw an exception such as java.lang.ArithmeticException: integer overflow. This is useful since it allows us to avoid introducing misleading results in further computations (for example, earlier, -2 could silently enter further computations).
In a functional style context, a potential solution will rely on the BinaryOperator functional interface, as follows (simply define the operation of the two operands of the same type):
BinaryOperator<Integer> operator = Math::addExact;
int z = operator.apply(x, y);
Besides addExact(), Math has multiplyExact(), substractExact(), and negateExact(). Moreover, the well-known increment and decrement expressions, i++ and i--, can be controlled for overflowing their domains via the incrementExact() and decrementExact() methods (for example, Math.incrementExact(i)). Notice that these methods are only available for int and long.
When working with a large number, also focus on the BigInteger (immutable arbitrary-precision integers) and BigDecimal (immutable, arbitrary-precision signed decimal numbers) classes.
27. String as an unsigned number in the radix
The support for unsigned arithmetic was added to Java starting with version 8. The Byte, Short, Integer, and Long classes were affected the most by this addition.
In Java, strings representing positive numbers can be parsed as unsigned int and long types via the parseUnsignedInt() and parseUnsignedLong() JDK 8 methods. For example, let's consider the following integer as a string:
String nri = "255500";
The solution to parsing it into an unsigned int value in the radix of 36 (the maximum accepted radix) looks as follows:
int result = Integer.parseUnsignedInt(nri, Character.MAX_RADIX);
The first argument is the number, while the second is the radix. The radix should be in the range [2, 36] or [Character.MIN_RADIX, Character.MAX_RADIX].
Using a radix of 10 can be easily accomplished as follows (this method applies a radix of 10 by default):
int result = Integer.parseUnsignedInt(nri);
Starting with JDK 9, parseUnsignedInt() has a new flavor. Besides the string and the radix, this method accepts a range of the [beginIndex, endIndex] type. This time, the parsing is accomplished in this range. For example, specifying the range [1, 3] can be done as follows:
int result = Integer.parseUnsignedInt(nri, 1, 4, Character.MAX_RADIX);
The parseUnsignedInt() method can parse strings that represent numbers greater than Integer.MAX_VALUE (trying to accomplish this via Integer.parseInt() will throw a java.lang.NumberFormatException exception):
// Integer.MAX_VALUE + 1 = 2147483647 + 1 = 2147483648
int maxValuePlus1 = Integer.parseUnsignedInt("2147483648");
The same set of methods exist for long numbers in the Long class (for example, parseUnsignedLong()).
28. Converting into a number by an unsigned conversion
The problem requires that we convert the given signed int into long via an unsigned conversion. So, let's consider signed Integer.MIN_VALUE, which is -2,147,483,648.
In JDK 8, by using the Integer.toUnsignedLong() method, the conversion will be as follows (the result will be 2,147,483,648):
long result = Integer.toUnsignedLong(Integer.MIN_VALUE);
Here is another example that converts the signed Short.MIN_VALUE and Short.MAX_VALUE into unsigned integers:
int result1 = Short.toUnsignedInt(Short.MIN_VALUE);
int result2 = Short.toUnsignedInt(Short.MAX_VALUE);
Other methods from the same category are Integer.toUnsignedString(), Long.toUnsignedString(), Byte.toUnsignedInt(), Byte.toUnsignedLong(), Short.toUnsignedInt(), and Short.toUnsignedLong().
29. Comparing two unsigned numbers
Let's consider two signed integers, Integer.MIN_VALUE (-2,147,483,648) and Integer.MAX_VALUE (2,147,483,647). Comparing these integers (signed values) will result in -2,147,483,648 being smaller than 2,147,483,647:
// resultSigned is equal to -1 indicating that
// MIN_VALUE is smaller than MAX_VALUE
int resultSigned = Integer.compare(Integer.MIN_VALUE,
Integer.MAX_VALUE);
In JDK 8, these two integers can be compared as unsigned values via the Integer.compareUnsigned() method (this is the equivalent of Integer.compare() for unsigned values). Mainly, this method ignores the notion of sign bit, and the left-most bit is considered the most significant bit. Under the unsigned values umbrella, this method returns 0 if the compared numbers are equal, a value less than 0 if the first unsigned value is smaller than the second, and a value greater than 0 if the first unsigned value is greater than the second.
The following comparison returns 1, indicating that the unsigned value of Integer.MIN_VALUE is greater than the unsigned value of Integer.MAX_VALUE:
// resultSigned is equal to 1 indicating that
// MIN_VALUE is greater than MAX_VALUE
int resultUnsigned
= Integer.compareUnsigned(Integer.MIN_VALUE, Integer.MAX_VALUE);
The compareUnsigned() method is available in the Integer and Long classes starting with JDK 8, and in the Byte and Short classes starting with JDK 9.
30. Division and modulo of unsigned values
Computing the unsigned quotient and remainder that resulted from the division of two unsigned values is supported by the JDK 8 unsigned arithmetic API via the divideUnsigned() and remainderUnsigned() methods.
Let's consider the Interger.MIN_VALUE and Integer.MAX_VALUE signed numbers and let's apply division and modulo. There's nothing new here:
// signed division
// -1
int divisionSignedMinMax = Integer.MIN_VALUE / Integer.MAX_VALUE;
// 0
int divisionSignedMaxMin = Integer.MAX_VALUE / Integer.MIN_VALUE;
// signed modulo
// -1
int moduloSignedMinMax = Integer.MIN_VALUE % Integer.MAX_VALUE;
// 2147483647
int moduloSignedMaxMin = Integer.MAX_VALUE % Integer.MIN_VALUE;
Now, let's treat Integer.MIN_VALUE and Integer.MAX_VALUE as unsigned values and let's apply divideUnsigned() and remainderUnsigned():
// division unsigned
int divisionUnsignedMinMax = Integer.divideUnsigned(
Integer.MIN_VALUE, Integer.MAX_VALUE); // 1
int divisionUnsignedMaxMin = Integer.divideUnsigned(
Integer.MAX_VALUE, Integer.MIN_VALUE); // 0
// modulo unsigned
int moduloUnsignedMinMax = Integer.remainderUnsigned(
Integer.MIN_VALUE, Integer.MAX_VALUE); // 1
int moduloUnsignedMaxMin = Integer.remainderUnsigned(
Integer.MAX_VALUE, Integer.MIN_VALUE); // 2147483647
Notice their similarity to the comparison operation. Both operations, that is, unsigned division and unsigned modulo, interpret all of the bits as value bits and ignore the sign bit.
divideUnsigned() and remainderUnsigned() are present in the Integer and Long classes, respectively.
31. double/float is a finite floating-point value
This problem arises from the fact that some floating-point methods and operations produce Infinity or NaN as results instead of throwing an exception.
The solution to checking whether the given float/double is a finite floating-point value relies on the following conditions—the absolute value of the given float/double value must not exceed the largest positive finite value of the float/double type:
// for float
Math.abs(f) <= Float.MAX_VALUE;
// for double
Math.abs(d) <= Double.MAX_VALUE
Starting with Java 8, the preceding conditions were exposed via two dedicated flag-methods, Float.isFinite() and Double.isFinite(). Therefore, the following examples are valid test cases for finite floating-point values:
Float f1 = 4.5f;
boolean f1f = Float.isFinite(f1); // f1 = 4.5, is finite
Float f2 = f1 / 0;
boolean f2f = Float.isFinite(f2); // f2 = Infinity, is not finite
Float f3 = 0f / 0f;
boolean f3f = Float.isFinite(f3); // f3 = NaN, is not finite
Double d1 = 0.000333411333d;
boolean d1f = Double.isFinite(d1); // d1 = 3.33411333E-4,is finite
Double d2 = d1 / 0;
boolean d2f = Double.isFinite(d2); // d2 = Infinity, is not finite
Double d3 = Double.POSITIVE_INFINITY * 0;
boolean d3f = Double.isFinite(d3); // d3 = NaN, is not finite
These methods are handy in conditions such as the following:
if (Float.isFinite(d1)) {
// do a computation with d1 finite floating-point value
} else {
// d1 cannot enter in further computations
}
32. Applying logical AND/OR/XOR to two boolean expressions
The truth table of elementary logic operations (AND, OR, and XOR) looks as follows:
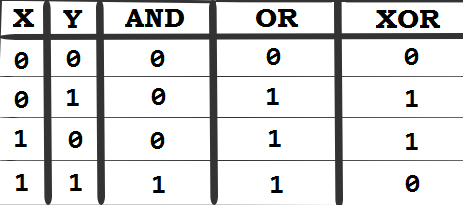
In Java, the logical AND operator is represented as &&, the logical OR operator is represented as ||, and the logical XOR operator is represented as ^. Starting with JDK 8, these operators are applied to two booleans and are wrapped in three static methods—Boolean.logicalAnd(), Boolean.logicalOr(), and Boolean.logicalXor():
int s = 10;
int m = 21;
// if (s > m && m < 50) { } else { }
if (Boolean.logicalAnd(s > m, m < 50)) {} else {}
// if (s > m || m < 50) { } else { }
if (Boolean.logicalOr(s > m, m < 50)) {} else {}
// if (s > m ^ m < 50) { } else { }
if (Boolean.logicalXor(s > m, m < 50)) {} else {}
Using a combination of these methods is also possible:
if (Boolean.logicalAnd(
Boolean.logicalOr(s > m, m < 50),
Boolean.logicalOr(s <= m, m > 50))) {} else {}
33. Converting BigInteger into a primitive type
The BigInteger class is a very handy tool for representing immutable arbitrary-precision integers.
This class also contains methods (originating from java.lang.Number) that are useful for converting BigInteger into a primitive type such as byte, long, or double. However, these methods can produce unexpected results and confusion. For example, let's assume that we have BigInteger that wraps Long.MAX_VALUE:
BigInteger nr = BigInteger.valueOf(Long.MAX_VALUE);
Let's convert this BigInteger into a primitive long via the BigInteger.longValue() method:
long nrLong = nr.longValue();
So far, everything has worked as expected since the Long.MAX_VALUE is 9,223,372,036,854,775,807 and the nrLong primitive variable has exactly this value.
Now, let's try to convert this BigInteger class into a primitive int value via the BigInteger.intValue() method:
int nrInt = nr.intValue();
This time, the nrInt primitive variable will have a value of -1 (the same result will produce shortValue() and byteValue()). Conforming to the documentation, if the value of BigInteger is too big to fit in the specified primitive type, only the low-order n bits are returned (n depends on the specified primitive type). But if the code is not aware of this statement, then it will push values as -1 in further computations, which will lead to confusion.
However, starting with JDK 8, a new set of methods was added. These methods are dedicated to identifying the information that's lost during the conversion from BigInteger into the specified primitive type. If a piece of lost information is detected, ArithmeticException will be thrown. This way, the code signals that the conversion has encountered some issues and prevents this unpleasant situation.
These methods are longValueExact(), intValueExact(), shortValueExact(), and byteValueExact():
long nrExactLong = nr.longValueExact(); // works as expected
int nrExactInt = nr.intValueExact(); // throws ArithmeticException
Notice that intValueExact() did not return -1 as intValue(). This time, the lost information that was caused by the attempt of converting the largest long value into int was signaled via an exception of the ArithmeticException type.
34. Converting long into int
Converting a long value into an int value seems like an easy job. For example, a potential solution can rely on casting the following:
long nr = Integer.MAX_VALUE;
int intNrCast = (int) nr;
Alternatively, it can rely on Long.intValue(), as follows:
int intNrValue = Long.valueOf(nrLong).intValue();
Both approaches work just fine. Now, let's suppose we have the following long value:
long nrMaxLong = Long.MAX_VALUE;
This time, both approaches will return -1. In order to avoid such results, it is advisable to rely on JDK 8, that is, Math.toIntExact(). This method gets an argument of the long type and tries to convert it into int. If the obtained value overflows int, then this method will throw ArithmeticException:
// throws ArithmeticException
int intNrMaxExact = Math.toIntExact(nrMaxLong);
Behind the scenes, toIntExact() relies on the ((int)value != value) condition.
35. Computing the floor of a division and modulus
Let's assume that we have the following division:
double z = (double)222/14;
This will initialize z with the result of this division, that is, 15.85, but our problem requests the floor of this division, which is 15 (this is the largest integer value that is less than or equal to the algebraic quotient). A solution to obtain this desired result will consist of applying Math.floor(15.85), which is 15.
However, 222 and 14 are integers, and so this preceding division is written as follows:
int z = 222/14;
This time, z will be equal to 15, which is exactly the expected result (the / operator returns the integer closest to zero). There is no need to apply Math.floor(z). Moreover, if the divisor is 0, then 222/0 will throw ArithmeticException.
The conclusion so far is that the floor of a division for two integers that have the same sign (both are positive or negative) can be obtained via the / operator.
Okay, so far, so good, but let's assume that we have the following two integers (opposite signs; the dividend is negative and the divisor is positive, and vice versa):
double z = (double) -222/14;
This time, z will be equal to -15.85. Again, by applying Math.floor(z), the result will be -16, which is correct (this is the largest integer value that is less than or equal to the algebraic quotient).
Let's go over the same problem again with int:
int z = -222/14;
This time, z will be equal to -15. This is incorrect and Math.floor(z) will not help us in this case since Math.floor(-15) is -15. So, this is a problem that should be considered.
From JDK 8 onward, all of these cases have been covered and exposed via the Math.floorDiv() method. This method takes two integers representing the dividend and the divisor as arguments and returns the largest (closest to positive infinity) int value that is less than or equal to the algebraic quotient:
int x = -222;
int y = 14;
// x is the dividend, y is the divisor
int z = Math.floorDiv(x, y); // -16
The Math.floorDiv() method comes in three flavors: floorDiv(int x, int y), floorDiv(long x, int y), and floorDiv(long x, long y).
After Math.floorDiv(), JDK 8 came with Math.floorMod(), which returns the floor modulus of the given arguments. This is computed as the result of x - (floorDiv(x, y) * y), and so it will return the same result as the % operator for arguments with the same sign and a different result for arguments that don't have the same sign.
Rounding up the result of dividing two positive integers (a/b) can be accomplished quickly as follows:
long result = (a + b - 1) / b;
The following is one example of this (we have 4 / 3 = 1.33 and we want 2):
long result = (4 + 3 - 1) / 3; // 2
The following is another example of this (we have 17 / 7 = 2.42 and we want 3):
long result = (17 + 7 - 1) / 7; // 3
If the integers are not positive, then we can rely on Math.ceil():
long result = (long) Math.ceil((double) a/b);
36. Next floating-point value
Having an integer value such as 10 makes it very easy for us to obtain the next integer-point value, such as 10+1 (in the direction of positive infinity) or 10-1 (in the direction of negative infinity). Trying to achieve the same thing for float or double is not that easy as it is for integers.
Starting with JDK 6, the Math class has been enriched with the nextAfter() method. This method takes two arguments—the initial number (float or double) and the direction (Float/Double.NEGATIVE/POSITIVE_INFINITY)—and returns the next floating-point value. Here, it is a flavor of this method to return the next-floating point adjacent to 0.1 in the direction of negative infinity:
float f = 0.1f;
// 0.099999994
float nextf = Math.nextAfter(f, Float.NEGATIVE_INFINITY);
Starting with JDK 8, the Math class has been enriched with two methods that act as shortcuts for nextAfter() and are faster. These methods are nextDown() and nextUp():
float f = 0.1f;
float nextdownf = Math.nextDown(f); // 0.099999994
float nextupf = Math.nextUp(f); // 0.10000001
double d = 0.1d;
double nextdownd = Math.nextDown(d); // 0.09999999999999999
double nextupd = Math.nextUp(d); // 0.10000000000000002
Therefore, nextAfter() in the direction of negative infinity is available via Math.nextDown() and nextAfter(), while in the direction of positive infinity, this is available via Math.nextUp().
37. Multiplying two large int/long values and operation overflow
Let's dive into the solution starting from the * operator, as shown in the following example:
int x = 10;
int y = 5;
int z = x * y; // 50
This is a very simple approach and works fine for most of the computations that involve int, long, float, and double as well.
Now, let's apply this operator to the following two large numbers (multiply 2,147,483,647 with itself):
int x = Integer.MAX_VALUE;
int y = Integer.MAX_VALUE;
int z = x * y; // 1
This time, z will be equal to 1, which is not the expected result, that is, 4,611,686,014,132,420,609. Changing only the z type from int to long will not help. However, changing the types of x and y from int to long will:
long x = Integer.MAX_VALUE;
long y = Integer.MAX_VALUE;
long z = x * y; // 4611686014132420609
But the problem will reappear if we have Long.MAX_VALUE instead of Integer.MAX_VALUE:
long x = Long.MAX_VALUE;
long y = Long.MAX_VALUE;
long z = x * y; // 1
So, computations that overflow the domain and rely on the * operator will end up in misleading results.
Instead of using these results in further computations, it is better to be informed on time when an overflow operation occurred. JDK 8 comes with the Math.multiplyExact() method. This method tries to multiply two integers. If the result overflows, int will just throw ArithmeticException:
int x = Integer.MAX_VALUE;
int y = Integer.MAX_VALUE;
int z = Math.multiplyExact(x, y); // throw ArithmeticException
In JDK 8, Math.muliplyExact(int x, int y) returns int and Math.muliplyExact(long x, long y) returns long. In JDK 9, Math.muliplyExact(long, int y) returning long was added as well.
JDK 9 comes with Math.multiplyFull(int x, int y) returning long value. This method is very useful for obtaining the exact mathematical product of two integers as long, as follows:
int x = Integer.MAX_VALUE;
int y = Integer.MAX_VALUE;
long z = Math.multiplyFull(x, y); // 4611686014132420609
Just for the record, JDK 9 also comes with a method named Math.muliptlyHigh(long x, long y) returning a long. The long value returned by this method represents the most significant 64 bits of the 128-bit product of two 64-bit factors:
long x = Long.MAX_VALUE;
long y = Long.MAX_VALUE;
// 9223372036854775807 * 9223372036854775807 = 4611686018427387903
long z = Math.multiplyHigh(x, y);
In a functional style context, a potential solution will rely on the BinaryOperator functional interface, as follows (simply define the operation of the two operands of the same type):
int x = Integer.MAX_VALUE;
int y = Integer.MAX_VALUE;
BinaryOperator<Integer> operator = Math::multiplyExact;
int z = operator.apply(x, y); // throw ArithmeticException
For working with a large number, also focus on the BigInteger (immutable arbitrary-precision integers) and BigDecimal (immutable, arbitrary-precision signed decimal numbers) classes.
38. Fused Multiply Add
The mathematical computation (a * b) + c is heavily exploited in matrix multiplications, which are frequently used in High-Performance Computing (HPC), AI applications, machine learning, deep learning, neural networks, and so on.
The simplest way to implement this computation relies directly on the * and + operators, as follows:
double x = 49.29d;
double y = -28.58d;
double z = 33.63d;
double q = (x * y) + z;
The main problem of this implementation consists of low accuracy and performance caused by two rounding errors (one for the multiply operation and one for the addition operation).
But thanks to Intel AVX's instructions for performing SIMD operations and to JDK 9, which added the Math.fma() method, this computation can be boosted. By relying on Math.fma(), the rounding is done only once using the round to nearest even rounding mode:
double fma = Math.fma(x, y, z);
Notice that this improvement is available for modern Intel processors, so it is not enough to just have JDK 9 in place.
39. Compact number formatting
Starting with JDK 12, a new class for compact number formatting was added. This class is named java.text.CompactNumberFormat. The main goal of this class is to extend the existing Java number formatting API with support for locale and compaction.
A number can be formatted into a short style (for example, 1000 becomes 1K) or into a long style (for example, 1000 becomes 1 thousand). These two styles were grouped in the Style enum as SHORT and LONG.
Besides the CompactNumberFormat constructor, CompactNumberFormat can be created via two static methods that are added to the NumberFormat class:
- The first is a compact number format for the default locale with NumberFormat.Style.SHORT:
public static NumberFormat getCompactNumberInstance()
- The second is a compact number format for the specified locale with NumberFormat.Style:
public static NumberFormat getCompactNumberInstance(
Locale locale, NumberFormat.Style formatStyle)
Let's take a close look at formatting and parsing.
Formatting
By default, a number is formatted using RoundingMode.HALF_EVEN. However, we can explicitly set the rounding mode via NumberFormat.setRoundingMode().
Trying to condense this information into a utility class named NumberFormatters can be achieved as follows:
public static String forLocale(Locale locale, double number) {
return format(locale, Style.SHORT, null, number);
}
public static String forLocaleStyle(
Locale locale, Style style, double number) {
return format(locale, style, null, number);
}
public static String forLocaleStyleRound(
Locale locale, Style style, RoundingMode mode, double number) {
return format(locale, style, mode, number);
}
private static String format(
Locale locale, Style style, RoundingMode mode, double number) {
if (locale == null || style == null) {
return String.valueOf(number); // or use a default format
}
NumberFormat nf = NumberFormat.getCompactNumberInstance(locale,
style);
if (mode != null) {
nf.setRoundingMode(mode);
}
return nf.format(number);
}
Now, let's format the numbers 1000, 1000000, and 1000000000 with the US locale, SHORT style, and default rounding mode:
// 1K
NumberFormatters.forLocaleStyle(Locale.US, Style.SHORT, 1_000);
// 1M
NumberFormatters.forLocaleStyle(Locale.US, Style.SHORT, 1_000_000);
// 1B
NumberFormatters.forLocaleStyle(Locale.US, Style.SHORT,
1_000_000_000);
We can do the same with the LONG style:
// 1thousand
NumberFormatters.forLocaleStyle(Locale.US, Style.LONG, 1_000);
// 1million
NumberFormatters.forLocaleStyle(Locale.US, Style.LONG, 1_000_000);
// 1billion
NumberFormatters.forLocaleStyle(Locale.US, Style.LONG, 1_000_000_000);
We can also use the ITALIAN locale and SHORT style:
// 1.000
NumberFormatters.forLocaleStyle(Locale.ITALIAN, Style.SHORT,
1_000);
// 1 Mln
NumberFormatters.forLocaleStyle(Locale.ITALIAN, Style.SHORT,
1_000_000);
// 1 Mld
NumberFormatters.forLocaleStyle(Locale.ITALIAN, Style.SHORT,
1_000_000_000);
Finally, we can also use the ITALIAN locale and LONG style:
// 1 mille
NumberFormatters.forLocaleStyle(Locale.ITALIAN, Style.LONG,
1_000);
// 1 milione
NumberFormatters.forLocaleStyle(Locale.ITALIAN, Style.LONG,
1_000_000);
// 1 miliardo
NumberFormatters.forLocaleStyle(Locale.ITALIAN, Style.LONG,
1_000_000_000);
Now, let's suppose that we have two numbers: 1200 and 1600.
From the rounding mode's perspective, they will be rounded to 1000 and 2000, respectively. The default rounding mode, HALF_EVEN, will round 1200 to 1000 and 1600 to 2000. But if we want 1200 to become 2000 and 1600 to become 1000, then we need to explicitly set up the rounding mode as follows:
// 2000 (2 thousand)
NumberFormatters.forLocaleStyleRound(
Locale.US, Style.LONG, RoundingMode.UP, 1_200);
// 1000 (1 thousand)
NumberFormatters.forLocaleStyleRound(
Locale.US, Style.LONG, RoundingMode.DOWN, 1_600);
Parsing
Parsing is the reverse process of formatting. We have a given string and try to parse it as a number. This can be accomplished via the NumberFormat.parse() method. By default, parsing doesn't take advantage of grouping (for example, without grouping, 5,50 K is parsed as 5; with grouping, 5,50 K is parsed as 550000).
If we condense this information into a set of helper methods, then we obtain the following output:
public static Number parseLocale(Locale locale, String number)
throws ParseException {
return parse(locale, Style.SHORT, false, number);
}
public static Number parseLocaleStyle(
Locale locale, Style style, String number) throws ParseException {
return parse(locale, style, false, number);
}
public static Number parseLocaleStyleRound(
Locale locale, Style style, boolean grouping, String number)
throws ParseException {
return parse(locale, style, grouping, number);
}
private static Number parse(
Locale locale, Style style, boolean grouping, String number)
throws ParseException {
if (locale == null || style == null || number == null) {
throw new IllegalArgumentException(
"Locale/style/number cannot be null");
}
NumberFormat nf = NumberFormat.getCompactNumberInstance(locale,
style);
nf.setGroupingUsed(grouping);
return nf.parse(number);
}
Let's parse 5K and 5 thousand into 5000 without explicit grouping:
// 5000
NumberFormatters.parseLocaleStyle(Locale.US, Style.SHORT, "5K");
// 5000
NumberFormatters.parseLocaleStyle(Locale.US, Style.LONG, "5 thousand");
Now, let's parse 5,50K and 5,50 thousand to 550000 with explicit grouping:
// 550000
NumberFormatters.parseLocaleStyleRound(
Locale.US, Style.SHORT, true, "5,50K");
// 550000
NumberFormatters.parseLocaleStyleRound(
Locale.US, Style.LONG, true, "5,50 thousand");
More tuning can be obtained via the setCurrency(), setParseIntegerOnly(), setMaximumIntegerDigits(), setMinimumIntegerDigits(), setMinimumFractionDigits(), and setMaximumFractionDigits() methods.




















