






















































While the theoretical concepts discussed previously have been with us for decades now, a few things have recently been changing very rapidly. There is an ever increasing amount of complexity in software products. For example, in object-oriented programming, we might start off with a clean interface between two classes, but during a sprint, under extra time pressure, a developer might cut corners and introduce a coupling between classes. Such a technical debt is rarely paid back on its own; it starts to accumulate until our initial design objective is no longer perceivable at all!
Another thing that's changing is that products are rarely built in isolation now; they make heavy use of services provided by external entities. A vivid example of this is found in managed services in cloud environments, such as Amazon Web Services (AWS). In AWS, there is a service for everything, from a database to one that enables building a chatbot.
It has become imperative that we try to enforce separation of concerns. Interactions and contracts between components are becoming increasingly Application Programming Interface (API)-driven. Components don't share memory, hence they can only communicate via network calls. Such components are called as services. A service takes requests from clients and fulfills them. Clients don't care about the internals of the service. A service can be a client for another service.
A typical initial architecture of a system is shown here:

The system can be broken into three distinct layers:
- Frontend (a mobile application or a web page): This is what the users interact with and makes network classes go to the backend to get data and enable behavior.
- Backend piece: This layer has the business logic for handling specific requests. This code is generally supposed to be ignorant of the frontend specifics (such as whether it is an application or a web page making the call).
- A data store: This is the repository for persistent data.
In the early stages, when the team (or company) is young, and people start developing with a greenfield environment and the number of developers is small, things work wonderfully and there is good development velocity and quality. Developers pitch in to help other developers whenever there are any issues, since everyone knows the system components at some level, even if they're not the developer responsible for the component. However, as the company grows, the product features start to multiply, and as the team gets bigger, four significant things happen:
- The code complexity increases exponentially and the quality starts to drop. A lot of dependencies spurt up between the current code and new features being developed, while bug fixes are made to current code. New developers don't have context into the tribal knowledge of the team and the cohesive structure of the code base starts to break.
- Operational work (running and maintaining the application) starts taking a significant amount time for the team. This usually leads to the hiring of operational engineers (DevOps engineers) who can independently take over operations work and be on call for any issues. However, this leads to developers losing touch with production, and we often see classic issues, such as it works on my setup but fails in production.
- The third thing that happens is the product hitting scalability limits. For example, the database may not meet the latency requirements under increased traffic. We might discover that an algorithm that was chosen for a key business rule is getting very latent. Things that were working well earlier suddenly start to fail, just because of the increased amount of data and requests.
- Developers start writing huge amounts of tests to have quality gates. However, these regression tests become very brittle with more and more code being added. Developer productivity falls off a cliff.
Applications that are in this state are called monoliths. Sometimes, being a monolith is not bad (for example, if there are stringent performance/latency requirements), but generally, the costs of being in this state impact the product very negatively. One key idea, which has become prevalent to enable software to scale, has been microservices, and the paradigm is more generally called service-oriented architecture (SOA).
The basic concept of a microservice is simple—it's a simple, standalone application that does one thing only and does that one thing well. The objective is to retain the simplicity, isolation, and productivity of the early app. A microservice cannot live alone; no microservice is an island—it is part of a larger system, running and working alongside other microservices to accomplish what would normally be handled by one large standalone application.
Each microservice is autonomous, independent, self-contained, and individually deployable and scalable. The goal of microservice architecture is to build a system composed of such microservices.
The core difference between a monolithic application and microservices is that a monolithic application will contain all features and functions within one application (code base) deployed at the same time, with each server hosting a complete copy of the entire application, while a microservice contains only one function or feature, and lives in a microservice ecosystem along with other microservices:
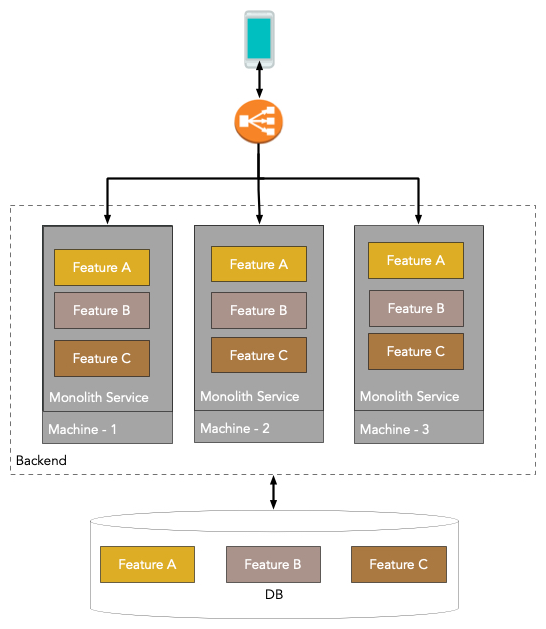
Here, there is one deployable artifact, made from one application code base that contains all of the features. Every machine runs a copy of the same code base. The database is shared and usually leads to non-explicit dependencies (Feature A requires Feature B to maintain a Table X using a specific schema, but nobody told the Feature B team!)
Contrast this with a microservices application:
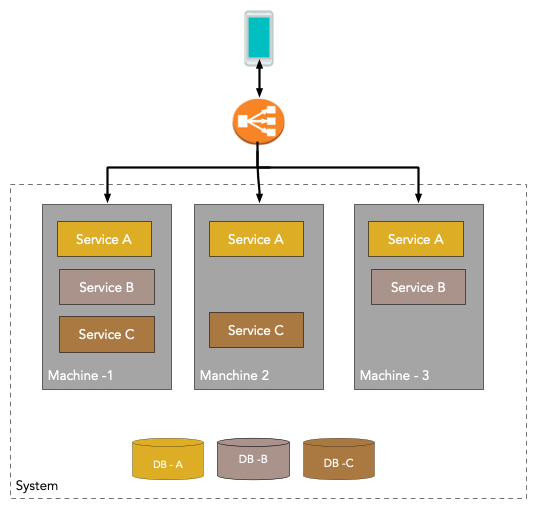
Here, in it's canonical form, every feature is itself packaged as a service, or a microservice, to be specific. Each microservice is individually deployable and scalable and has its own separate database.
To summarize, microservices bring a lot to the table:
- They allow us to use the componentization strategy (that is, divide and rule) more effectively, with clear boundaries between components.
- There's the ability to create the right tool for each job in a microservice.
- It ensures easier testability.
- There's improved developer productivity and feature velocity.








