























































Opening an Excel sheet from Python and reading the data
When working with Excel files in Python, it’s common to need to open a specific sheet and read the data into Python for further analysis. This can be achieved using popular libraries such as pandas and openpyxl, as discussed in the previous section.
You can most likely use other Python and package versions, but the code in this section has not been tested with anything other than what we’ve stated here.
Using pandas
pandas is a powerful data manipulation library that simplifies the process of working with structured data, including Excel spreadsheets. To read an Excel sheet using pandas, you can use the read_excel function. Let’s consider an example of using the iris_data.xlsx file with a sheet named setosa:
import pandas as pd
# Read the Excel file
df = pd.read_excel('iris_data.xlsx', sheet_name='setosa')
# Display the first few rows of the DataFrame
print(df.head()) You will need to run this code either with the Python working directory set to the location where the Excel file is located, or you will need to provide the full path to the file in the read_excel() command:
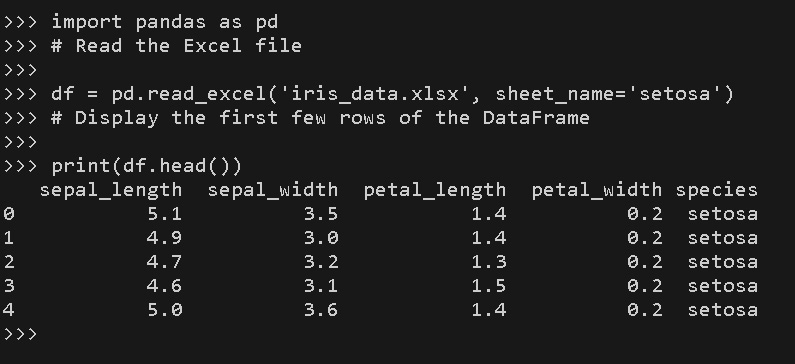
Figure 1.6 – Using the pandas package to read the Excel file
In the preceding code snippet, we imported the pandas library and utilized the read_excel function to read setosa from the iris_data.xlsx file. The resulting data is stored in a pandas DataFrame, which provides a tabular representation of the data. By calling head() on the DataFrame, we displayed the first few rows of the data, giving us a quick preview.
Using openpyxl
openpyxl is a powerful library for working with Excel files, offering more granular control over individual cells and sheets. To open an Excel sheet and access its data using openpyxl, we can utilize the load_workbook function. Please note that openpyxl cannot handle .xls files, only the more modern .xlsx and .xlsm versions.
Let’s consider an example of using the iris_data.xlsx file with a sheet named versicolor:
import openpyxl
import pandas as pd
# Load the workbook
wb = openpyxl.load_workbook('iris_data.xlsx')
# Select the sheet
sheet = wb['versicolor']
# Extract the values (including header)
sheet_data_raw = sheet.values
# Separate the headers into a variable
header = next(sheet_data_raw)[0:]
# Create a DataFrame based on the second and subsequent lines of data with the header as column names
sheet_data = pd.DataFrame(sheet_data_raw, columns=header)
print(sheet_data.head()) The preceding code results in the following output:
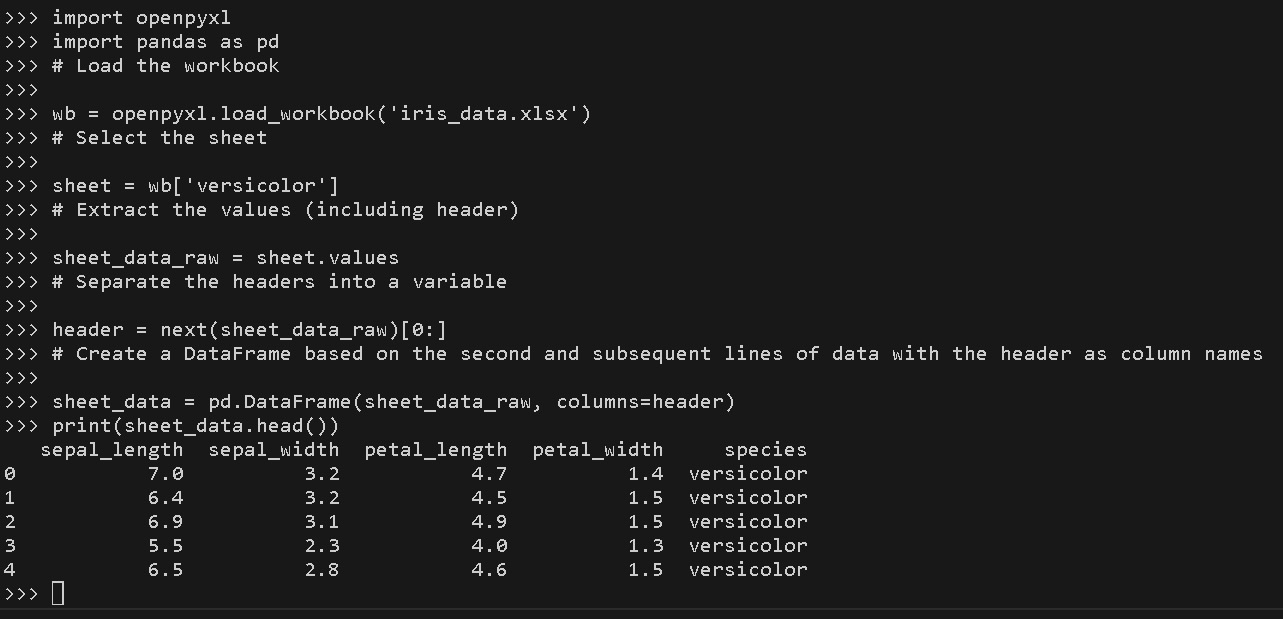
Figure 1.7 – Using the openpyxl package to read the Excel file
In this code snippet, we import the load_workbook function from the openpyxl library. Then, we load the workbook by providing the iris_data.xlsx filename. Next, we select the desired sheet by accessing it using its name – in this case, this is versicolor. Once we’ve done this, we read the raw data using the values property of the loaded sheet object. This is a generator and can be accessed via a for cycle or by converting it into a list or a DataFrame, for example. In this example, we have converted it into a pandas DataFrame because it is the format that is the most comfortable to work with later.
Both pandas and openpyxl offer valuable features for working with Excel files in Python. While pandas simplifies data manipulation with its DataFrame structure, openpyxl provides more fine-grained control over individual cells and sheets. Depending on your specific requirements, you can choose the library that best suits your needs.
By mastering the techniques of opening Excel sheets and reading data into Python, you will be able to extract valuable insights from your Excel data, perform various data transformations, and prepare it for further analysis or visualization. These skills are essential for anyone seeking to leverage the power of Python and Excel in their data-driven workflows.











