






















































A little history
Deno's first stable version, v1.0.0, was launched on the May 13, 2020.
The first time Ryan Dahl – Node.js creator – mentioned it was in his famous talk, 10 things I regret about node.js (https://youtu.be/M3BM9TB-8yA). Apart from the fact that it presents the first very alpha version of Deno, it is a talk worth watching as a lesson on how software ages. It is an excellent reflection on how decisions evolve, even when they're made by some of the smartest people in the open source community, and how they can end up in a different place than what they initially planned for.
After the launch, in May 2020 and due to its historical background, its core team, and the fact that it appeals to the JavaScript community, Deno has been getting lots of attention. That's probably one way you've heard about it, be it via blog posts, tweets, or conference talks.
This enthusiasm is having positive consequences on its runtime, with lots of people wanting to contribute and use it. The community is growing due to its Discord channel (https://discord.gg/deno) and the number of pull requests on Deno's repositories (https://github.com/denoland). It is currently evolving at a cadence of one minor version per month, with lots of bug fixes and improvements being shipped. The roadmap shows a vision for a future that is no less exciting than the present. With a well-defined path and set of principles, Deno has everything it takes to become more significant by the day.
Let's rewind a little and go back to 2009 and the creation of Node.js.
At the time, Ryan started by questioning how most backend languages and frameworks were dealing with I/O (input/output). Most of the tools were looking at I/O as an synchronous operation, blocking the process until it is done, and only then continuing to execute the code.
Fundamentally, it was this synchronous blocking operation that Ryan questioned.
Handling I/O
When you are writing servers that must deal with thousands of requests per second, resource consumption and speed are two significant factors.
For such resource-critical projects, it is important that the base tools – the primitives – have an architecture that is accounting for this. When the time to scale arises, it helps that the fundamental decisions you made at the beginning support that.
Web servers are one of those cases. The web is a significant platform in today's world. It never stops growing, with more devices and new tools accessing the internet daily, making it accessible to more people. The web is the common, democratized, decentralized ground for people around the world. With this in mind, the servers behind those applications and websites need to handle giant loads. Web applications such as Twitter, Facebook, and Reddit, among many others, deal with thousands of requests per minute. So, scale is essential.
To kickstart a conversation about performance and resource efficiency, let's look at the following graph, which is comparing two of the most used open-source web servers: Apache and Nginx:
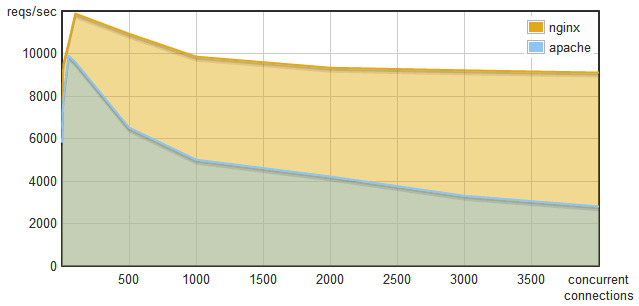
Figure 1.1 – Requests per second versus concurrent connections – Nginx versus Apache
At first glance, this tells us that Nginx comes out on top pretty much every time. We can also understand that, as the number of concurrent connections increases, Apache's number of requests per second decreases. Comparatively, Nginx keeps the number of requests per second pretty stable, despite also showing an expected drop in requests per second as the number of connections grows. After reaching a thousand concurrent connections, Nginx gets close to double the number of Apache's requests per second.
Let's look at a comparison of the RAM memory consumption:
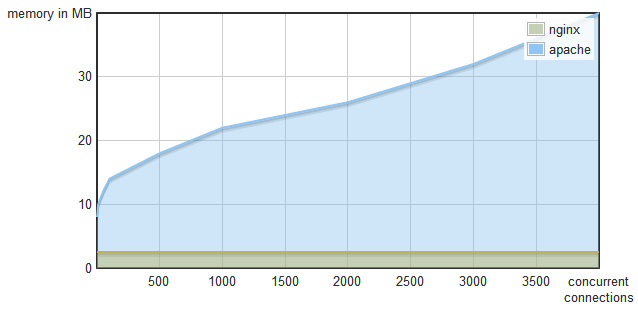
Figure 1.2 – Memory consumption versus concurrent connections – Nginx versus Apache
Apache's memory consumption grows linearly with the number of concurrent connections, while Nginx's memory footprint is constant.
You might already be wondering why this happens.
This happens because Apache and Nginx have very different ways of dealing with concurrent connections. Apache spawns a new thread per request, while Nginx uses an event loop.
In a thread-per-request architecture, it creates a thread every time a new request comes in. That thread is responsible for handling the request until it finishes. If another request comes while the previous one is still being handled, a new thread is created.
On top of this, handling networking on threaded environments is not known as something particularly easy to do. You can incur in file and resource locking, thread communication issues, and common problems such as deadlocks. Adding to the difficulties presented to the developer, using threads does not come for free, as threads by themselves have a resource overhead.
In contrast, in an event loop architecture, everything happens on a single thread. This decision dramatically simplifies the lives of developers. You do not have to account for the factors mentioned previously, which means more time to deal with your users' problems.
By using this pattern, the web server just sends events to the event loop. It is an asynchronous queue that executes operations when there are available resources, returning to the code asynchronously when these operations finish. For this to work, all the operations need to be non-blocking, meaning they shouldn't wait for completion and just send an event and wait for a response later.
Blocking versus non-blocking
Take, for instance, reading a file. In a blocking environment, you would read the file and have the process waiting for it to finish until you execute the next line of code. While the operating system is reading the file's contents, the program is in an idle state, wasting valuable CPU cycles:
const result = readFile('./README.md');
// Use result
The program will wait for the file to be read and only then it will continue executing the code.
The same operation using an event loop would be to trigger the "read the file" event and execute other tasks (for instance, handling other requests). When the file reading operation finishes, the event loop will call the callback function with the result. This time, the runtime uses the CPU cycles to handle other requests while the OS retrieves the file's contents, making better use of the resources:
const result = readFileAsync('./README.md', function(result) {
// Use result
});
In this example, the task gets a callback assigned to it. When the job is complete (this might take seconds or milliseconds), it calls back the function with the result. When this function is called, the code inside runs linearly.
Why aren't event loops used more often?
Now that we understand the advantages of event loops, this is a very plausible question. One of the reasons event loops are not used more, even though there are some implementations in Python and Ruby, is that they require all the infrastructure and code to be non-blocking. Being non-blocking means being prepared not to execute the code synchronously. It means triggering events and dealing with the result later, at some point in time.
On top of all of that, many of the commonly used languages and libraries do not provide asynchronous APIs. Callbacks are not present in many languages, and anonymous functions do not exist in programming languages such as C. Crucial pieces of today's software, such as libmysqlclient, do not support asynchronous operations, even though part of its internals might use asynchronous task execution. Asynchronous DNS resolution is another example that's also not a standard in many systems. As another example, you might take, for instance, the manual pages of operating systems. Most of them don't even provide us with a way to understand if a particular function does I/O or not. These are all evidences that the ability to make asynchronous I/O is not present in many of today's fundamental software pieces.
Even the existing tools that provide these features require developers to have a deep understanding of asynchronous I/O patterns to use event loops. It's a difficult job to wire up these existing solutions to get something to work while going around technical limitations, such as the ones shown in the libmysqlclient example.
JavaScript to the rescue
JavaScript was a language created by Brendan Eich in 1995 while working for Netscape. It initially only ran in browsers and allowed developers to add interactive features to web pages. It is composed of elements that revealed themselves as perfect for the event loop:
- It has anonymous functions and closures.
- It only executes one callback at a time.
- I/O is done on DOM via callbacks (for example,
addEventListener).
Combining these three fundamental aspects of the language made the event loop something natural to anyone used to JavaScript in the browser.
The language's features ended up gearing its developers toward event-driven programming.
Node.js enters the scene
After all these thoughts and questions about I/O and how it should be dealt with, Ryan Dahl came up with Node.js in 2009. It is a JavaScript runtime, based on Google's V8 – a JavaScript engine that brings JavaScript to the server.
Node.js is asynchronous and single-threaded by design. It has an event loop at its core and presents itself as a scalable way to develop backend applications that handle thousands of concurrent requests.
Event loops provide us with a clean way to deal with concurrency, a topic where Node.js contrasts with tools such as PHP or Ruby, which use the thread-per-request model. This single-threaded environment grants Node.js users the simplicity of not caring about thread-safety problems. It very much succeeds in abstracting the event loop and all the issues with synchronous tools from the user, requiring little to no knowledge about the event loop itself. Node.js does this by leveraging callbacks and, more recently, the use of promises.
Node.js positioned itself as a way to provide a low-level, purely evented, non-blocking infrastructure for users to program their applications.
Node.js' rise
Telling companies and developers that they could leverage their JavaScript knowledge to write servers rapidly resulted in a Node.js popularity rise.
It didn't take much time for the language to evolve fast since it was released and started being used in production by companies of all sizes.
Just 2 years after its creation, in 2011, Uber and LinkedIn were already running JavaScript on the server. In 2012, Ryan Dahl resigned from the Node.js community's day-to-day operations to dedicate himself to research and other projects.
Estimates say that, in 2017, there were more than 8.8 million instances of Node.js running (source: https://blog.risingstack.com/history-of-node-js/). Today, more than 103 billion packages have been downloaded from Node Package Manager (npm), and there are around 1,467,527 packages published.
Node.js is a great platform, there's no questions about that. Pretty much anyone who has used it has experienced many of its advantages. Popularity and community play a significant role in this. Having a lot of people of very different experience levels and backgrounds working with a piece of technology can only push it forward. That's what happened – and still happens – with Node.js.
Node.js enabled developers to use JavaScript for lots of varying use cases that weren't possible previously. This ranged from robotics, to cryptocurrencies, to code bundlers, APIs, and more. It is a stable environment where developers feel productive and fast. It will continue its job, supporting companies and businesses of different sizes for many years to come.
But you've bought this book, so you must believe that Deno has something worth exploring, and I can guarantee that it does.
You might be wondering, why bring a new solution to the table when the previous one is more than satisfactory? That's what we'll discover next.



