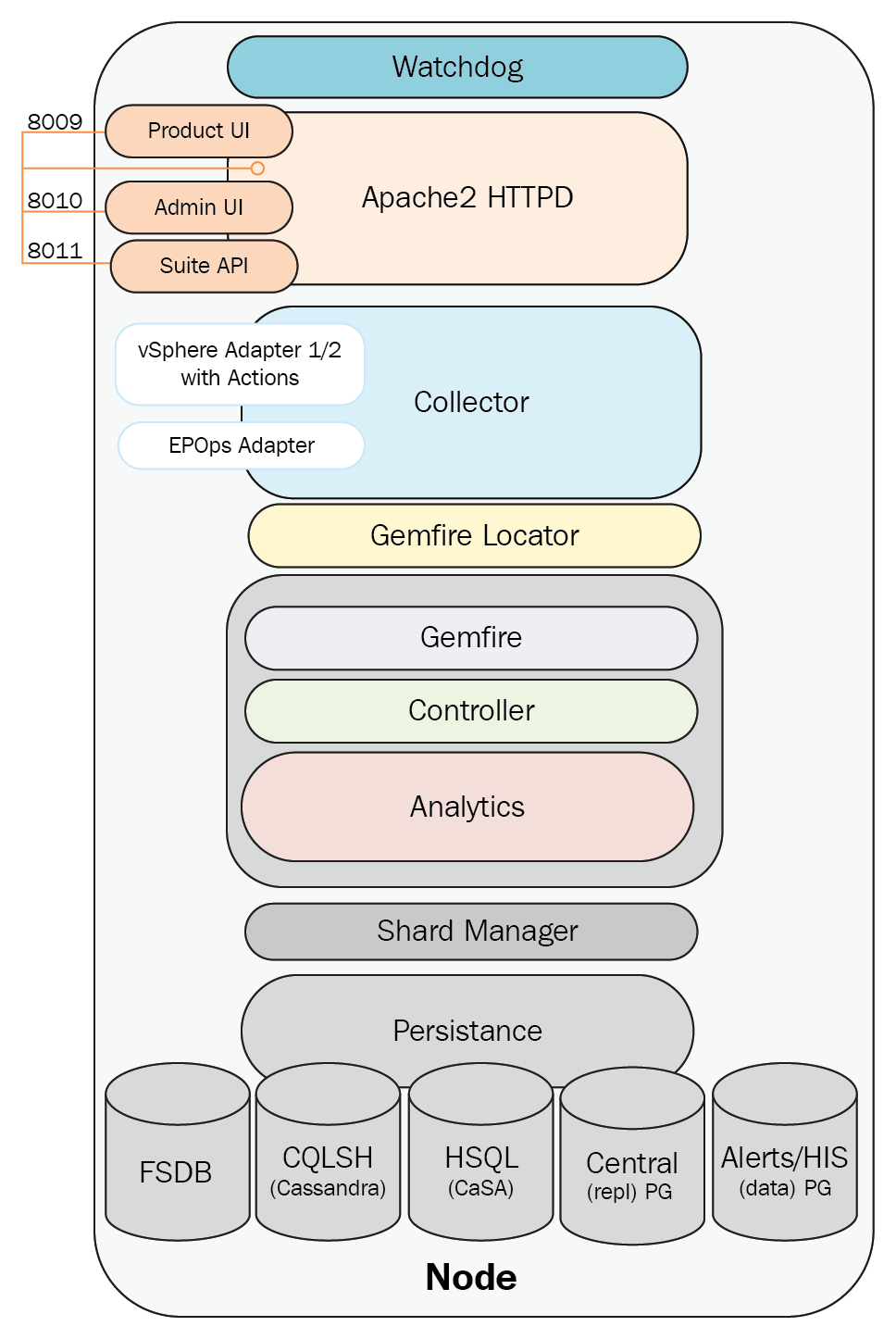
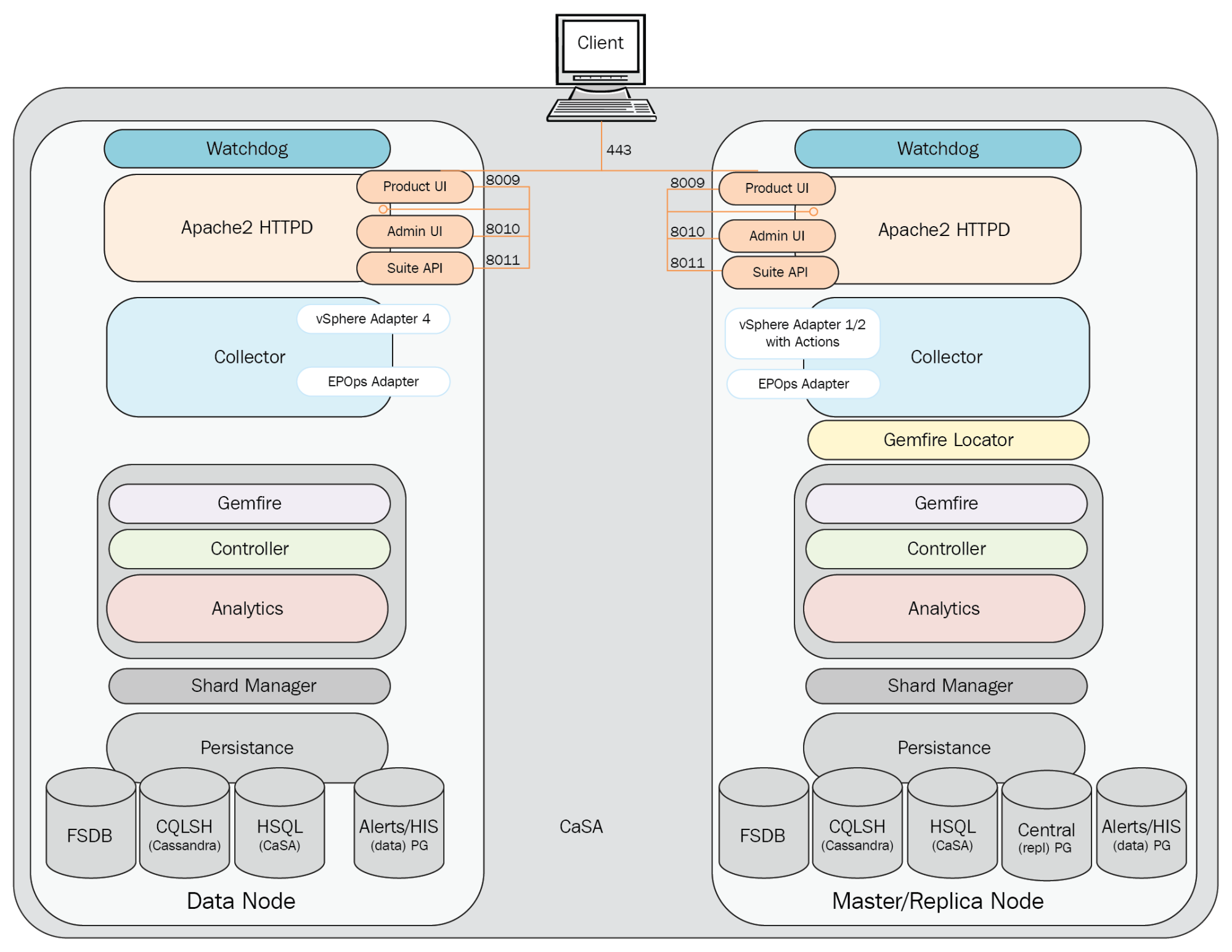
The Collector process is responsible for pulling in inventory and metric data from the configured sources. As shown in the following diagram, the Collector uses adapters to collect data from various sources, and then contacts the GemFire locator for connection information to one or more Controller cache servers. The Collector service then connects to one or more Controller API GemFire cache servers, and sends the collected data.
It is important to note that although an instance of an adapter can only be running on one node at a time, it does not imply that the collected data is being sent to the Controller on that node.
The Collector will send a heartbeat to the Controller every 30 seconds. This is sent via the HeartbeatThread thread process running on the Collector. It has a maximum of 25 data collection threads. Vice versa, the Controller node, vice versa, runs a HeartbeatServer thread process which processes heartbeats from Collectors. The CollectorStatusChecker thread process is a DistributedTask which uses data from HeartbeatServers to decides whether the Collector is up or down.
By default, the Collector will wait for 30 minutes for adapters to synchronize.
The Collector properties, including enabling or disabling the self-protection, can be configured from the collector.properties properties file located in /usr/lib/vmware-vcops/user/conf/collector.
The vSphere adapter provides the Collector process with the configuration information needed to pull in vCenter inventory and metric data. It consists of configuration files and a JAR file. A separate adapter instance is configured for each vCenter Server.
The Python adapter provides the Collector process with the configuration information needed to send remediation commands back to a vCenter Server (power on/off VM, vMotion VM, reconfigure VM, and so on).
The End Point Operations Management adapter is installed and listening by default on each vRealize Operations node. To receive data from operating systems, the agent must be installed and configured on each guest OS to be monitored.
The Horizon adapter provides the Collector process with the configuration information needed to pull in the Horizon View inventory and metric data. A separate adapter instance is configured for each Horizon View pod, and only one adapter instance is supported per vRealize Operations node with a limit of 10,000 Horizon objects: