






















































The following diagram shows potential data sources for Apache Streaming, such as Kafka, Flume, and HDFS:
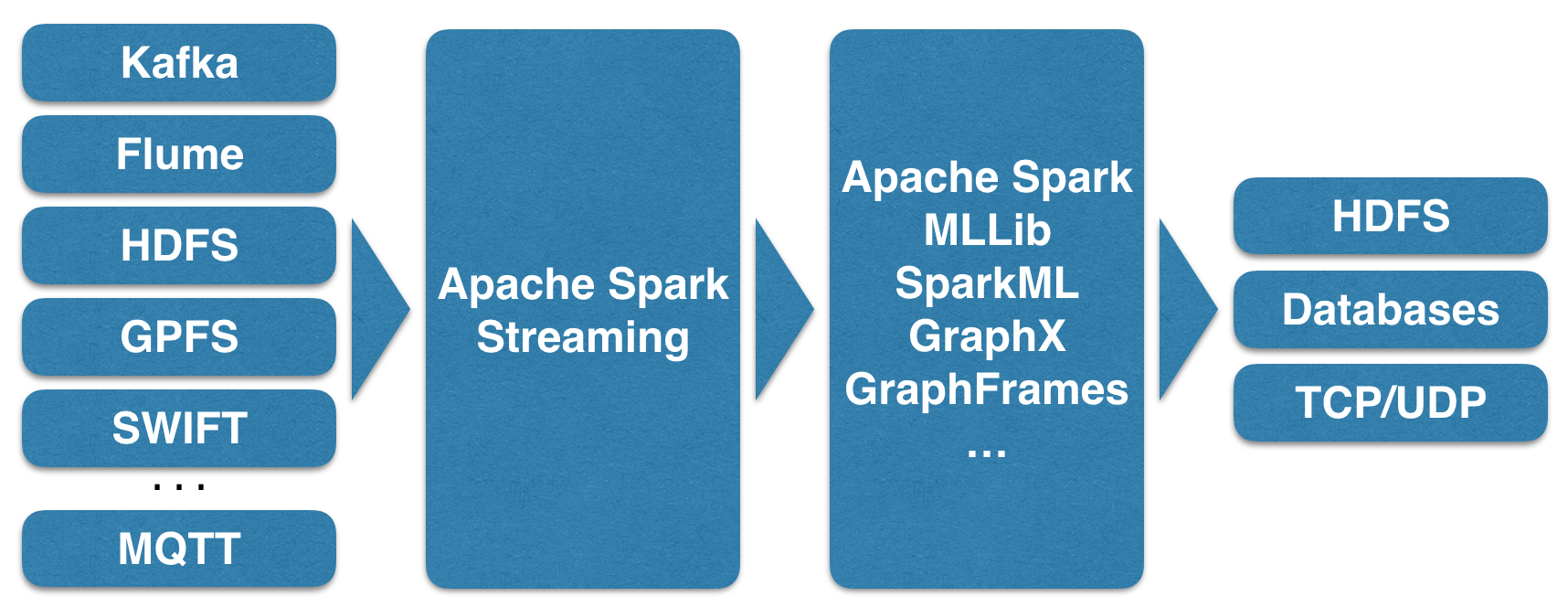
These feed into the Spark Streaming module and are processed as Discrete Streams. The diagram also shows that other Spark module functionality, such as machine learning, can be used to process stream-based data.
The fully processed data can then be an output for HDFS, databases, or dashboards. This diagram is based on the one at the Spark streaming website, but we wanted to extend it to express the Spark module functionality:

When discussing Spark Discrete Streams, the previous figure, taken from the Spark website at http://spark.apache.org/, is the diagram that we would like to use.
The green boxes in the previous figure show the continuous data stream sent to Spark being broken down into a Discrete Stream (DStream).





