






















































Understanding spam detection
A spam detector is software that runs on the mail server or our local computer and checks the inbox to detect possible spam. As with traditional letterboxes, an inbox is a destination for electronic mail messages. Generally, any spam detector has unhindered access to this repository and can perform tens, hundreds, or even thousands of checks per day to decide whether an incoming email is spam or not. Fortunately, spam detection is a ubiquitous technology that filters out irrelevant and possibly dangerous electronic correspondence.
How would you implement such a filter from scratch? Before exploring the steps together, look at a contrived (and somewhat naive) spam email message in Figure 2.1. Can you identify some key signs that differentiate this spam from a non-spam email?
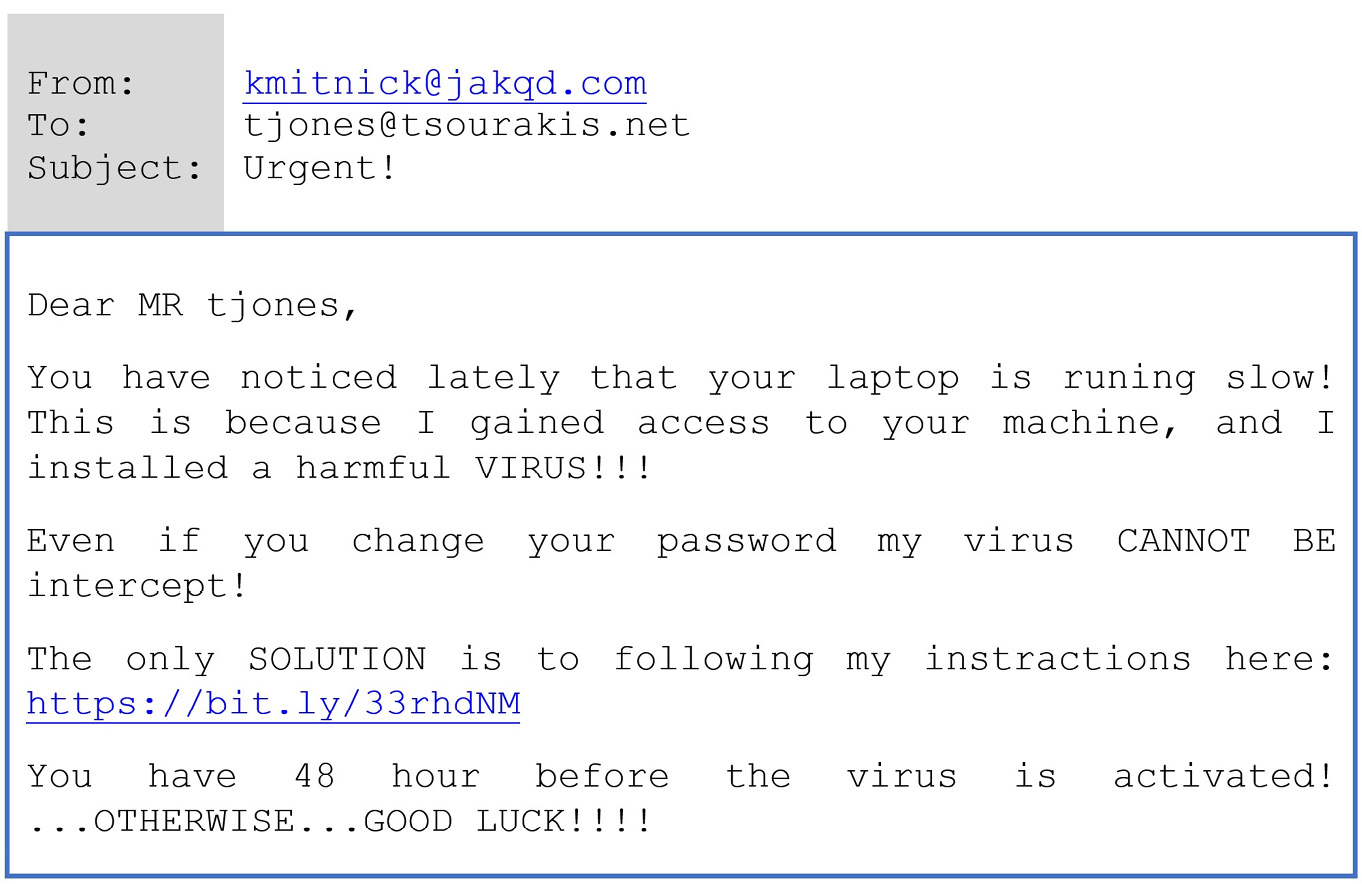
Figure 2.1 – A spam email message
Even before reading the content of the message, most of you can immediately identify the scam from the email’s subject field and decide not to open it in the first place. But let’s consider a few signs (coded as T1 to T4) that can indicate a malicious sender:
T1– The text in the subject field is typical for spam. It is characterized by a manipulative style that creates unnecessary urgency and pressure.T2– The message begins with the phrase Dear MR tjones. The last word was probably extracted automatically from the recipient’s email address.T3– Bad spelling and the incorrect use of grammar are potential spam indicators.T4– The text in the body of the message contains sequences with multiple punctuation marks or capital letters.
We can implement a spam detector based on these four signs, which we will hereafter call triggers. The detector classifies an incoming email as spam if T1, T2, T3, and T4 are True simultaneously. The following example shows the pseudocode for the program:
IF (subject is typical for spam)
AND IF (message uses recipients email address)
AND IF (spelling and grammar errors)
AND IF (multiple sequences of marks-caps) THEN
print("It's a SPAM!")
It’s a no-brainer that this is not the best spam filter ever built. We can predict that it blocks legitimate emails and lets some spam messages escape uncaught. We have to include more sophisticated triggers and heuristics to improve its performance in terms of both types of errors. Moreover, we need to be more specific about the cut-off thresholds for the triggers. For example, how many spelling errors (T3) and sequences (T4) make the relevant expressions in the pseudocode True? Is T3 an appropriate trigger in the first place? We shouldn’t penalize a sender for being bad at spelling! Also, what happens when a message includes many grammar mistakes but contains few sequences with capital letters? Can we still consider it spam? To answer these questions, we need data to support any claim. After examining a large corpus of messages annotated as spam or non-spam, we can safely extract the appropriate thresholds and adapt the pseudocode.
Can you think of another criterion? What about examining the message’s body and checking whether certain words appear more often? Intuitively, those words can serve as a way to separate the two types of emails. An easy way to perform this task is to visualize the body of the message using word clouds (also known as tag clouds). With this visualization technique, recurring words in the dataset (excluding articles, pronouns, and a few other cases) appear larger than infrequent ones.
One possible implementation of word clouds in Python is the word_cloud module (https://github.com/amueller/word_cloud). For example, the following code snippet presents how to load the email shown in Figure 2.1 from the spam.txt text file (https://github.com/PacktPublishing/Machine-Learning-Techniques-for-Text/tree/main/chapter-02/data), make all words lowercase, and extract the visualization:
# Import the necessary modules.
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# Read the text from the file spam.txt.
text = open('./data/spam.txt').read()
# Create and configure the word cloud object.
wc = WordCloud(background_color="white", max_words=2000)
# Generate the word cloud image from the text.
wordcloud = wc.generate(text.lower())
# Display the generated image.
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
Figure 2.2 shows the output plot:
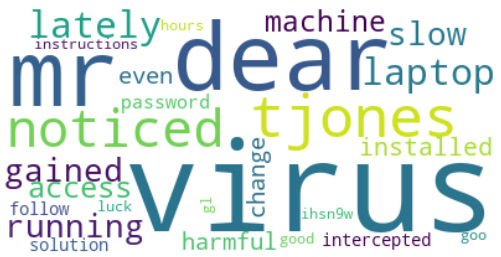
Figure 2.2 – A word cloud of the spam email
The image suggests that the most common word in our spam message is virus (all words are lowercase). Does the repetition of this word make us suspicious? Let’s suppose yes so that we can adapt the pseudocode accordingly:
...
AND IF (multiple sequences of marks-caps) THEN
AND IF (common word = "virus") THEN
print("It's a SPAM!")
Is this new version of the program better? Slightly. We can engineer even more criteria, but the problem becomes insurmountable at some point. It is not realistic to find all the possible suspicious conditions and deciphering the values of all thresholds by hand becomes an unattainable goal.
Notice that techniques such as word clouds are commonplace in ML problems to explore text data before resorting to any solution. We call this process Exploratory Data Analysis (EDA). EDA provides an understanding of where to direct our subsequent analysis and visualization methods are the primary tool for this task. We deal with this topic many times throughout the book.
It’s time to resort to ML to overcome the previous hurdles. The idea is to train a model from a corpus with labeled examples of emails and automatically classify new ones as spam or non-spam.
Explaining feature engineering
If you were being observant, you will have spotted that the input to the pseudocode was not the actual text of the message but the information extracted from it. For example, we used the frequency of the word virus, the number of sequences in capital letters, and so on. These are called features and the process of eliciting them is called feature engineering. For many years, this has been the central task of ML practitioners, along with calibrating (fine-tuning) the models.
Identifying a suitable list of features for any ML task requires domain knowledge – comprehending the problem you want to solve in-depth. Furthermore, how you choose them directly impacts the algorithm’s performance and determines its success to a significant degree. Feature engineering can be challenging, as we can overgenerate items in the list. For example, certain features can overlap with others, so including them in the subsequent analysis is redundant. On the other hand, specific features might be less relevant to the task because they do not accurately represent the underlying problem. Table 2.1 includes a few examples of good features:
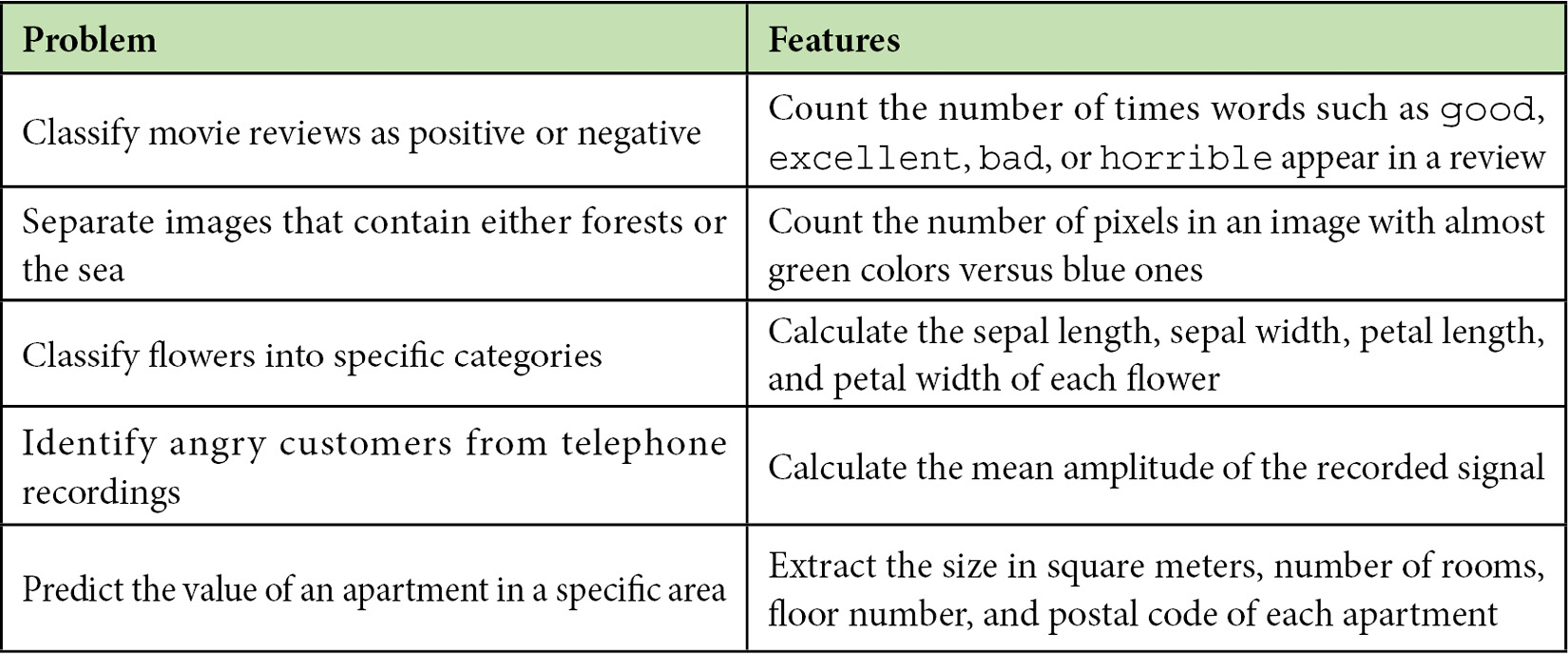
Table 2.1 – Examples of feature engineering
Given the preceding table, the rationale for devising features for any ML problem should be clear. First, we need to identify the critical elements of the problem under study and then decide how to represent each element with a range of values. For example, the value of an apartment is related to its size in square meters, which is a real positive number.
This section provided an overview of spam detection and why attacking this problem using traditional programming techniques is suboptimal. The reason is that identifying all the necessary execution steps manually is unrealistic. Then, we debated why extracting features from data and applying ML is more promising. In this case, we provide hints (as a list of features) to the program on where to focus, but it’s up to the algorithm to identify the most efficient execution steps.
The following section discusses how to extract the proper features in problems involving text such as emails, tweets, movie reviews, meeting transcriptions, or reports. The standard approach, in this case, is to use the actual words. Let’s see how.
