























































Data formats
In a supervised learning problem, there will always be a dataset, defined as a finite set of real vectors with m features each:
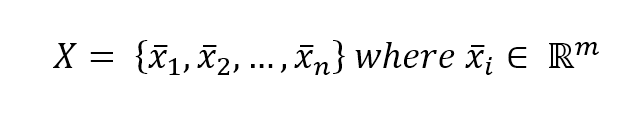
Considering that our approach is always probabilistic, we need to consider each X as drawn from a statistical multivariate distribution D. For our purposes, it's also useful to add a very important condition upon the whole dataset X: we expect all samples to be independent andidentically distributed (i.i.d). This means all variables belong to the same distribution D, and considering an arbitrary subset of m values, it happens that:

The corresponding output values can be both numerical-continuous or categorical. In the first case, the process is called regression, while in the second, it is called classification. Examples of numerical outputs are:

Categorical examples are:

We define generic regressor, a vector-valued function which associates an input value to a continuous output and generic classifier, a vector-values function whose predicted output is...





















