






















































Running Spark on EC2
Till Spark 2.0.0, the ec2 directory contained the script to run a Spark cluster in EC2. From 2.0.0, the ec2 scripts have been moved to an external repository hosted by the UC Berkeley AMPLab. These scripts can be used to run multiple Spark clusters and even run on-the-spot instances. Spark can also be run on Elastic MapReduce (Amazon EMR), which is Amazon's solution for MapReduce cluster management, and it gives you more flexibility around scaling instances. The UCB AMPLab page at https://github.com/amplab/spark-ec2 has the latest onrunning Spark on EC2.
Tip
The Stack Overflow page at http://stackoverflow.com/questions/38611573/how-to-launch-spark-2-0-on-ec2 is a must-read before attempting to run Spark on EC2. The blog at https://medium.com/@eyaldahari/how-to-set-apache-spark-cluster-on-amazon-ec2-in-a-few-simple-steps-d29f0d6f1a81#.8wfa4vqbl also has some good tips for running Spark in EC2.
Downloading EC-scripts
There are many ways you can get the scripts. The best way is to download the .zip file from the AMPLab GitHub, unzip it, and move it from the ec2 directory to the spark-2.0.0 directory. In this way, things will work as before and are contained in the spark directory.
Tip
Remember to repeat this, that is, download the .zip file, and then move the ec2 directory, when you download newer versions of spark, say spark-2.1.0.
You can download a .zip file from GitHub, as shown here:
Perform the following steps:
- Download the
.zipfile from GitHub to, say~/Downloads(or another equivalent directory). - Run this command to unzip the files:
unzip spark-ec2-branch-1.6.zip - Rename the subdirectory:
mv spark-ec2-branch-1.6 ec2 - Move the directory under
spark-2.0.0:mv ~/Downloads/ec2 /opt/spark-2.0.0/ - Viola! It is as if the
ec2directory was there all along!
Running Spark on EC2 with the scripts
To get started, you should make sure you have EC2 enabled on your account by signing up at https://portal.aws.amazon.com/gp/aws/manageYourAccount. Then it is a good idea to generate a separate access key pair for your Spark cluster, which you can do at https://portal.aws.amazon.com/gp/aws/securityCredentials. You will also need to create an EC2 key pair so that the Spark script can SSH to the launched machines, which can be done at https://console.aws.amazon.com/ec2/home by selecting Key Pairs under NETWORK & SECURITY. Remember that key pairs are created per region and so you need to make sure that you create your key pair in the same region as you intend to run your Spark instances. Make sure to give it a name that you can remember as you will need it for the scripts (this chapter will use spark-keypair as its example key pair name.). You can also choose to upload your public SSH key instead of generating a new key. These are sensitive; so make sure that you keep them private. You also need to set AWS_ACCESS_KEY and AWS_SECRET_KEY as environment variables for the Amazon EC2 scripts:
chmod 400 spark-keypair.pem export AWS_ACCESS_KEY=AWSACcessKeyId export AWS_SECRET_KEY=AWSSecretKey
You will find it useful to download the EC2 scripts provided by Amazon from http://docs.aws.amazon.com/AWSEC2/latest/CommandLineReference/set-up-ec2-cli-linux.html. Once you unzip the resulting .zip file, you can add bin to PATH in a manner similar to the way you did with the Spark bin instance:
wget http://s3.amazonaws.com/ec2-downloads/ec2-api-tools.zip unzip ec2-api-tools.zip cd ec2-api-tools-* export EC2_HOME='pwd' export PATH=$PATH:'pwd'/bin
In order to test whether this works, try the following command:
$ec2-describe-regions
This command will display the output shown in the following screenshot:

Finally, you can refer to the EC2 command-line tool reference page at http://docs.aws.amazon.com/AWSEC2/latest/CommandLineReference/set-up-ec2-cli-linux.html as it has all the gory details.
The Spark EC2 script automatically creates a separate security group and firewall rules for running the Spark cluster. By default, your Spark cluster will be universally accessible on port 8080, which is somewhat poor. Sadly, the spark_ec2.py script does not currently provide an easy way to restrict access to just your host. If you have a static IP address, I strongly recommend limiting access in spark_ec2.py; simply replace all instances of 0.0.0.0/0 with [yourip]/32. This will not affect intra-cluster communication as all machines within a security group can talk to each other by default.
Next, try to launch a cluster on EC2:
./ec2/spark-ec2 -k spark-keypair -i pk-[....].pem -s 1 launch myfirstcluster
Tip
If you get an error message, such as The requested Availability Zone is currently constrained and…, you can specify a different zone by passing in the --zone flag.
The -i parameter (in the preceding command line) is provided for specifying the private key to log into the instance; -i pk-[....].pem represents the path to the private key.
If you get an error about not being able to SSH to the master, make sure that only you have the permission to read the private key, otherwise SSH will refuse to use it.
You may also encounter this error due to a race condition, when the hosts report themselves as alive but the spark-ec2 script cannot yet SSH to them. A fix for this issue is pending in https://github.com/mesos/spark/pull/555. For now, a temporary workaround until the fix is available in the version of Spark you are using is to simply sleep an extra 100 seconds at the start of setup_cluster using the -w parameter. The current script has 120 seconds of delay built in.
If you do get a transient error while launching a cluster, you can finish the launch process using the resume feature by running the following command:
./ec2/spark-ec2 -i ~/spark-keypair.pem launch myfirstsparkcluster --resume
Refer to the following screenshot:

It will go through a bunch of scripts, thus setting up Spark, Hadoop, and so forth. If everything goes well, you will see something like the following screenshot:

This will give you a barebones cluster with one master and one worker with all of the defaults on the default machine instance size. Next, verify that it started up and your firewall rules were applied by going to the master on port 8080. You can see in the preceding screenshot that the UI for the master is the output at the end of the script with port at 8080 and ganglia at 5080.
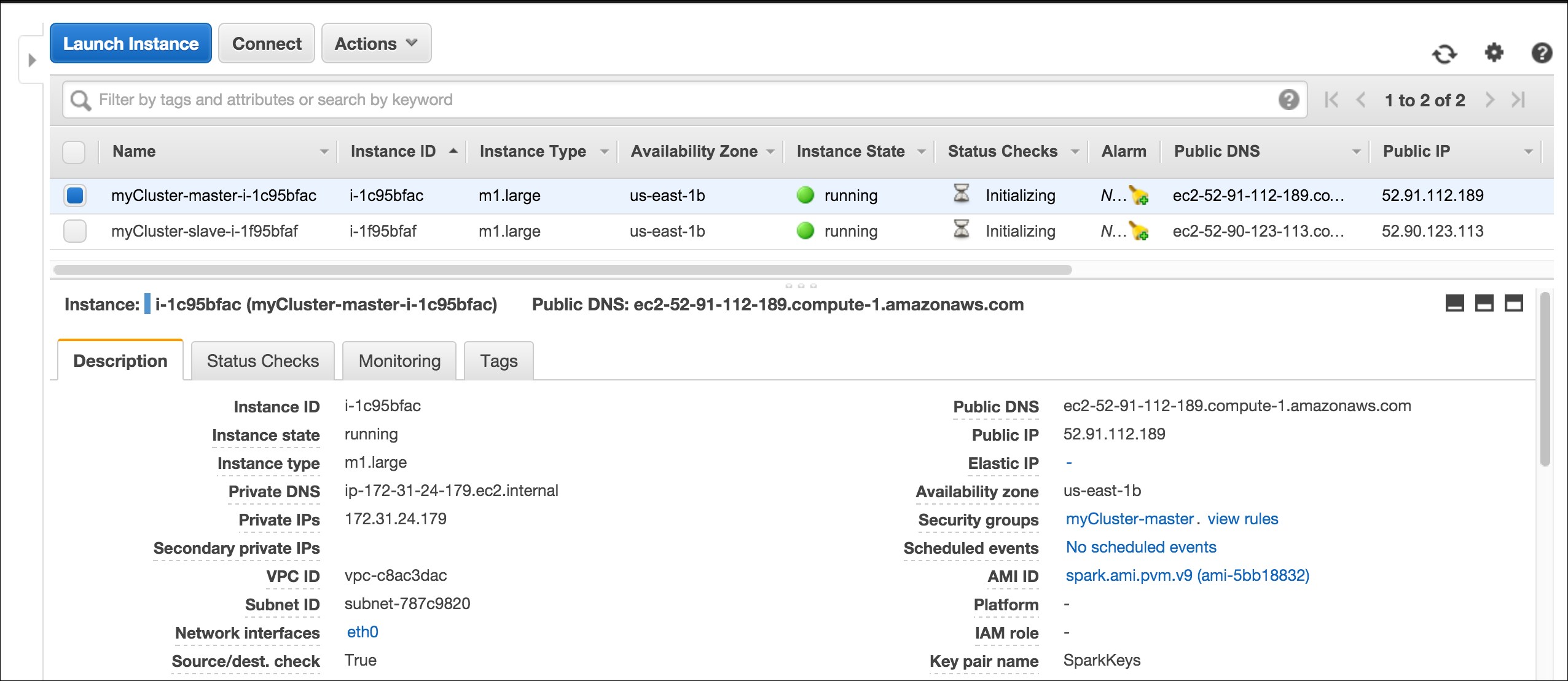
Your AWS EC2 dashboard will show the instances as follows:
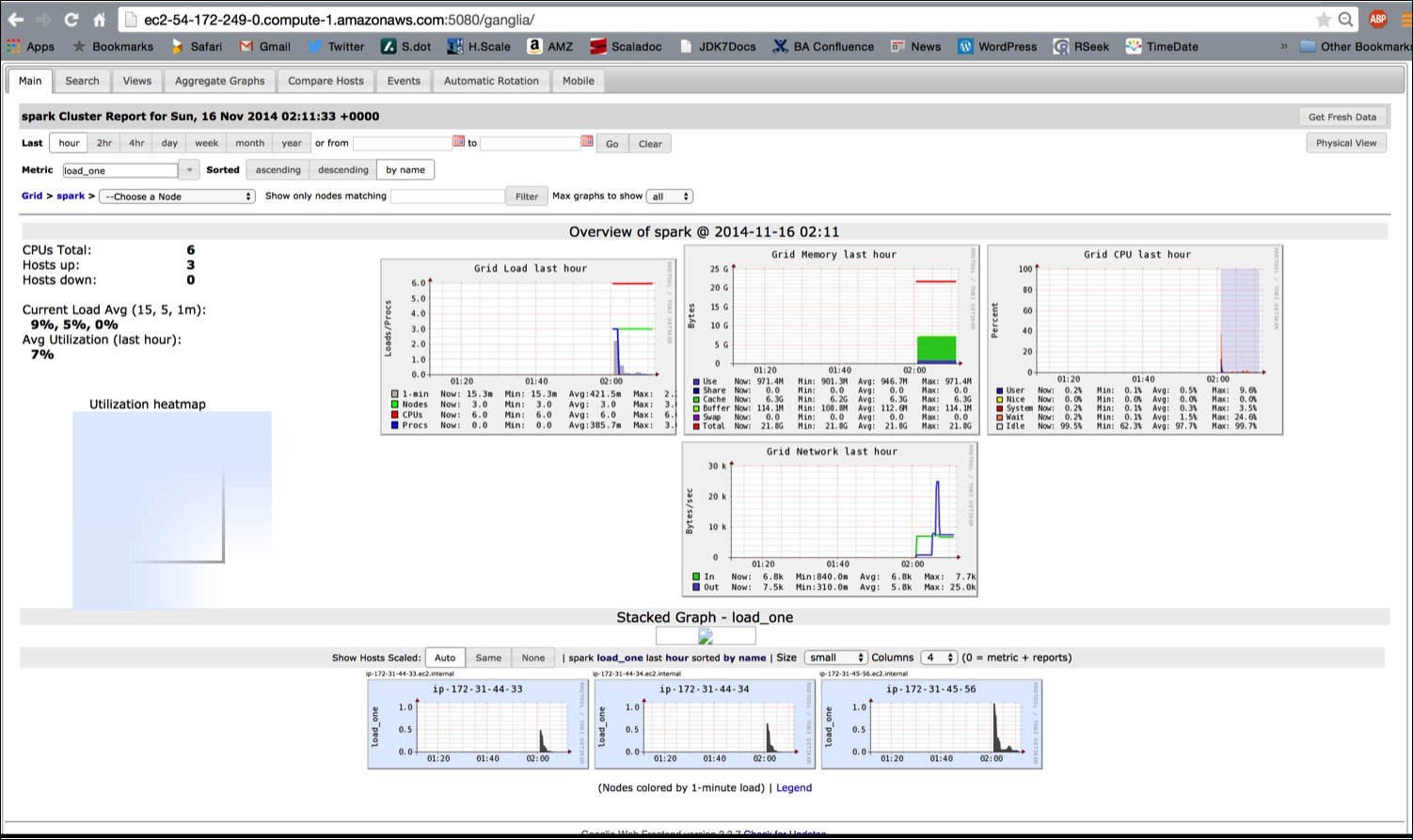
The ganglia dashboard shown in the following screenshot is a good place to monitor the instances:
Try running one of the example jobs on your new cluster to make sure everything is okay, as shown in the following screenshot:

The JPS should show this:
root@ip-172-31-45-56 ~]$ jps 1904 NameNode 2856 Jps 2426 Master 2078 SecondaryNameNode
The script has started the Spark master, the Hadoop name node, and data nodes (in slaves).
Let's run the two programs that we ran earlier on our local machine:
cd spark bin/run-example GroupByTest bin/run-example SparkPi 10
The ease with which one can spin up a few nodes in the Cloud, install the Spark stack, and run the program in a distributed manner is interesting.
The ec2/spark-ec2 destroy <cluster name> command will terminate the instances.

If you have a problem with the key pairs, I found the command, ~/aws/ec2-api-tools-1.7.5.1/bin/ec2-describe-keypairs helpful to troubleshoot.
Now that you've run a simple job on our EC2 cluster, it's time to configure your EC2 cluster for our Spark jobs. There are a number of options you can use to configure with the spark-ec2 script.
The ec2/ spark-ec2 -help command will display all the options available.
First, consider what instance types you may need. EC2 offers an ever-growing collection of instance types and you can choose a different instance type for the master and the workers. The instance type has the most obvious impact on the performance of your Spark cluster. If your work needs a lot of RAM, you should choose an instance with more RAM. You can specify the instance type with --instance-type= (name of instance type). By default, the same instance type will be used for both the master and the workers; this can be wasteful if your computations are particularly intensive and the master isn't being heavily utilized. You can specify a different master instance type with --master-instance-type= (name of instance).
Spark's EC2 scripts use Amazon Machine Images (AMI) provided by the Spark team. Usually, they are current and sufficient for most of the applications. You might need your own AMI in certain circumstances, such as custom patches (for example, using a different version of HDFS) for Spark, as they will not be included in the machine image.
Deploying Spark on Elastic MapReduce
In addition to the Amazon basic EC2 machine offering, Amazon offers a hosted MapReduce solution called Elastic MapReduce (EMR). The blog at http://blogs.aws.amazon.com/bigdata/post/Tx6J5RM20WPG5V/Building-a-Recommendation-Engine-with-Spark-ML-on-Amazon-EMR-using-Zeppelin has lots of interesting details on how to start Spark in EMR.
Deploying a Spark-based EMR has become very easy, Spark is a first class entity in EMR. When you create an EMR cluster, you have the option to select Spark. The following screenshot shows the Create Cluster-Quick Options of EMR:

The advanced option has Spark as well as other stacks.



