






















































One of the first and most important things you need to learn about Splunk in order to work with it effectively is what the functional components are and how they work together. Here is a list:
- Universal forwarder
- Indexer and indexer clusters
- Search head and search head clusters
- Deployment server
- Deployer
- Cluster master
- License master
- Heavy forwarder
Universal forwarders, indexers, and search heads constitute the majority of Splunk functionality; the other components provide supporting roles for larger clustered/distributed environments. We'll summarize each of these here and dig into more details in chapters to come.
In very small installations, you can install Splunk Enterprise on a single server, which will provide all the indexing and search functionality in one instance. However, in most cases, but in most cases you will need to scale Splunk up to handle higher data volumes and more users, so the functions that we just listed will be broken out onto multiple servers to support scalability and provide redundancy for higher reliability.
The following diagram shows all the Splunk components involved in a larger Splunk deployment and how they fit together:
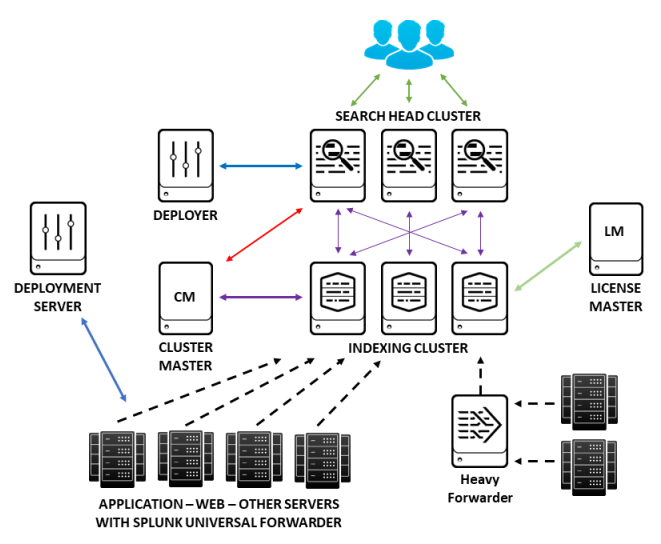
The universal forwarder (UF) is a free small-footprint version of Splunk Enterprise that is installed on each application, web, or other type of server (which may be running various flavors of Linux or Windows operating systems) to collect data from specified log files and forward this data to Splunk for indexing (storage). In a large Splunk deployment, you may have hundreds or thousands of forwarders that consume and forward data for indexing.
An indexer is the Splunk component that creates and manages indexes, which is where machine data is stored. Indexers perform two main functions: parsing and storing data, which has been received from forwarders or other data sources into indexes, and searching and returning the indexed data in response to search requests.
An indexing cluster is a group of indexers that have been configured to work together to handle higher volumes of both incoming data to be indexed and search requests to be serviced, as well as providing redundancy by keeping duplicate copies of indexed data spread across the cluster members. Be aware that index cluster members can be called both peer nodes and search peers in Splunk documentation, depending on context, which can be a bit confusing until you get used to the nomenclature.
A search head is an instance of Splunk Enterprise that handles search management functions. This includes providing a web-based user interface called Splunk Web, from which users issue search requests in what is called Search Processing Language (SPL). Search requests initiated by a user (or a report or dashboard) are sent to one or more indexers to locate and return the requested data; the search head then formats the returned data for presentation to the user.
A search head cluster is a group of multiple search heads configured to work together to service larger numbers of users and provide redundancy for servicing search requests. Search head cluster members are called cluster members in Splunk documentation.
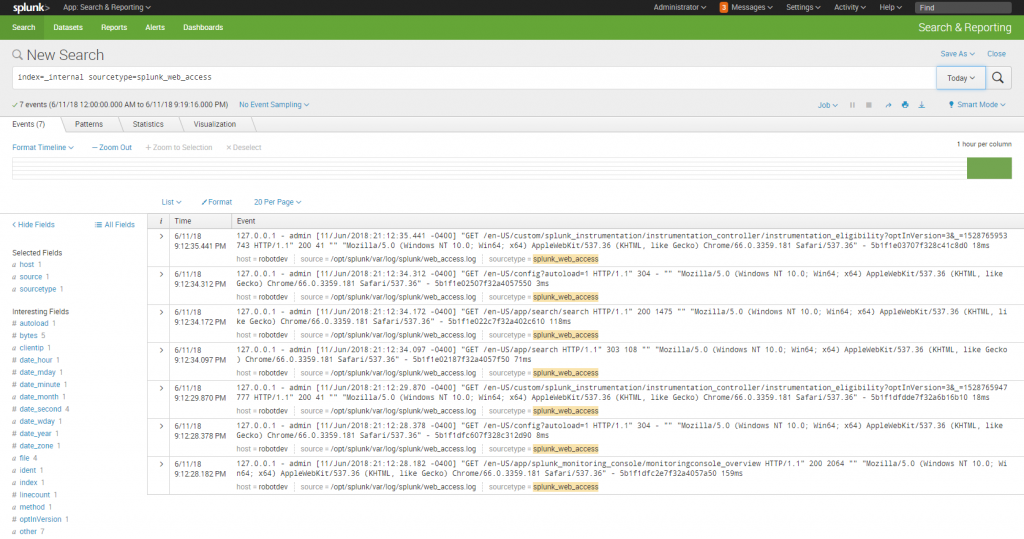
The following screenshot is an example of executing a simple search in Splunk Web. The SPL specifies searching in the _internal index, which is where Splunk saves data about its internal operations, and provides a count of the number of events in each log for Today. The SPL command specified an index, and then pipes the returned results to the stats command to return a count of all the events by their source and sourcetype (we'll discuss all this a bit further along in this chapter):
index=_internal | stats count by source, sourcetype
Following is the screenshot for simple search in Splunk:
A deployment server is a Splunk Enterprise instance that acts as a centralized configuration manager for a number of Splunk components, but which in practice is used to manage UFs. For instance, all of the hundreds or thousands of UFs that may be installed on servers in an Enterprise environment can periodically "phone home" to the deployment server to pick up new configuration information, making the task of managing all these UFs much easier.
A deployer is a Splunk Enterprise instance that is used to distribute Splunk apps and certain other configuration updates to search head cluster members.
A cluster master is a Splunk Enterprise instance that coordinates the activities of an indexing cluster. In an index cluster, data is distributed across multiple indexer instances to provide redundancy; the cluster master takes care of both controlling how that data is distributed, and helping search heads know where to direct their search requests to find specific sets of data. A cluster master is also called a master node in Splunk documentation.
A license master is a single Splunk Enterprise instance that provides a licensing service for the multiple instances of Splunk that have been deployed in a distributed environment. If you have a standalone instance of Splunk Enterprise, or a standalone indexer, you can install a license locally on that machine; otherwise, you will need a license master.
A heavy forwarder is an instance of Splunk Enterprise that can receive data from other forwarders or data sources and parse, index, and/or send data to another Splunk instance for indexing. A heavy forwarder has some features disabled so that it doesn't consume as many resources as an indexer, but retains most of an indexer's capability except that it cannot service search requests. A heavy forwarder is often used to parse incoming data and route it to various destinations for indexing depending upon the source and type of data received, and/or to speed up processing and reduce the processing load on indexers, but its use is optional.
Splunk Enterprise also has a monitoring tool function called the monitoring console, which lets you view detailed topology and performance information about your entire distributed deployment from one interface. This function can be configured to run on one of the other Splunk components such as the cluster master or deployer if resources allow.
If this seems like a lot of functionality to absorb when you're just getting started, don't worry—you only really need to focus on getting comfortable with the data input, indexing, and search functions for now; the other pieces play smaller roles in day-to-day Splunk administration activities.














