






















































Building C++ applications
You can use any text editor to write code, because, ultimately, code is just text. To write code, you are free to choose between simple text editors such as Vim, or an advanced integrated development environment (IDE) such as MS Visual Studio. The only difference between a love letter and source code is that the latter might be interpreted by a special program called a compiler (while the love letter cannot be compiled into a program, it might give you butterflies in your stomach).
To mark the difference between a plain text file and source code, a special file extension is used. C++ operates with the .cpp and .h extensions (you may also occasionally encounter .cxx and .hpp as well). Before getting into the details, think of the compiler as a tool that translates the source code into a runnable program, known as an executable file or just an executable. The process of making an executable from the source code is called compilation. Compiling a C++ program is a sequence of complex tasks that results in machine code generation. Machine code is the native language of the computer – that’s why it’s called machine code.
Typically, a C++ compiler parses and analyzes the source code, then generates intermediate code, optimizes it, and, finally, generates machine code in a file called an object file. You may have already encountered object files; they have individual extensions – .o in Linux and .obj in Windows. The created object file contains more than just machine code that can be run by the computer. Compilation usually involves several source files, and compiling each source file produces a separate object file. These object files are then linked together by a tool called a linker to form a single executable file. This linker uses additional information stored in object files to link them properly (linking will be discussed later in this chapter).
The following diagram depicts the program-building phases:
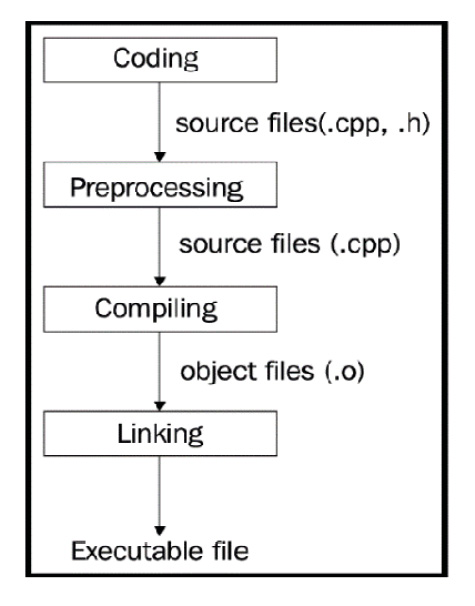
Figure 1.1: The compilation phases of a typical C++ program
The C++ application-building process consists of three major steps:
- Preprocessing
- Compiling
- Linking
All of these steps are done using different tools, but modern compilers encapsulate them in a single tool, thereby providing a single and more straightforward interface for programmers.
The generated executable file persists on the hard drive of the computer. To run it, it should be copied to the main memory, the RAM. The copying is done by another tool, named the loader. The loader is a part of the operating system (OS) and knows what and where should be copied from the contents of the executable file. After loading the executable file into the main memory, the original executable file won’t be deleted from the hard drive.
A program is loaded and run by the OS. The OS manages the execution of the program, prioritizes it over other programs, unloads it when it’s done, and so on. The running copy of the program is called a process. A process is an instance of an executable file.
Preprocessing
A preprocessor is intended to process source files to make them ready for compilation. A preprocessor works with preprocessor directives, such as #define, #include, and so on. Directives don’t represent program statements, but they are commands for the preprocessor, telling it what to do with the text of the source file. The compiler cannot recognize those directives, so whenever you use preprocessor directives in your code, the preprocessor resolves them accordingly before the actual compilation of the code begins.
For example, the following code will be changed before the compiler starts to compile it:
#define NUMBER 41
int main() {
int a = NUMBER + 1;
return 0;
} Everything that is defined using the #define directive is called a macro. After preprocessing, the compiler gets the transformed source in this form:
int main() {
int a = 41 + 1;
return 0;
} It is dangerous to use macros that are syntactically correct but have logical errors:
#define SQUARE_IT(arg) (arg * arg)
The preprocessor will replace any occurrence of SQUARE_IT(arg) with (arg * arg), so the following code will output 16:
int st = SQUARE_IT(4); std::cout << st;
The compiler will receive this code as follows:
int st = (4 * 4); std::cout << st;
Problems arise when we use complex expressions as a macro argument:
int bad_result = SQUARE_IT(4 + 1); std::cout << bad_result;
Intuitively, this code will produce 25, but the truth is that the preprocessor doesn’t do anything but text processing, and in this case, it replaces the macro like this:
int bad_result = (4 + 1 * 4 + 1); std::cout << bad_result; // prints 9, instead of 25
To fix the macro definition, surround the macro argument with additional parentheses:
#define SQUARE_IT(arg) ((arg) * (arg))
Now, the expression will take this form:
int bad_result = ((4 + 1) * (4 + 1));
Tip
As a rule of thumb, avoid using macro definitions. Macros are error-prone and C++ provides a set of constructs that make the use of macros obsolete.
The preceding example would be type-checked and processed at compile time if we used a constexpr function:
constexpr int double_it(int arg) { return arg * arg; }
int bad_result = double_it(4 + 1); Use the constexpr specifier to make it possible to evaluate the return value of the function (or the value of a variable) at compile time.
Header files
The most common use of the preprocessor is the #include directive, which intends to include header files in the source code. Header files contain definitions for functions, classes, and so on:
// file: main.cpp
#include <iostream>
#include "rect.h"
int main() {
Rect r(3.1, 4.05);
std::cout << r.get_area() << std::endl;
} After the preprocessor examines main.cpp, it replaces the #include directives with corresponding contents of iostream and rect.h.
C++17 introduces the __has_include preprocessor constant expression, which evaluates to 1 if the file with the specified name is found and 0 if not:
#if __has_include("custom_io_stream.h")
#include "custom_io_stream.h"
#else
#include <iostream>
#endif When declaring header files, it’s strongly advised to use so-called include guards (#ifndef, #define, and #endif) to avoid double declaration errors.
Using modules
Modules fix header files with annoying include-guard issues. We can now get rid of preprocessor macros. Modules incorporate two keywords – import, and export. To use a module, we import it. To declare a module with its exported properties, we use export. Before we list the benefits of using modules, let’s look at a simple usage example.
The following code declares a module:
export module test;
export int square(int a) { return a * a; } The first line declares the module named test. Next, we declared the square() function and set it to export. This means that we can have functions and other entities that are not exported, so they will be private outside of the module. By exporting an entity, we set it to public for module users. To use module, we must import it, as shown in the following code:
import test;
int main() {
square(21);
} The following features make modules better compared to regular header files:
- A module is imported only once, similar to precompiled headers supported by custom language implementations. This reduces the compile time drastically. Non-exported entities do not affect the translation unit that imports the module.
- Modules allow us to express the logical structure of code by allowing us to select which units should be exported and which should not. Modules can be bundled together into bigger modules.
- We can get rid of workarounds such as include guards, as described earlier. We can import modules in any order. There are no more concerns for macro redefinitions.
Modules can be used together with header files. We can both import and include headers in the same file, as demonstrated in the following example:
import <iostream>;
#include <vector>
int main() {
std::vector<int> vec{1, 2, 3};
for (int elem : vec) std::cout << elem;
} When creating modules, you are free to export entities in the interface file of the module and move the implementations to other files. The logic is the same as it is for managing .h and .cpp files.
Compiling
The C++ compilation process consists of several phases. Some of the phases are intended to analyze the source code, while others generate and optimize the target machine code.
The following diagram shows the phases of compilation:
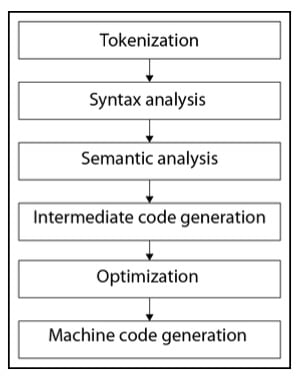
Figure 1.2: C++ compilation phases
Let’s look at some of these phases in detail.
Syntax analysis
When speaking about programming language compilation, we usually differentiate two terms – syntax and semantics:
- The syntax is the structure of the code; it defines the rules by which combined tokens make structural sense. For example, day nice is a syntactically correct phrase in English because it doesn’t contain errors in either of the tokens.
- Semantics, on the other hand, concerns the actual meaning of the code – that is, day nice is semantically incorrect and should be corrected to nice day.
Syntax analysis is a crucial part of source analysis because tokens will be analyzed syntactically and semantically – that is, as to whether they bear any meaning that conforms to the general grammar rules.
Let’s take a look at the following example:
int b = a + 0;
This may not make sense to us, since adding zero to the variable won’t change its value, but the compiler doesn’t look at logical meaning here – it looks for the syntactic correctness of the code (a missing semicolon, a missing closing parenthesis, and more). Checking the syntactic correctness of the code is done in the syntax analysis phase of compilation. The lexical analysis part divides the code into tokens; syntax analysis checks for syntactic correctness, which means that the aforementioned expression will produce a syntax error if we have missed a semicolon:
int b = a + 0
g++ will complain with the expected ';' at the end of the declaration error.
Optimization
Generating intermediate code helps the compiler make optimizations in the code. Compilers try to optimize code a lot. Optimizations are done in more than one pass. For example, take a look at the following code:
int a = 41; int b = a + 1;
During compilation, the preceding code will be optimized into the following:
int a = 41; int b = 41 + 1;
This, again, will be optimized into the following:
int a = 41; int b = 42;
Some programmers do not doubt that, nowadays, compilers code better than programmers.
Machine code generation
Compiler optimizations are done in both intermediate code and generated machine code. The compiler usually generates object files containing a lot of other data besides the machine code.
The structure of an object file depends on the platform; for example, in Linux, it is represented in Executable and Linkable Format (ELF). A platform is an environment in which a program is executed. In this context, by platform, we mean the combination of the computer architecture (more specifically, the instruction set architecture) and the OS. Hardware and OSs are designed and created by different teams and companies. Each of them has different solutions to design problems, which leads to major differences between platforms. Platforms differ in many ways, and those differences are projected onto the executable file format and structure as well. For example, the executable file format in Windows systems is Portable Executable (PE), which has a different structure, number, and sequence of sections than ELF in Linux.
An object file is divided into sections. The most important ones for us are the code sections (marked as .text) and the data section (.data). The .text section holds the program’s instructions, while the .data section holds the data used by instructions. Data itself may be split into several sections, such as initialized, uninitialized, and read-only data.
An important part of object files, in addition to the .text and .data sections, is the symbol table. The symbol table stores the mappings of strings (symbols) to locations in the object file. In the preceding example, the compiler-generated output had two portions, the second portion of which was marked as information:, which holds the names of the functions used in the code and their relative addresses. This information: is the abstract version of the actual symbol table of the object file. The symbol table holds both symbols defined in the code and symbols used in the code that need to be resolved. This information is then used by the linker to link the object files together to form the final executable file.
Linking
Let’s take a look at the following project structure:
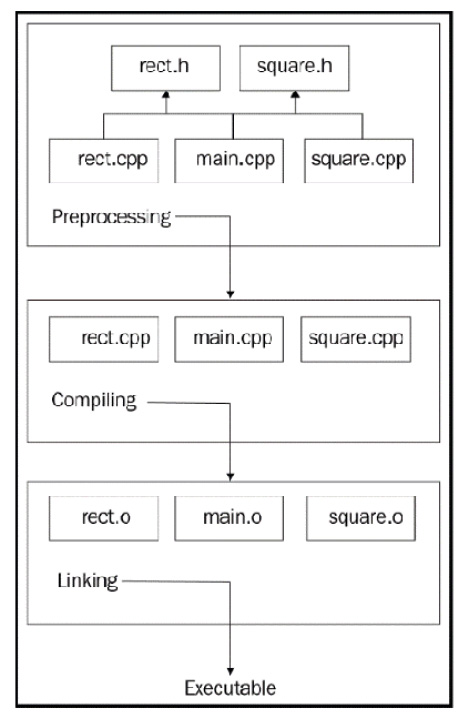
Figure 1.3: A sample project structure with several .h and .cpp files
The compiler will compile each unit separately. Compilation units, also known as source files, are independent of each other in some way.
When the compiler compiles main.cpp, which has a call to the get_area() function in Rect, it does not include the get_area() implementation in main.cpp. Instead, it is just sure that the function is implemented somewhere in the project. When the compiler gets to rect.cpp, it does not know that the get_area() function is used somewhere. Here’s what the compiler gets after main.cpp passes the preprocessing phase:
// contents of the iostream
struct Rect {
private:
double side1_;
double side2_;
public:
Rect(double s1, double s2);
const double get_area() const;
};
struct Square : Rect {
Square(double s);
};
int main() {
Rect r(3.1, 4.05);
std::cout << r.get_area() << std::endl;
return 0;
} After analyzing main.cpp, the compiler generates the following intermediate code (many details have been omitted to simply express the idea behind compilation):
struct Rect {
double side1_;
double side2_;
};
void _Rect_init_(Rect* this, double s1, double s2);
double _Rect_get_area_(Rect* this);
struct Square {
Rect _subobject_;
};
void _Square_init_(Square* this, double s);
int main() {
Rect r;
_Rect_init_(&r, 3.1, 4.05);
printf("%d\n", _Rect_get_area(&r));
// we've intentionally replace cout with printf for
// brevity and
// supposing the compiler generates a C intermediate
// code
return 0;
} The compiler will remove the Square struct with its constructor function (we named it _Square_init_) while optimizing the code because it was never used in the source code.
At this point, the compiler operates with main.cpp only, so it sees that we called the _Rect_init_ and _Rect_get_area_ functions but did not provide their implementation in the same file. However, as we did provide their declarations beforehand, the compiler trusts us and believes that those functions are implemented in other compilation units. Based on this trust and the minimum information regarding the function signature (its return type, name, and the number and types of its parameters), the compiler generates an object file that contains the working code in main.cpp and somehow marks the functions that have no implementation but are trusted to be resolved later. This resolution is done by the linker.
In the following example, we have the simplified variant of the generated object file, which contains two sections – code and information. The code section has addresses for each instruction (the hexadecimal values):
code:
0x00 main
0x01 Rect r;
0x02 _Rect_init_(&r, 3.1, 4.05);
0x03 printf("%d\n", _Rect_get_area(&r));
information:
main: 0x00
_Rect_init_: ????
printf: ????
_Rect_get_area_: ???? Take a look at the information section. The compiler marks all the functions used in the code section that were not found in the same compilation unit with ????. These question marks will be replaced by the actual addresses of the functions found in other units by the linker. Finishing with main.cpp, the compiler starts to compile the rect.cpp file:
// file: rect.cpp
struct Rect {
// #include "rect.h" replaced with the contents
// of the rect.h file in the preprocessing phase
// code omitted for brevity
};
Rect::Rect(double s1, double s2)
: side1_(s1), side2_(s2)
{}
const double Rect::get_area() const {
return side1_ * side2_;
} Following the same logic here, the compilation of this unit produces the following output (don’t forget, we’re still providing abstract examples):
code: 0x00 _Rect_init_ 0x01 side1_ = s1 0x02 side2_ = s2 0x03 return 0x04 _Rect_get_area_ 0x05 register = side1_ 0x06 reg_multiply side2_ 0x07 return information: _Rect_init_: 0x00 _Rect_get_area_: 0x04
This output has all the addresses of the functions in it, so there is no need to wait for some functions to be resolved later.
The task of the linker is to combine these object files into a single object file. Combining files results in relative address changes; for example, if the linker puts the rect.o file after main.o, the starting address of rect.o becomes 0x04 instead of the previous value of 0x00:
code:
0x00 main
0x01 Rect r;
0x02 _Rect_init_(&r, 3.1, 4.05);
0x03 printf("%d\n", _Rect_get_area(&r)); 0x04 _Rect_init_
0x05 side1_ = s1
0x06 side2_ = s2
0x07 return
0x08 _Rect_get_area_
0x09 register = side1_
0x0A reg_multiply side2_
0x0B return
information (symbol table):
main: 0x00
_Rect_init_: 0x04
printf: ????
_Rect_get_area_: 0x08
_Rect_init_: 0x04
_Rect_get_area_: 0x08 Correspondingly, the linker updates the symbol table addresses (the information: section in our example). As mentioned previously, each object file has a symbol table, which maps the string name of the symbol to its relative location (address) in the file. The next step of linking is to resolve all the unresolved symbols in the object file.
Now that the linker has combined main.o and rect.o, it knows the relative location of unresolved symbols because they are now located in the same file. The printf symbol will be resolved the same way, except this time, it will link the object files with the standard library. Once all the object files have been combined (we omitted the linking of square.o for brevity), all the addresses have been updated, and all the symbols have been resolved, the linker outputs the one final object file that can be executed by the OS. As discussed earlier in this chapter, the OS uses a tool called the loader to load the contents of the executable file into memory.
Linking libraries
A library is similar to an executable file, with one major difference: it does not have a main() function, which means that it cannot be invoked as a regular program. Libraries are used to combine code that might be reused with more than one program. You already linked your programs with the standard library by including the <iostream> header, for example.
Libraries can be linked with the executable file either as static or dynamic libraries. When you link them as a static library, they become a part of the final executable file. A dynamically linked library should also be loaded into memory by the OS to provide your program with the ability to call its functions. Let’s suppose we want to find the square root of a function:
int main() {
double result = sqrt(49.0);
} The C++ standard library provides the sqrt() function, which returns the square root of its argument. If you compile the preceding example, it will produce an error insisting that the sqrt function has not been declared. We know that to use the standard library function, we should include the corresponding <cmath> header. But the header file does not contain the implementation of the function; it just declares the function (in the std namespace), which is then included in our source file:
#include <cmath>
int main() {
double result = std::sqrt(49.0);
} The compiler marks the address of the sqrt symbol as unknown, and the linker should resolve it in the linking stage. The linker will fail to resolve it if the source file is not linked with the standard library implementation (the object file containing the library functions). The final executable file generated by the linker will consist of both our program and the standard library if the linking was static. On the other hand, if the linking is dynamic, the linker marks the sqrt symbol to be found at runtime.
Now, when we run the program, the loader also loads the library that was dynamically linked to our program. It loads the contents of the standard library into the memory as well and then resolves the actual location of the sqrt() function in memory. The same library that has already been loaded into memory can be used by other programs as well.



