






















































The normalizer behaves like an analyzer except that it guarantees to generate a single token. There is no built-in normalizer. To customize the normalizer, you only allow character-based character filters and token filters. The way to define a normalizer is similar defining to an analyzer, except that it uses the normalizer keyword instead of analyzer. Let's delete the cf_etf_toy index and recreate it with lowercase_normalizer, which contains a lowercase token filter:
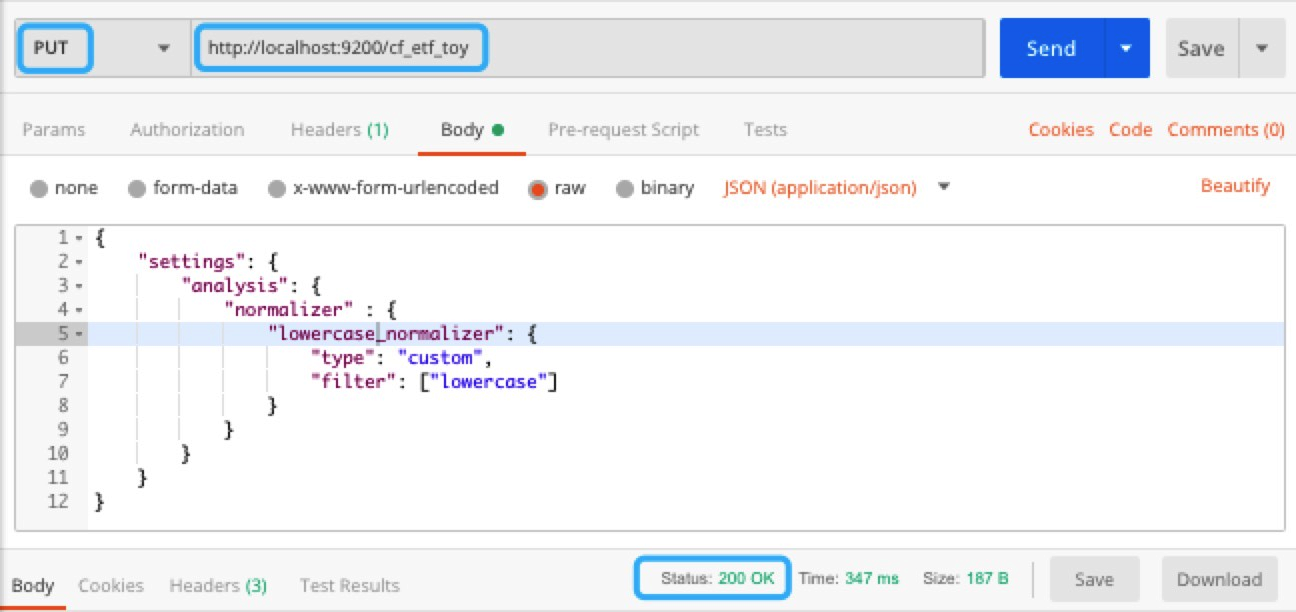
Then, we apply lowercase_normalizer to a sample text, as shown in the following screenshot:
In the response body, you can see that only one token is generated.















