






















































Chapter 9. Messaging Patterns
When Smalltalk was first envisioned, the communication between classes was envisioned as being messages. Somehow we've moved away from this pure idea of messages. We spoke a bit about how functional programming avoids side effects; well, much the same is true of messaging-based systems.
Messaging also allows for impressive scalability as messages can be fanned out to dozens or even hundreds of computers. Within a single application, messaging promotes low coupling and eases testing.
In this chapter, we're going to look at a number of patterns related to messaging. By the end of the chapter, you should be aware of how messages work. When I first learned about messaging, I wanted to rewrite everything using it.
We will be covering:
- What's a message anyway?
- Commands
- Events
- Request-reply
- Publish-subscribe
- Fan out and fan in
- Dead-letter queues
- Message replay
- Pipes and filters
What's a message anyway?
In the simplest definition, a message is a collection of related bits of data that have some meaning together. The message is named in a way that provides some additional meaning to it. For instance, both an AddUser message and a RenameUser message might have the following fields:
- User ID
- Username
But the fact that the fields exist inside a named container gives them a different meaning.
Messages are usually related to some action in the application or some action in the business. A message contains all the information needed for a receiver to act upon the action. In the case of the
RenameUser message, the message contains enough information for any component that keeps track of a relationship between a user ID and a username to update its value for username.
Many messaging systems, especially those that communicate between application boundaries, also define an envelope. The envelope has metadata in it that could help with message auditing, routing, and security. The information on the envelope is not part of the business process but is part of the infrastructure. So having a security annotation on the envelope is fine as security exists outside of the normal business workflow and is owned by a different part of the application. An example message might contain:
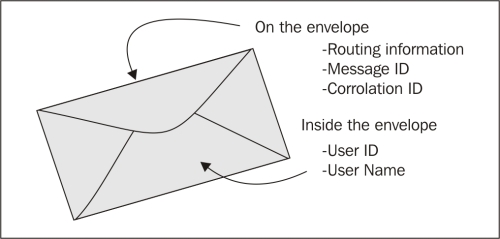
Messages should be sealed so that no changes can be made to them once they have been created. This makes certain operations such as auditing and replaying much easier.
Messaging can be used to communicate inside a single process or it can be used between applications. For the most part, there is no difference between sending a message within an application and sending it between applications. One difference is the treatment of synchronicity. Within a single process, messages can be handled in a synchronous fashion. This means that the main processing effectively waits for the handling of the message to complete before continuing.
In an asynchronous scenario, the handling of the message may occur at a later date. Sometimes, the later date is far in the future. When calling out to an external server, the asynchronous approach will almost certainly be the correct one. Even within a single process, the single-threaded nature of JavaScript encourages using asynchronous messaging. While using asynchronous messaging, some additional care and attention needs to be taken, as some of the assumptions made for synchronous messaging cease to be safe. For instance, assuming the messages will be replied to in the same order in which they were sent is no longer safe.
There are two different flavors of messages: commands and events. Commands instruct things to happen while events notify about something that has happened.
Commands
A command is simply an instruction from one part of a system to another. It is a message so it is really just a simple data transfer object. If you think back to the command pattern introduced in Chapter 5, Behavioral Patterns, this is exactly what it uses.
As a matter of convention, commands are named using the imperative. The format is usually <verb><object>. Thus, a command might be called
InvadeCity. Typically, when naming a command, you want to avoid generic names and focus on exactly what is causing the command.
As an example, consider a command that changes the address of a user. You might be tempted to simply call the command ChangeAddress, but doing so does not add any additional information. It would be better to dig deeper and see why the address is being changed. Did the person move or was the original address entered incorrectly? Each case might include a different behavior. Users that have moved could be sent a moving present, while those correcting their address would not.
Messages should have a component of business meaning to increase their utility. Defining messages and how they can be constructed within a complex business is a whole field of study on its own. Those interested might do well to investigate domain-driven design (DDD).
Commands are an instruction targeted at one specific component, giving it instructions to perform a task.
Within the context of a browser, you might consider that a command would be the click that is fired on a button. The command is transformed into an event and that event is what is passed to your event listeners.
Only one end point should receive a specific command. This means that only one component is responsible for an action taking place. As soon as a command is acted upon by more than one end point, any number of race conditions are introduced. What if one of the end points accepts the command and another rejects it as invalid? Even in cases where several near identical commands are issued, they should not be aggregated. For instance, sending a command from a king to all his generals should send one command to each general.
Because there is only one end point for a command, it is possible for that end point to validate and even cancel the command. The cancellation of the command should have no impact on the rest of the application.
When a command is acted upon, then one or more events may be published.
Events
An event is a special message that notifies that something has happened. There is no use in trying to change or cancel an event because it is simply a notification that something has happened. You cannot change the past unless you own a Delorian.
The naming convention for events is that they are written in the past tense. You might see a reversal in the ordering of the words in the command, so we could end up with CityInvaded once the InvadeCity command has succeeded.
Unlike commands, events may be received by any number of components. There are no real-race conditions presented by this approach. As no message handler can change the message or interfere with the delivery of other copies of the message, each handler is siloed away from all others.
You may be familiar with events from having done user interface work. When a user clicks on a button, an event is "raised." In effect, the event is broadcast to a series of listeners. You subscribe to a message by hooking into that event:
document.getElementById("button1").addEventListener("click", doSomething);The events in the browsers don't quite meet the definition of an event I gave earlier. This is because event handlers in the browser can cancel events and stop them from propagating to the next handler. That is to say that when there are a series of event handlers for the same message, one of them can completely consume the message and not pass it onto subsequent handlers. There is certainly utility to an approach like this but it does introduce some confusion. Fortunately, for UI messages the number of handlers is typically quite small.
In some systems, events can be polymorphic in nature. That is to say that if I had an event called IsHiredSalary that is fired when somebody is hired in a salaried role, I could make it a descendant of the message IsHired. Doing so would allow for both handlers subscribed to IsHiredSalary and IsHired to be fired upon receipt of an IsHiredSalary event. JavaScript doesn't have polymorphism in the true sense, so such things aren't particularly useful. You can add a message field that takes the place of polymorphism but it looks somewhat messy:
var IsHiredSalary = { __name: "isHiredSalary",
__alsoCall: ["isHired"],
employeeId: 77,
…
}In this case, I've used __ to denote fields that are part of the envelope. You could also construct the message with separate fields for message and envelope; it really doesn't matter all that much.
Let's take a look at a simple operation such as creating a user, so we can see how commands and events interact:
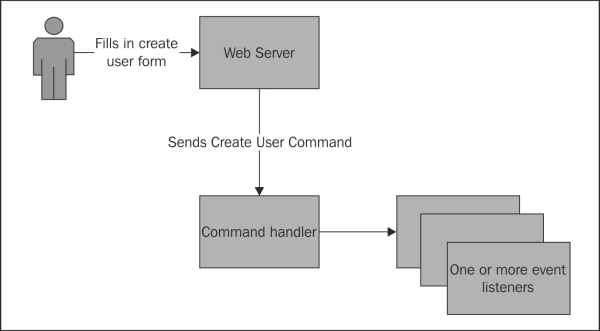
Here, a user enters data into a form and submits it. The web server takes in the input, validates it, and, if it is correct, creates a command. The command is now sent to the command handler. The command handler performs some action, perhaps writing to a database; it then publishes an event that is consumed by a number of event listeners. These event listeners might send confirmation e-mails, notify system administrators, or any number of things.
All of this looks familiar because systems already contain commands and events. The difference is that we are now modeling the commands and events explicitly.
Request-reply
The simplest pattern you'll see with messaging is the request-reply pattern. Also known as request-response, this is a method of retrieving data that is owned by another part of the application.
In many cases, the sending of a command is an asynchronous operation. A command is fired and the application flow continues on. Because of this, there is no easy way to do things such as look up a record by ID. Instead, one needs to send a command to retrieve a record and then wait for the associated event to be returned. The workflow might look like:
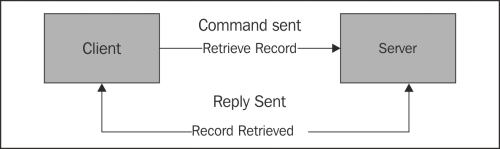
Most events can be subscribed to by any number of listeners. While it is possible to have multiple event listeners for a request-response pattern, it is unlikely and is probably not advisable.
We can implement a very simple request-response pattern here. In Westeros, there are some issues with sending messages in a timely fashion. Without electricity, sending messages over long distances rapidly can really only be accomplished by attaching tiny messages to the legs of crows. Thus, we have a crow messaging system.
We'll start with building out what we'll call the bus. A bus is simply a distribution mechanism for messages. It can be implemented in process, as we've done here, or out of process.
If implementing it out of process, there are many options from ZeroMQ to RabbitMQ to a wide variety of systems built on top of databases and in the cloud. Each of these systems exhibits some different behaviors when it comes to message reliability and durability. It is important to do some research into the way the message distribution systems work as they may dictate how the application is constructed. They also implement different approaches to dealing with the underlying unreliability of applications:
var CrowMailBus = (function () {
function CrowMailBus(requestor) {
this.requestor = requestor;
this.responder = new CrowMailResponder(this);
}
CrowMailBus.prototype.Send = function (message) {
if (message.__from == "requestor") {
this.responder.processMessage(message);
} else {
this.requestor.processMessage(message);
}
};
return CrowMailBus;
})();One thing that is a potential trip up is that the order in which messages are received back on the client is not necessarily the order in which they were sent. To deal with this, it is typical to include some sort of a correlation ID. When the event is raised, it includes a known ID from the sender so that the correct event handler is used.
This bus is a highly naïve one as it has its routing hardcoded. A real bus would probably allow the sender to specify the address of the end point for delivery. Alternately, the receivers could register themselves as interested in a specific sort of message. The bus would then be responsible for doing some limited routing to direct the message. Our bus is even named after the messages it deals with—certainly not a scalable approach.
Next, we'll implement the requestor. The requestor contains only two methods: one to send a request and the other to receive a response from the bus, as shown in the following code:
var CrowMailRequestor = (function () {
function CrowMailRequestor() {
}
CrowMailRequestor.prototype.Request = function () {
var message = {
__messageDate: new Date(),
__from: "requestor",
__corrolationId: new Guid(),
body: "Invade Moat Cailin"
};
var bus = new CrowMailBus(this);
bus.Send(message);
};
CrowMailRequestor.prototype.processMessage = function (message) {
console.dir(message);
};
return CrowMailRequestor;
})();The process message function currently just logs the response but it would likely do more in a real-world scenario such as updating the UI or dispatching another message. The correlation ID is invaluable in order to understand to which Send message the reply is related.
Finally, the responder simply takes in the message and replies to it with another message:
var CrowMailResponder = (function () {
function CrowMailResponder(bus) {
this.bus = bus;
}
CrowMailResponder.prototype.processMessage = function (message) {
var response = {
__messageDate: new Date(),
__from: "responder",
__corrolationId: message.__corrolationId,
body: "Okay, invaded
};
this.bus.Send(response);
};
return CrowMailResponder;
})();Everything in our example is synchronous but all it would take to make it asynchronous is to swap out the bus. If we're working in Node.js, then we can do this using process.nextTick, which simply defers a function to the next time through the event loop. If we're in a web context, then web workers may be used to do the processing in another thread. In fact, when starting a web worker, the communication back and forth to it takes the form of a message:
CrowMailBus.prototype.Send = function (message) {
var _this = this;
if (message.__from == "requestor") {
process.nextTick(function () {
return _this.responder.processMessage(message);
});
} else {
process.nextTick(function () {
return _this.requestor.processMessage(message);
});
}
};This approach now allows other code to run before the message is processed. If we weave in some print statements after each bus Send, then we get the following output:
Request sent! Reply sent { __messageDate: Mon Aug 11 2014 22:43:07 GMT-0600 (MDT), __from: 'responder', __corrolationId: 0.5604551520664245, body: 'Okay, invaded.' }
You can see that the print statements are executed before the message processing, as that processing happens next to iteration.
Publish-subscribe
I've alluded to the publish-subscribe model elsewhere in this chapter. Publish-subscribe is a powerful tool to decouple events from processing code.
At the crux of the pattern is the idea that, as a message publisher, my responsibility for the message should end as soon as I send it. I should not know who is listening to messages or what they will do with the messages. So long as I am fulfilling a contract to produce correctly formatted messages, the rest shouldn't matter.
It is the responsibility of the listener to register its interest in the message type. You'll, of course, wish to register some sort of security to disallow registration of rogue services.
We can update our service bus to do a more complete job of routing and sending multiple messages. Let's call our new method Publish instead of Send. We'll keep Send around to do the sending functionality, as shown in the following diagram:
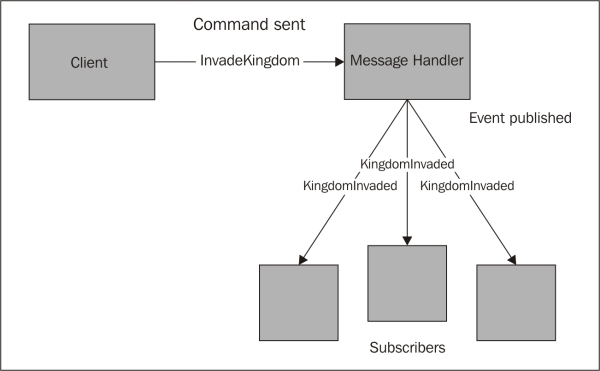
The crow mail analogy we used in the previous section starts to fall apart here as there is no way to broadcast a message using crows. Crows are too small to carry large banners and it is very difficult to train them to do sky writing. I'm unwilling to totally abandon the idea of crows, so let's assume that there exists a sort of crow broadcast center. Sending a message here allows for it to be fanned out to numerous interested parties who have signed up for updates. This center will be more or less synonymous with a bus.
We'll write our router so that it works as a function of the name of the message. One could route a message using any of its attributes. For instance, a listener could subscribe to all the messages called invoicePaid where the amount field is greater than $10,000. Adding this sort of logic to the bus will slow it down and make it far harder to debug. Really, this is more the domain of business process orchestration engines than a bus. We'll continue on without that complexity.
The first thing to set up is the ability to subscribe to published messages:
CrowMailBus.prototype.Subscribe = function (messageName, subscriber) {
this.responders.push({ messageName: messageName, subscriber: subscriber });
};The Subscribe function just adds a message handler and the name of a message to consume. The responders array is simply an array of handlers.
When a message is published, we loop over the array and fire each of the handlers that has registered for messages with that name:
CrowMailBus.prototype.Publish = function (message) {
for (var i = 0; i < this.responders.length; i++) {
if (this.responders[i].messageName == message.__messageName) {
(function (b) {
process.nextTick(function () {
return b.subscriber.processMessage(message);
});
})(this.responders[i]);
}
}
};The execution here is deferred to the next tick. This is done using a closure to ensure that the correctly scoped variables are passed through. We can now change CrowMailResponder to use the new Publish method instead of Send:
CrowMailResponder.prototype.processMessage = function (message) {
var response = {
__messageDate: new Date(),
__from: "responder",
__corrolationId: message.__corrolationId,
__messageName: "KingdomInvaded",
body: "Okay, invaded"
};
this.bus.Publish(response);
console.log("Reply published");
};Instead of allowing CrowMailRequestor to create its own bus as earlier, we need to modify it to accept an instance of bus from outside. We simply assign it to a local variable in CrowMailRequestor. Similarly, CrowMailResponder should also take in an instance of bus.
In order to make use of this, we simply need to create a new bus instance and pass it into the requestor:
var bus = new CrowMailBus();
bus.Subscribe("KingdomInvaded", new TestResponder1());
bus.Subscribe("KingdomInvaded", new TestResponder2());
var requestor = new CrowMailRequestor(bus);
requestor.Request();In the preceding code, we've also passed in two other responders that are interested in knowing about KingdomInvaded messages. They look like this:
var TestResponder1 = (function () {
function TestResponder1() {}
TestResponder1.prototype.processMessage = function (message) {
console.log("Test responder 1: got a message");
};
return TestResponder1;
})();By running this code, we will now get this:
Message sent! Reply published Test responder 1: got a message Test responder 2: got a message Crow mail responder: got a message
You can see that the messages are sent using Send. The responder or handler does its work and publishes a message that is passed onto each of the subscribers.
Fan out and fan in
A fantastic use of the publish-subscribe pattern allows you to fan out a problem to a number of different nodes. Moore's law has always been about the doubling of the number of transistors per square unit of measure. If you've been paying attention to processor clock speeds, you may have noticed that there hasn't really been any significant change in clock speeds for a decade. In fact, clock speeds are not lower than they were in 2005.
This is not to say that processors are "slower" than they once were. The work that is performed in each clock tick has increased. The number of cores has also jumped up. It is now unusual to see a single core processor; even in cellular phones, dual core processors are becoming common. It is the rule, rather than the exception, to have computers that are capable of doing more than one thing at a time.
At the same time, cloud computing is taking off. The computers you purchase outright are faster than the ones available to rent from the cloud. The advantage of cloud computing is that you can scale it out easily. It is nothing to provision a hundred or even a thousand computers from a cloud provider.
Writing software that can take advantage of multiple cores is the great computing problem of our time. Dealing directly with threads is a recipe for disaster. Locking and contention is a far too difficult problem for most developers: me included! For a certain class of problems, they can easily be divided up into subproblems and distributed. Some call this class of problems "embarrassingly parallelizable."
Messaging provides a mechanism to communicate the inputs and outputs from a problem. If we had one of these easily parallelized problems, such as searching, then we would bundle up the inputs into one message. In this case, it would contain our search terms. The message might also contain the set of documents to search. If we had 10,000 documents, then we could divide the search space up into, say, four collections of 2,500 documents. We would publish five messages with the search terms and the range of documents to search. A message span-out might look like:
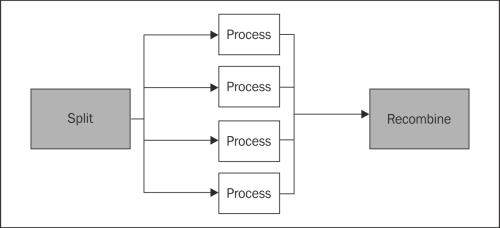
Different search nodes will pick up the messages and perform the search. The results will then be sent back to a node that will collect the messages and combine them into one. This is what will be returned to the client.
Of course, this is a bit of an oversimplification. It is likely that the receiving nodes themselves would maintain a list of documents over which they had responsibility. This would prevent the original publishing node from having to know anything about the documents it was searching through. The search results could even be returned directly to the client that would do the assembling.
Even in a browser, the fan-out-and-in approach can be used to distribute a calculation over a number of cores through the use of web workers. A simple example might take the form of creating a potion. A potion might contain a number of ingredients that can be combined to create a final product. It is quite computationally complicated combining ingredients, so we would like to farm a process out to a number of workers.
We start with a combiner that contains a combine() method as well as a complete() function that is called once all the distributed ingredients are combined:
var Combiner = (function () {
function Combiner() {
this.waitingForChunks = 0;
}
Combiner.prototype.combine = function (ingredients) {
var _this = this;
console.log("Starting combination");
if (ingredients.length > 10) {
for (var i = 0; i < Math.ceil(ingredients.length / 2); i++) {
this.waitingForChunks++;
console.log("Dispatched chunks count at: " + this.waitingForChunks);
var worker = new Worker("FanOutInWebWorker.js");
worker.addEventListener('message', function (message) {
return _this.complete(message);
});
worker.postMessage({ ingredients: ingredients.slice(i, i * 2) });
}
}
};
Combiner.prototype.complete = function (message) {
this.waitingForChunks--;
console.log("Outstanding chunks count at: " + this.waitingForChunks);
if (this.waitingForChunks == 0)
console.log("All chunks received");
};
return Combiner;
})();In order to keep track of the number of workers outstanding, we use a simple counter. Because the main section of code is single threaded, we have no risk of race conditions. Once the counter shows no remaining workers, we can take whatever step is necessary. The web worker looks like this:
self.addEventListener('message', function (e) {
var data = e.data;
var ingredients = data.ingredients;
combinedIngredient = new Westeros.Potion.CombinedIngredient();
for (var i = 0; i < ingredients.length; i++) {
combinedIngredient.Add(ingredients[i]);
}
console.log("calculating combination");
setTimeout(combinationComplete, 2000);
}, false);
function combinationComplete() {
console.log("combination complete");
(self).postMessage({ event: 'combinationComplete', result: combinedIngredient });
}In this case, we simply put in a timeout to simulate the complex calculation needed to combine ingredients.
The subproblems that are farmed out to a number of nodes do not have to be identical problems. However, they should be sufficiently complicated that the cost savings of farming them out is not consumed by the overhead of sending out messages.
Fan out and fan in
A fantastic use of the publish-subscribe pattern allows you to fan out a problem to a number of different nodes. Moore's law has always been about the doubling of the number of transistors per square unit of measure. If you've been paying attention to processor clock speeds, you may have noticed that there hasn't really been any significant change in clock speeds for a decade. In fact, clock speeds are not lower than they were in 2005.
This is not to say that processors are "slower" than they once were. The work that is performed in each clock tick has increased. The number of cores has also jumped up. It is now unusual to see a single core processor; even in cellular phones, dual core processors are becoming common. It is the rule, rather than the exception, to have computers that are capable of doing more than one thing at a time.
At the same time, cloud computing is taking off. The computers you purchase outright are faster than the ones available to rent from the cloud. The advantage of cloud computing is that you can scale it out easily. It is nothing to provision a hundred or even a thousand computers from a cloud provider.
Writing software that can take advantage of multiple cores is the great computing problem of our time. Dealing directly with threads is a recipe for disaster. Locking and contention is a far too difficult problem for most developers: me included! For a certain class of problems, they can easily be divided up into subproblems and distributed. Some call this class of problems "embarrassingly parallelizable."
Messaging provides a mechanism to communicate the inputs and outputs from a problem. If we had one of these easily parallelized problems, such as searching, then we would bundle up the inputs into one message. In this case, it would contain our search terms. The message might also contain the set of documents to search. If we had 10,000 documents, then we could divide the search space up into, say, four collections of 2,500 documents. We would publish five messages with the search terms and the range of documents to search. A message span-out might look like:
Different search nodes will pick up the messages and perform the search. The results will then be sent back to a node that will collect the messages and combine them into one. This is what will be returned to the client.
Of course, this is a bit of an oversimplification. It is likely that the receiving nodes themselves would maintain a list of documents over which they had responsibility. This would prevent the original publishing node from having to know anything about the documents it was searching through. The search results could even be returned directly to the client that would do the assembling.
Even in a browser, the fan-out-and-in approach can be used to distribute a calculation over a number of cores through the use of web workers. A simple example might take the form of creating a potion. A potion might contain a number of ingredients that can be combined to create a final product. It is quite computationally complicated combining ingredients, so we would like to farm a process out to a number of workers.
We start with a combiner that contains a combine() method as well as a complete() function that is called once all the distributed ingredients are combined:
var Combiner = (function () {
function Combiner() {
this.waitingForChunks = 0;
}
Combiner.prototype.combine = function (ingredients) {
var _this = this;
console.log("Starting combination");
if (ingredients.length > 10) {
for (var i = 0; i < Math.ceil(ingredients.length / 2); i++) {
this.waitingForChunks++;
console.log("Dispatched chunks count at: " + this.waitingForChunks);
var worker = new Worker("FanOutInWebWorker.js");
worker.addEventListener('message', function (message) {
return _this.complete(message);
});
worker.postMessage({ ingredients: ingredients.slice(i, i * 2) });
}
}
};
Combiner.prototype.complete = function (message) {
this.waitingForChunks--;
console.log("Outstanding chunks count at: " + this.waitingForChunks);
if (this.waitingForChunks == 0)
console.log("All chunks received");
};
return Combiner;
})();In order to keep track of the number of workers outstanding, we use a simple counter. Because the main section of code is single threaded, we have no risk of race conditions. Once the counter shows no remaining workers, we can take whatever step is necessary. The web worker looks like this:
self.addEventListener('message', function (e) {
var data = e.data;
var ingredients = data.ingredients;
combinedIngredient = new Westeros.Potion.CombinedIngredient();
for (var i = 0; i < ingredients.length; i++) {
combinedIngredient.Add(ingredients[i]);
}
console.log("calculating combination");
setTimeout(combinationComplete, 2000);
}, false);
function combinationComplete() {
console.log("combination complete");
(self).postMessage({ event: 'combinationComplete', result: combinedIngredient });
}In this case, we simply put in a timeout to simulate the complex calculation needed to combine ingredients.
The subproblems that are farmed out to a number of nodes do not have to be identical problems. However, they should be sufficiently complicated that the cost savings of farming them out is not consumed by the overhead of sending out messages.
Dead-letter queues
No matter how hard I try, I have yet to write any significant block of code that does not contain any errors. Nor have I been very good at predicting the wide range of crazy things users do with my applications. Why would anybody click on that link 73 times in a row? I'll never know.
Dealing with failures in a messaging scenario is very easy. The core of the failure strategy is to embrace errors. We have exceptions for a reason and to spend all of our time trying to predict and catch exceptions is counterproductive. You'll invariably spend time building in catches for errors that never happen and miss errors that happen frequently.
In an asynchronous system, errors need not be handled as soon as they occur. Instead, the message that caused an error can be put aside to be examined by an actual human later. The message is stored in a dead letter or error queue. From there, the message can easily be reprocessed after it has been corrected, or the handler has been corrected. Ideally, the message handler is changed to deal with messages exhibiting whatever property caused the errors. This prevents future errors and is preferable to fixing whatever generates the message, as there is no guarantee that other messages with the same problem aren't lurking somewhere else in the system:
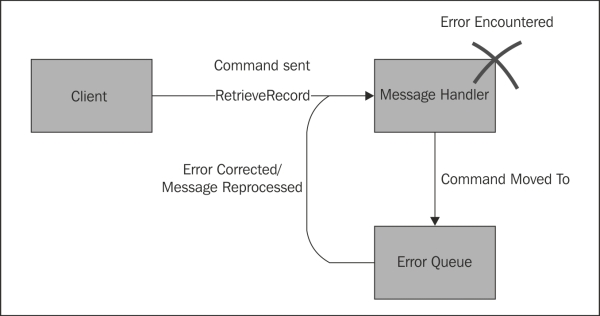
As more and more errors are caught and fixed, the quality of the message handlers increases. Having an error queue of messages ensures that nothing important, such as a BuySimonsBook message, is missed. This means that getting to a correct system becomes a marathon instead of a sprint. There is no need to rush a fix into production before it is properly tested. Progress towards a correct system is constant and reliable.
Using a dead-letter queue also improves the catching of intermittent errors. These are errors that result from an external resource being unavailable or incorrect. Imagine a handler that calls out to an external web service. In a traditional system, a failure in the web service guarantees a failure in the message handler. However, with a message-based system, the command can be moved back to the end of the input queue and tried again whenever it reaches the front of the queue. On the envelope, we write down the number of times the message has been dequeued (processed). Once this dequeue count reaches a limit, such as 5, only then is the message moved into the true error queue.
This approach improves the overall quality of the system by smoothing over the small failures and stopping them from becoming large failures. In effect, the queues provide failure bulkheads to prevent small errors from overflowing and becoming large errors that might have an impact on the system as a whole.
Message replay
When developers are working with a set of messages that produce an error, the ability to reprocess messages is also useful. Developers can take a snapshot of the dead-letter queue and reprocess it in debug mode again and again until they have correctly processed the messages. A snapshot of the message can also make up a part of the testing for a message handler.
Even without there being an error, the messages sent to a service on a daily basis are representative of the normal workflows of users. These messages can be mirrored to an audit queue as they enter into the system. The data from the audit queue can be used for testing. If a new feature is introduced, then a normal day's workload can be played back to ensure than there has been no degradation in either correct behavior or performance.
Of course, if the audit queue contains a list of all the messages, then it becomes trivial to understand how the application arrived at its current state. Frequently, people implement history by plugging in a lot of custom code or by using triggers and audit tables. Neither of these approaches do as good a job as messaging at understanding not only which data has changed but why it has changed. Once again, consider the address change scenario; without messaging we will likely never know why an address for a user is different from the pervious day.
Maintaining a good history of changes to system data is storage intensive but easily paid for by improving the life of even one auditor who can now see how and why each change was made. Well-constructed messages also allow for the history to contain the intent of the user making the change.
While it is possible to implement this sort of messaging system in a single process, it is difficult. Ensuring that messages are properly saved in the event of errors is difficult, as the entire process dealing with messages may crash, taking the internal message bus with it. Realistically, if the replaying of messages sounds like something worth investigating, then external message busses are the solution.
Pipes and filters
I mentioned earlier that messages should be considered to be immutable. This is not to say that messages cannot be rebroadcast with some properties changed or even broadcast as a new type of message. In fact, many message handlers may consume an event and then publish a new event after having performed some task.
As an example, you might consider the workflow to add a new user to a system:
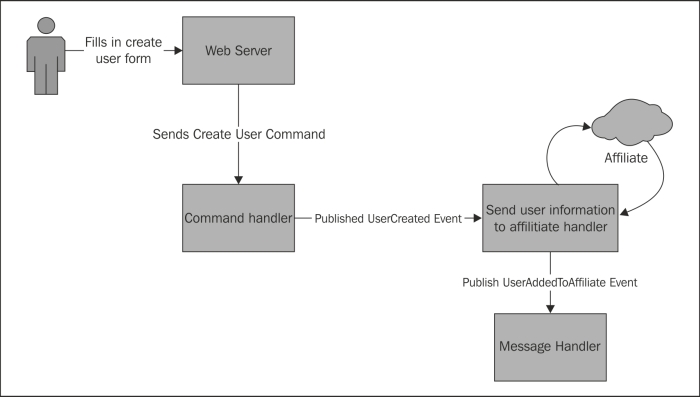
In this case, the
CreateUser command triggers a UserCreated event. That event is consumed by a number of different services. One of these services passes on user information to a select number of affiliates. As this service runs, it publishes its own set of events, one for each affiliate that receives the new user's details. These events may, in turn, be consumed by other services that could trigger their own events. In this way, changes can ripple through the entire application. However, no service knows more than what starts it and what events it publishes. This system has very low coupling. Plugging in new functionality is trivial and even removing functionality is easy, certainly easier than in a monolithic system.
Systems constructed using messaging and autonomous components are frequently referred to as using Service Oriented Architecture (SOA) or Microservices. There remains a great deal of debate as to the differences, if indeed there are any, between SOA and Microservices. We won't delve into it anymore here. Perhaps, by the time you're reading this book, the question would have been answered to everybody's satisfaction.
The altering and rebroadcasting of messages can be thought of as being a pipe or a filter. A service can proxy messages through to other consumers just as a pipe would do or can selectively republish messages as would be done by a filter.
Versioning messages
As systems evolve, the information contained in a message may also change. In our user creation example, we might have originally been asking for a name and e-mail address. However, the marketing department would like to be able to send e-mails addressed to Mr. Jones or Mrs. Jones, so we need to also collect the user's title. This is where message versioning comes in handy.
We can now create a new message that extends the previous message. The message can contain additional fields and might be named using the version number or a date. Thus, a message such as CreateUser might become CreateUserV1 or CreateUser20140101. Earlier I mentioned polymorphic messages. This is one approach to versioning messages. The new message extends the old, so all the old message handlers still fire. However, we also talked about how there are no real polymorphic capabilities in JavaScript.
Another option is to use upgrading message handlers. These handers will take in a version of the new message and modify it to be the old version. Obviously, the newer messages need to have at least as much data in them as the old version or have data that permits converting one message type to another.
If we had a v1 message that looked like this:
class CreateUserv1Message implements IMessage{
__messageName: string
UserName: string;
FirstName: string;
LastName: string;
EMail: string;
}And a v2 message that extended it adding a user title:
class CreateUserv2Message extends CreateUserv1Message implements IMessage{
UserTitle: string;
}Then we would be able to write a very simple upgrader or downgrader that looks like this:
var CreateUserv2tov1Downgrader = (function () {
function CreateUserv2tov1Downgrader (bus) {
this.bus = bus;
}
CreateUserv2tov1Downgrader.prototype.processMessage = function (message) {
message.__messageName = "CreateUserv1Message";
delete message.UserTitle;
this.bus.publish(message);
};
return CreateUserv2tov1Downgrader;
})();You can see that we simply modified the message and rebroadcasted it.
Message replay
When developers are working with a set of messages that produce an error, the ability to reprocess messages is also useful. Developers can take a snapshot of the dead-letter queue and reprocess it in debug mode again and again until they have correctly processed the messages. A snapshot of the message can also make up a part of the testing for a message handler.
Even without there being an error, the messages sent to a service on a daily basis are representative of the normal workflows of users. These messages can be mirrored to an audit queue as they enter into the system. The data from the audit queue can be used for testing. If a new feature is introduced, then a normal day's workload can be played back to ensure than there has been no degradation in either correct behavior or performance.
Of course, if the audit queue contains a list of all the messages, then it becomes trivial to understand how the application arrived at its current state. Frequently, people implement history by plugging in a lot of custom code or by using triggers and audit tables. Neither of these approaches do as good a job as messaging at understanding not only which data has changed but why it has changed. Once again, consider the address change scenario; without messaging we will likely never know why an address for a user is different from the pervious day.
Maintaining a good history of changes to system data is storage intensive but easily paid for by improving the life of even one auditor who can now see how and why each change was made. Well-constructed messages also allow for the history to contain the intent of the user making the change.
While it is possible to implement this sort of messaging system in a single process, it is difficult. Ensuring that messages are properly saved in the event of errors is difficult, as the entire process dealing with messages may crash, taking the internal message bus with it. Realistically, if the replaying of messages sounds like something worth investigating, then external message busses are the solution.
Pipes and filters
I mentioned earlier that messages should be considered to be immutable. This is not to say that messages cannot be rebroadcast with some properties changed or even broadcast as a new type of message. In fact, many message handlers may consume an event and then publish a new event after having performed some task.
As an example, you might consider the workflow to add a new user to a system:
In this case, the
CreateUser command triggers a UserCreated event. That event is consumed by a number of different services. One of these services passes on user information to a select number of affiliates. As this service runs, it publishes its own set of events, one for each affiliate that receives the new user's details. These events may, in turn, be consumed by other services that could trigger their own events. In this way, changes can ripple through the entire application. However, no service knows more than what starts it and what events it publishes. This system has very low coupling. Plugging in new functionality is trivial and even removing functionality is easy, certainly easier than in a monolithic system.
Systems constructed using messaging and autonomous components are frequently referred to as using Service Oriented Architecture (SOA) or Microservices. There remains a great deal of debate as to the differences, if indeed there are any, between SOA and Microservices. We won't delve into it anymore here. Perhaps, by the time you're reading this book, the question would have been answered to everybody's satisfaction.
The altering and rebroadcasting of messages can be thought of as being a pipe or a filter. A service can proxy messages through to other consumers just as a pipe would do or can selectively republish messages as would be done by a filter.
Versioning messages
As systems evolve, the information contained in a message may also change. In our user creation example, we might have originally been asking for a name and e-mail address. However, the marketing department would like to be able to send e-mails addressed to Mr. Jones or Mrs. Jones, so we need to also collect the user's title. This is where message versioning comes in handy.
We can now create a new message that extends the previous message. The message can contain additional fields and might be named using the version number or a date. Thus, a message such as CreateUser might become CreateUserV1 or CreateUser20140101. Earlier I mentioned polymorphic messages. This is one approach to versioning messages. The new message extends the old, so all the old message handlers still fire. However, we also talked about how there are no real polymorphic capabilities in JavaScript.
Another option is to use upgrading message handlers. These handers will take in a version of the new message and modify it to be the old version. Obviously, the newer messages need to have at least as much data in them as the old version or have data that permits converting one message type to another.
If we had a v1 message that looked like this:
class CreateUserv1Message implements IMessage{
__messageName: string
UserName: string;
FirstName: string;
LastName: string;
EMail: string;
}And a v2 message that extended it adding a user title:
class CreateUserv2Message extends CreateUserv1Message implements IMessage{
UserTitle: string;
}Then we would be able to write a very simple upgrader or downgrader that looks like this:
var CreateUserv2tov1Downgrader = (function () {
function CreateUserv2tov1Downgrader (bus) {
this.bus = bus;
}
CreateUserv2tov1Downgrader.prototype.processMessage = function (message) {
message.__messageName = "CreateUserv1Message";
delete message.UserTitle;
this.bus.publish(message);
};
return CreateUserv2tov1Downgrader;
})();You can see that we simply modified the message and rebroadcasted it.
Pipes and filters
I mentioned earlier that messages should be considered to be immutable. This is not to say that messages cannot be rebroadcast with some properties changed or even broadcast as a new type of message. In fact, many message handlers may consume an event and then publish a new event after having performed some task.
As an example, you might consider the workflow to add a new user to a system:
In this case, the
CreateUser command triggers a UserCreated event. That event is consumed by a number of different services. One of these services passes on user information to a select number of affiliates. As this service runs, it publishes its own set of events, one for each affiliate that receives the new user's details. These events may, in turn, be consumed by other services that could trigger their own events. In this way, changes can ripple through the entire application. However, no service knows more than what starts it and what events it publishes. This system has very low coupling. Plugging in new functionality is trivial and even removing functionality is easy, certainly easier than in a monolithic system.
Systems constructed using messaging and autonomous components are frequently referred to as using Service Oriented Architecture (SOA) or Microservices. There remains a great deal of debate as to the differences, if indeed there are any, between SOA and Microservices. We won't delve into it anymore here. Perhaps, by the time you're reading this book, the question would have been answered to everybody's satisfaction.
The altering and rebroadcasting of messages can be thought of as being a pipe or a filter. A service can proxy messages through to other consumers just as a pipe would do or can selectively republish messages as would be done by a filter.
Versioning messages
As systems evolve, the information contained in a message may also change. In our user creation example, we might have originally been asking for a name and e-mail address. However, the marketing department would like to be able to send e-mails addressed to Mr. Jones or Mrs. Jones, so we need to also collect the user's title. This is where message versioning comes in handy.
We can now create a new message that extends the previous message. The message can contain additional fields and might be named using the version number or a date. Thus, a message such as CreateUser might become CreateUserV1 or CreateUser20140101. Earlier I mentioned polymorphic messages. This is one approach to versioning messages. The new message extends the old, so all the old message handlers still fire. However, we also talked about how there are no real polymorphic capabilities in JavaScript.
Another option is to use upgrading message handlers. These handers will take in a version of the new message and modify it to be the old version. Obviously, the newer messages need to have at least as much data in them as the old version or have data that permits converting one message type to another.
If we had a v1 message that looked like this:
class CreateUserv1Message implements IMessage{
__messageName: string
UserName: string;
FirstName: string;
LastName: string;
EMail: string;
}And a v2 message that extended it adding a user title:
class CreateUserv2Message extends CreateUserv1Message implements IMessage{
UserTitle: string;
}Then we would be able to write a very simple upgrader or downgrader that looks like this:
var CreateUserv2tov1Downgrader = (function () {
function CreateUserv2tov1Downgrader (bus) {
this.bus = bus;
}
CreateUserv2tov1Downgrader.prototype.processMessage = function (message) {
message.__messageName = "CreateUserv1Message";
delete message.UserTitle;
this.bus.publish(message);
};
return CreateUserv2tov1Downgrader;
})();You can see that we simply modified the message and rebroadcasted it.
Versioning messages
As systems evolve, the information contained in a message may also change. In our user creation example, we might have originally been asking for a name and e-mail address. However, the marketing department would like to be able to send e-mails addressed to Mr. Jones or Mrs. Jones, so we need to also collect the user's title. This is where message versioning comes in handy.
We can now create a new message that extends the previous message. The message can contain additional fields and might be named using the version number or a date. Thus, a message such as CreateUser might become CreateUserV1 or CreateUser20140101. Earlier I mentioned polymorphic messages. This is one approach to versioning messages. The new message extends the old, so all the old message handlers still fire. However, we also talked about how there are no real polymorphic capabilities in JavaScript.
Another option is to use upgrading message handlers. These handers will take in a version of the new message and modify it to be the old version. Obviously, the newer messages need to have at least as much data in them as the old version or have data that permits converting one message type to another.
If we had a v1 message that looked like this:
class CreateUserv1Message implements IMessage{
__messageName: string
UserName: string;
FirstName: string;
LastName: string;
EMail: string;
}And a v2 message that extended it adding a user title:
class CreateUserv2Message extends CreateUserv1Message implements IMessage{
UserTitle: string;
}Then we would be able to write a very simple upgrader or downgrader that looks like this:
var CreateUserv2tov1Downgrader = (function () {
function CreateUserv2tov1Downgrader (bus) {
this.bus = bus;
}
CreateUserv2tov1Downgrader.prototype.processMessage = function (message) {
message.__messageName = "CreateUserv1Message";
delete message.UserTitle;
this.bus.publish(message);
};
return CreateUserv2tov1Downgrader;
})();You can see that we simply modified the message and rebroadcasted it.
Hints and tips
Messages create a well-defined interface between two different systems. Defining messages should be done by members of both teams. Establishing a common language can be tricky especially as terms are overloaded between different business units. What sales considers a customer may be totally different from what shipping considers a customer. Domain-driven design provides some hints as to how boundaries can be established to avoid mixing terms.
There is a huge preponderance of queue technologies available. Each of them have a bunch of different properties around reliability, durability, and speed. Some of the queues support reading and writing JSON over HTTP, ideal for those interested in building JavaScript applications. Which queue is appropriate for your application is a topic for some research.
Summary
Messaging and the associated patterns are a large topic. Delving too deeply into messages will bring you into contact with DDD and command query responsibility segregation (CQRS), as well as touching on high performance computing solutions.
There is substantial research and discussion ongoing as to the best way to build large systems. Messaging is one possible solution that avoids creating a big ball of mud that is difficult to maintain and fragile to change. Messaging provides natural boundaries between components in a system and the messages themselves provide for a consistent API.
Not every application benefits from messaging. There is additional overhead to building a loosely coupled application such as this. Applications that are collaborative, ones where losing data is especially undesirable and those that benefit from a strong history story, are good candidates for messaging. In most cases, a standard CRUD application will be sufficient. It is still worthwhile to know about messaging patterns, as they will offer alternative thinking.
In this chapter, we've taken a look at a number of different messaging patterns and how they can be applied to common scenarios. The differences between commands and events were also explored.
In the next chapter, we'll look at some patterns to make testing code a little bit easier. Testing is jolly important, so read on!



