






















































Evaluation metrics
In many cases, it's impossible to evaluate the performance of a clustering algorithm using only a visual inspection. Moreover, it's important to use standard objective metrics that allow us to compare different approaches.
We are now going to introduce some methods based on the knowledge of the ground truth (the correct assignment for each data point) and one common strategy employed when the true labels are unknown.
Before discussing the scoring functions, we need to introduce a standard notation. If there are k clusters, we define the true labels as:
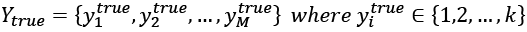
In the same way, we can define the predicted labels:
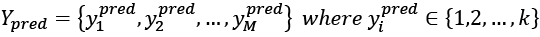
Both sets can be considered as sampled from two discrete random variables (for simplicity, we denote them with the same names), whose probability mass functions are  and
and  with a generic
with a generic  (yi represents the index of the ith cluster). These two probabilities can be approximated with a frequency count; so, for example, the probability...
(yi represents the index of the ith cluster). These two probabilities can be approximated with a frequency count; so, for example, the probability...





