






















































Evaluation of recommendation engine model
Evaluation of any model needs to be calculated in order to determine how good the model is with respect to the actual data so that its performance can be improved by tuning hyperparameters and so on. In fact, the entire machine learning algorithm's accuracy is measured based on its type of problem. In the case of classification problems, confusion matrix, whereas in regression problems, mean squared error or adjusted R-squared values need to be computed.
Mean squared error is a direct measure of the reconstruction error of the original sparse user-item matrix (also called A) with two low-dimensional dense matrices (X and Y). It is also the objective function which is being minimized across the iterations:
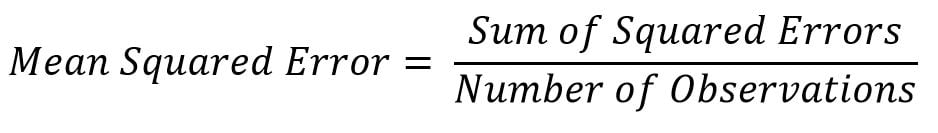

Root mean squared errors provide the dimension equivalent to the original dimension of the variable measure, hence we can analyze how much magnitude the error component has with the original value. In our example, we have computed the root mean square...






















