






















































A pivot table is a summary table. It is the most popular concept in Excel. Most data analysts use it as a handy tool to summarize theire results. pandas offers the pivot_table() function to summarize DataFrames. A DataFrame is summarized using an aggregate function, such as mean, min, max, or sum. You can download the dataset from the following GitHub link: https://github.com/PacktPublishing/Python-Data-Analysis-Third-Edition/tree/master/Python-Data-Analysis-Third-Edition/Ch2:
# Import pandas
import pandas as pd
# Load data using read_csv()
purchase = pd.read_csv("purchase.csv")
# Show initial 10 records
purchase.head(10)
This results in the following output:
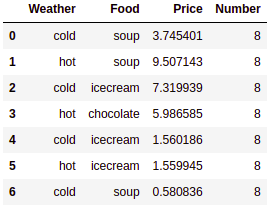
In the preceding code block, we have read the purchase.csv file using the read_csv() method.
Now, we will summarize the dataframe using the following code:
# Summarise dataframe using pivot table
pd.pivot_table(purchase,values='Number', index=['Weather',],
columns...






















