






















































Random forests
A random forest is the bagging ensemble model based on decision trees. If the reader is not familiar with this kind of model, I suggest reading the Introduction to Machine Learning, Alpaydin E., The MIT Press, where a complete explanation can be found. However, for our purposes, it's useful to provide a brief explanation of the most important concepts. A decision tree is a model that resembles a standard hierarchical decision process. In the majority of cases, a special family is employed, called binary decision trees, as each decision yields only two outcomes. This kind of tree is often the simplest and most reasonable choice and the training process (which consists in building the tree itself) is very intuitive. The root contains the whole dataset:
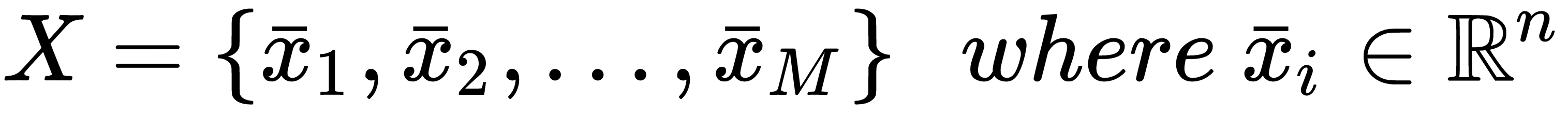
Each level is obtained by applying a selection tuple, defined as follows:

The first index of the tuple corresponds to an input feature, while the threshold ti is a value chosen in the specific range of each feature. The application...

