






















































Classification metrics
A classification task can be evaluated in many different ways to achieve specific objectives. Of course, the most important metric is the accuracy, often expressed as:
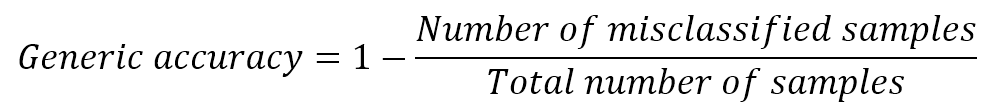
In scikit-learn, it can be assessed using the built-in accuracy_score() function:
from sklearn.metrics import accuracy_score >>> accuracy_score(Y_test, lr.predict(X_test)) 0.94399999999999995
Another very common approach is based on zero-one loss function, which we saw in Chapter 2, Important Elements in Machine Learning, which is defined as the normalized average of L0/1 (where 1 is assigned to misclassifications) over all samples. In the following example, we show a normalized score (if it's close to 0, it's better) and then the same unnormalized value (which is the actual number of misclassifications):
from sklearn.metrics import zero_one_loss >>> zero_one_loss(Y_test, lr.predict(X_test)) 0.05600000000000005 >>> zero_one_loss(Y_test, lr.predict(X_test), normalize=False) 7L...












