






















































For our project, we will use a pretty simple network with the following architecture:
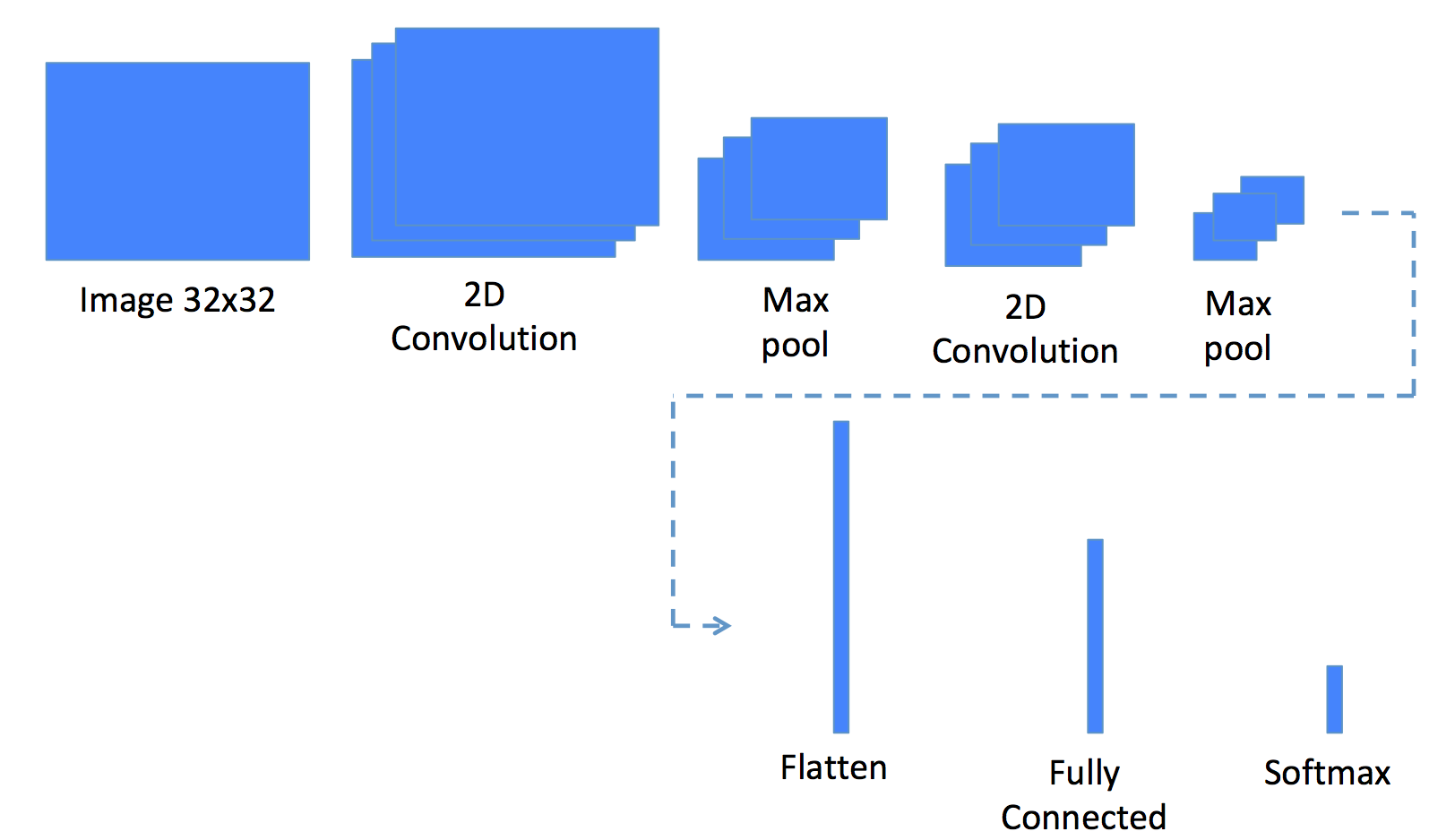
In this architecture, we still have the choice of:
- The number of filters and kernel size in the 2D convolution
- The kernel size in the Max pool
- The number of units in the Fully Connected layer
- The batch size, optimization algorithm, learning step (eventually, its decay rate), activation function of each layer, and number of epochs











