






















































Controlling variable ownership
As we remember from the beginning of the chapter, Rust does not have a garbage collector. However, it has memory safety. It achieves this by having strict rules around variable ownership. These rules are enforced when Rust is being compiled. If you are coming from a dynamic language, then this can initially lead to frustration. This is known as fighting the borrow checker. Sadly, this unjustly gives Rust the false steep learning curve reputation, as when you are fighting the borrow checker without knowing what is going on, it can seem like an impossible task to get even the most basic programs written. However, if we take the time to learn the rules before we try and code anything too complex, the knowledge of the rules and the helpfulness of the compiler will make writing code in Rust fun and rewarding. Again, I take the time to remind you that Rust has been the most favorited language 7 years in a row. This is not because it’s impossible to get anything done in it. The people who vote for Rust in these surveys understand the rules around ownership. Rust’s compiling, checking, and enforcing of these rules protect against the following errors:
- Use after frees: This occurs when memory is accessed once it has been freed, which can cause crashes. It can also allow hackers to execute code via this memory address.
- Dangling pointers: This occurs when a reference points to a memory address that no longer houses the data that the pointer was referencing. Essentially, this pointer now points to null or random data.
- Double frees: This occurs when allocated memory is freed and then freed again. This can cause the program to crash and increases the risk of sensitive data being revealed. This also enables a hacker to execute arbitrary code.
- Segmentation faults: This occurs when the program tries to access the memory it’s not allowed to access.
- Buffer overrun: An example of this error is reading off the end of an array. This can cause the program to crash.
To protect against these errors and thus achieve memory safety, Rust enforces the following rules:
- Values are owned by the variables assigned to them
- As soon as the variable moves out of the scope of where it was defined, it is then deallocated from the memory
- Values can be referenced and altered if we adhere to the rules for copying, moving, immutable borrowing, and mutable borrowing
Knowing the rules is one thing but, to practically work with the rules in Rust code, we need to understand copying, moving, and borrowing in more detail.
Copying variables
Copying occurs when a value is copied. Once it has been copied, the new variable owns the value, while the existing variable also owns its own value.
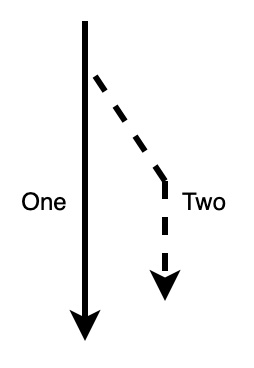
Figure 1.5 – Variable copy path
In Figure 1.5, we can see that the path of One is still solid, which denotes that it has not been interrupted and can be handled as if the copy did not happen. Path Two is merely a copy, and there is also no difference in the way in which it can be utilized as if it were self-defined. It must be noted that if the variable has a copy trait, then it will automatically be copied, as seen in the following code:
let one: i8 = 10;
let two: i8 = one + 5;
println!("{}", one);
println!("{}", two);
Running the preceding code will give us the following printout:
10 15
In the preceding example, we appreciate that the very fact that variables one and two can be printed indicates that one has been copied for two to utilize. To test this, we can test our example with strings using the following code:
let one = "one".to_string();
let two = one;
println!("{}", one);
println!("{}", two);
Running this code will result in the following error:
move occurs because `one` has type `String`, which does not implement the `Copy` trait
Because strings do not implement the Copy trait, the code does not work, as one was moved to two. However, the code will run if we get rid of println!("{}", one);. This brings us to the next concept that we must understand: moving.
Moving variables
Moving refers to when the value is moved from one variable to another. However, unlike copying, the original variable no longer owns the value.

Figure 1.6 – Variable move path
From what we can see in Figure 1.6, one can no longer be accessed once it’s moved to two. To really establish what is going on here and how strings are affected, we can set up some code designed to fail as follows:
let one: String = String::from("one");
let two: String = one + " two";
println!("{}", two);
println!("{}", one);
Running the preceding code gives the following error:
let one: String = String::from("one");
--- move occurs because `one` has type
`String`, which does not implement the
`Copy` trait
let two: String = one + " two";
------------ `one` moved due to usage in operator
println!("{}", two);
println!("{}", one);
^^^ value borrowed here after move
As we can see, the compiler has been helpful here. It shows us where the string was moved to and where the value of that string is borrowed. So, we can make the code run instantly by merely removing the println!("{}", one); line. However, we want to be able to use that print function at the bottom of the preceding code block. We should not have to constrain the functionality of the code due to the rules implemented by Rust. We can solve this by using the to_owned function with the following code:
let two: String = one.to_owned() + " two";
The to_owned function is available because strings implement the ToOwned trait. We will cover traits later in the chapter, so do not halt your reading if you do not know what this means yet. We could have used clone on the string. We must note that to_owned is a generalized implementation of clone. However, it does not really matter which approach we use. It is understandable to wonder why strings do not have the Copy trait. This is because the string is a pointer to a string literal. If we were to copy strings, we would have multiple unconstrained pointers to the same string literal data, which would be dangerous. Because of this, we can explore the move concept using strings. If we force our string outside of the scope with a function, we can see how this affects our move. This can be done with the following code:
fn print(value: String) {
println!("{}", value);
}
fn main() {
let one = "one".to_string();
print(one);
println!("{}", one);
}
If we run the preceding code, we will get an error stating that the print function moved the one value. As a result, the println!("{}", one); line borrows one after it is moved into the print function. The key part of this message is the word borrow. To understand what is going on, we need to explore the concept of immutable borrowing.
Immutable borrowing of variables
An immutable borrow occurs when a variable can be referenced by another variable without having to clone or copy it. This essentially solves our problem. If the borrowed variable falls out of scope, then it is not deallocated from the memory and the original reference to the value can still be used.
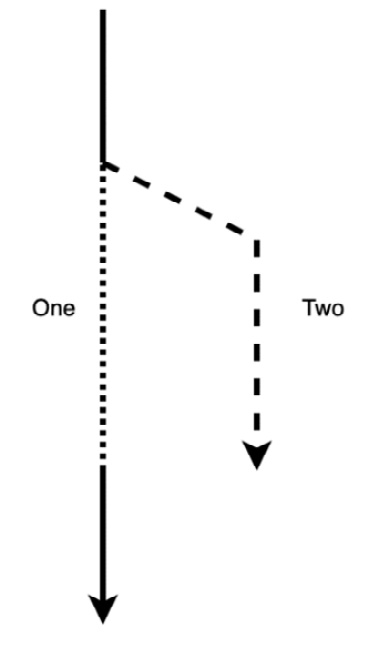
Figure 1.7 – Immutable borrow path
We can see in Figure 1.7 that two borrows the value from one. It must be noted that when one is borrowed from, one is locked and cannot be accessed until the borrow is finished. To perform a borrow operation, we merely apply a prefix with &. This can be demonstrated with the following code:
fn print(value: &String) {
println!("{}", value);
}
fn main() {
let one = "one".to_string();
print(&one);
println!("{}", one);
}
In the preceding code, we can see that our immutable borrow enables us to pass a string into the print function and still print it afterward. This can be confirmed with the following printout:
one one
From what we see in our code, the immutable borrow that we performed can be demonstrated in Figure 1.8.
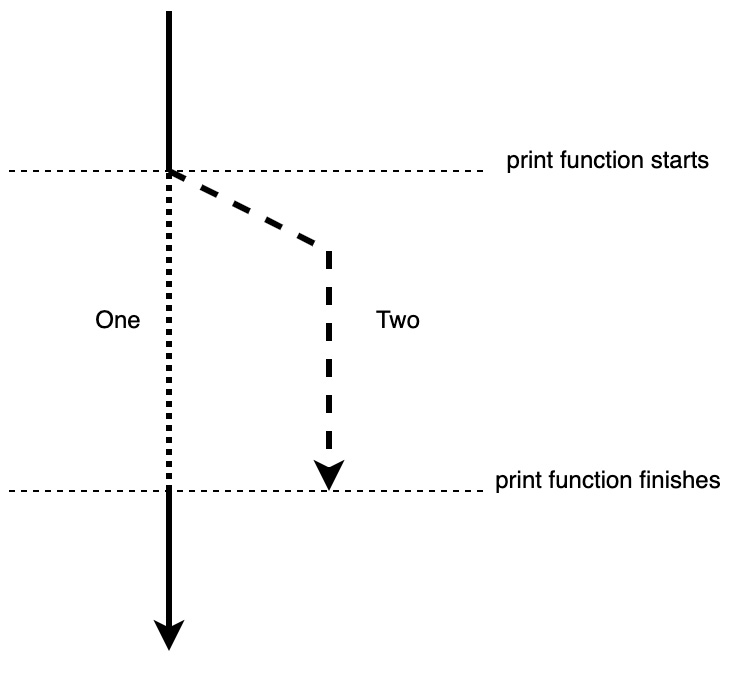
Figure 1.8 – Immutable borrow in relation to the print function
In the preceding figure, we can see that one is not available when the print function is running. We can demonstrate this with the following code:
fn print(value: &String, value_two: String) {
println!("{}", value);
println!("{}", value_two);
}
fn main() {
let one = "one".to_string();
print(&one, one);
println!("{}", one);
}
If we run the preceding code, we will get the following error:
print(&one, one); ----- ---- ^^^ move out of `one` occurs here | | | borrow of `one` occurs here borrow later used by call
We can see that we cannot utilize one even though it is utilized in the print function after &one. This is because the lifetime of &one is throughout the entire lifetime of the print function. Thus, we can conclude that Figure 1.8 is correct. However, we can run one more experiment. We can change value_one to a borrow to see what happens with the following code:
fn print(value: &String, value_two: &String) {
println!("{}", value);
println!("{}", value_two);
}
fn main() {
let one = "one".to_string();
print(&one, &one);
println!("{}", one);
}
In the preceding code, we can see that we do two immutable borrows of one, and the code runs. This highlights an important fact: we can make as many immutable borrows as we like. However, what happens if the borrow is mutable? To understand, we must explore mutable borrows.
Mutable borrowing of variables
A mutable borrow is essentially the same as an immutable borrow, except that the borrow is mutable. Therefore, we can change the borrowed value. To demonstrate this, we can create a print statement that will alter the borrowed value before printing it. We then print it in the main function to establish that the value has been changed with the following code:
fn print(value: &mut i8) {
value += 1;
println!("In function the value is: {}", value);
}
fn main() {
let mut one: i8 = 5;
print(&mut one);
println!("In main the value is: {}", one);
}
Running the preceding code will give us the following printout:
In function the value is: 6 In main the value is: 6
The preceding output proves that one is 6 even after the lifetime of the mutable reference in the print function has expired. We can see that in the print function, we update the value of one using a * operator. This is called a dereference operator. This dereference operator exposes the underlying value so it can be operated. This all seems straightforward, but is it exactly like our immutable references? If we remember, we could have multiple immutable references. We can put this to the test with the following code:
fn print(value: &mut i8, value_two: &mut i8) {
value += 1;
println!("In function the value is: {}", value);
value_two += 1;
}
fn main() {
let mut one: i8 = 5;
print(&mut one, &mut one);
println!("In main the value is: {}", one);
}
In the preceding code, we can see that we make two mutable references and pass them through, just like in the previous section, but with immutable references. However, running it gives us the following error:
error[E0499]: cannot borrow `one` as mutable more than once at a time
Through this example, we can confirm that we cannot have more than one mutable reference at a time. This prevents data races and has given Rust the fearless concurrency tag. With what we have covered here, we can now be productive when the compiler is combined with the borrow checker. However, we have touched on the concepts of scope and lifetimes. The use of them has been intuitive, but like the rules around borrowing, we need to dive into scopes and then lifetimes in more detail.
Scopes
To understand scopes, let us go back to how we declare variables. You will have noticed that when we declare a new variable, we use let. When we do, that variable is the only one that owns the resource. Therefore, if the value is moved or reassigned, then the initial variable no longer owns the value. When a variable is moved, it is essentially moved into another scope. Variables declared in an outer scope can be referenced in an inner scope, but a variable declared in an inner scope cannot be accessed in the inner scope once the inner scope has expired. We can break down some code into scopes in the following diagram:
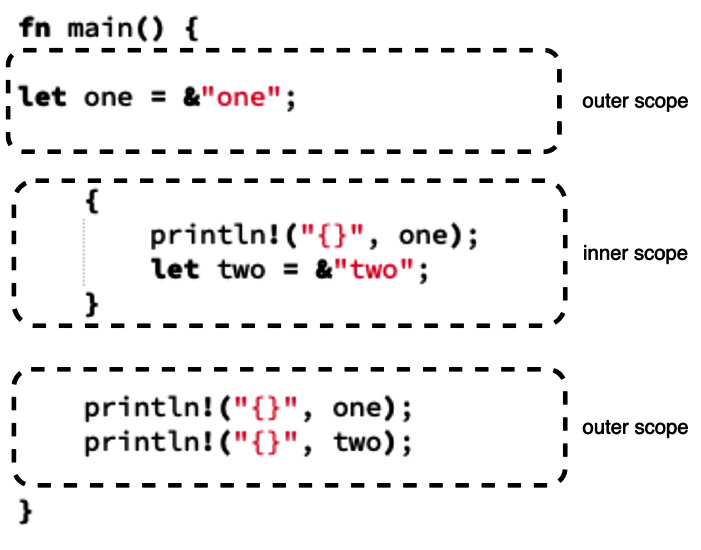
Figure 1.9 – Basic Rust code broken into scopes
Figure 1.9 shows us that we can create an inner scope by merely using curly brackets. Applying what we just learned about scopes to Figure 1.9, can you work out whether it will crash? If it will crash, how will it?
If you guessed that it would result in a compiler error, then you are correct. Running the code would result in the following error:
println!("{}", two);
^^^ not found in this scope
Because one is defined in the inner scope, we will not be able to reference it in the outer scope. We can solve this problem by declaring the variable in the outer scope but assigning the value in the inner scope with the following code:
fn main() {
let one = &"one";
let two: &str;
{
println!("{}", one);
two = &"two";
}
println!("{}", one);
println!("{}", two);
}
In the preceding code, we can see that we do not use let when assigning the value because we have already declared the variable in the outer scope. Running the preceding code gives us the following printout:
one one two
We also must remember that if we move a variable into a function, then the variable gets destroyed once the scope of the function finishes. We cannot access the variable after the execution of the function, even though we declared the variable before the execution of the function. This is because once the variable has been moved into the function, it is no longer in the original scope. It has been moved. And because it has been moved to that scope, it is then bound to the lifetime of the scope that it was moved into. This brings us to our next section: lifetimes.
Running through lifetimes
Understanding lifetimes will wrap up our exploration of borrowing rules and scopes. We can explore the effect of lifetimes with the following code:
fn main() {
let one: &i8;
{
let two: i8 = 2;
one = &two;
} // -----------------------> two lifetime stops here
println!("r: {}", one);
}
With the preceding code, we declare one before the inner scope starts. However, we assign it to have a reference of two. two only has the lifetime of the inner scope, so the lifetime dies before we try and print it out. This is established with the following error:
one = &two; } println!("r: {}", one);}
^^^^ - --- borrow later used here
| |
| `two` dropped here while still borrowed
borrowed value does not live long enough
two is dropped when the lifetime of two has finished. With this, we can state that the lifetimes of one and two are not equal.
While it is great that this is flagged when compiling, Rust does not stop here. This concept also applies to functions. Let’s say that we build a function that references two integers, compares them, and returns the highest integer reference. The function is an isolated piece of code. In this function, we can denote the lifetimes of the two integers. This is done by using the ' prefix, which is a lifetime notation. The names of the notations can be anything you come up with, but it is convention to use a, b, c, and so on. We can explore this by creating a simple function that takes in two integers and returns the highest one with the following code:
fn get_highest<'a>(first_number: &'a i8, second_number: &'a
i8) -> &'a i8 {
if first_number > second_number {
first_number
} else {
second_number
}
}
fn main() {
let one: i8 = 1;
let outcome: &i8;
{
let two: i8 = 2;
let outcome: &i8 = get_highest(&one, &two);
}
println!("{}", outcome);
}
As we can see, the first and second lifetimes have the same notation of a. They both must be present for the duration of the function. We also must note that the function returns an i8 integer with the lifetime of a. If we were to try and use lifetime notation on function parameters without a borrow, we would get some very confusing errors. In short, it is not possible to use lifetime notation without a borrow. This is because if we do not use a borrow, the value passed into the function is moved into the function. Therefore, its lifetime is the lifetime of the function. This seems straightforward; however, when we run it, we get the following error:
println!("{}", outcome);}
^^^^^^^ use of possibly-uninitialized `outcome`
The error occurs because all the lifetimes of the parameters passed into the function and the returned integer are the same. Therefore, the compiler does not know what could be returned. As a result, two could be returned. If two is returned, then the result of the function will not live long enough to be printed. However, if one is returned, then it will. Therefore, there is a possibility of not having a value to print after the inner scope is executed. In a dynamic language, we would be able to run code that runs the risk of referencing variables that have not been initialized yet. However, with Rust, we can see that if there is a possibility of an error like this, it will not compile. In the short term, it might seem like Rust takes longer to code, but as the project progresses, this strictness will save a lot of time by preventing silent bugs. In conclusion of our error, there is no way of solving our problem with the exact function and main layout that we have. We would either have to move our printing of the outcome into the inner scope or clone the integers and pass them into the function.
We can create one more function to explore functions with different lifetime parameters. This time we will create a filter function. If the first number is lower than the second number, we will then return 0. Otherwise, we will return the first number. This can be achieved with the following code:
fn filter<'a, 'b>(first_number: &'a i8, second_number: &'b
i8) -> &'a i8 {
if first_number < second_number {
&0
} else {
first_number
}
}
fn main() {
let one: i8 = 1;
let outcome: &i8;
{
let two: i8 = 2;
outcome = filter(&one, &two);
}
println!("{}", outcome);
}
The preceding code works because we know the lifetimes are different. The first parameter has the same lifetime as the returned integer. If we were to implement filter(&two, &one) instead, we would get an error stating that the outcome does not live long enough to be printed. We have now covered all that we need to know for now to write productive code in Rust without the borrow checker getting in our way. We now need to move on to creating bigger building blocks for our programs so we can focus on tackling the complex problems we want to solve with code. We will start this with a versatile building block of programs: structs.


