























































In the real world, we usually have to deal with a lot of raw data. This raw data is not readily ingestible by machine learning algorithms. To prepare data for machine learning, we have to preprocess it before we feed it into various algorithms. This is an intensive process that takes plenty of time, almost 80 percent of the entire data analysis process, in some scenarios. However, it is vital for the rest of the data analysis workflow, so it is necessary to learn the best practices of these techniques. Before sending our data to any machine learning algorithm, we need to cross check the quality and accuracy of the data. If we are unable to reach the data stored in Python correctly, or if we can't switch from raw data to something that can be analyzed, we cannot go ahead. Data can be preprocessed in many ways—standardization, scaling, normalization, binarization, and one-hot encoding are some examples of preprocessing techniques. We will address them through simple examples.
Data preprocessing using mean removal
Getting ready
Standardization or mean removal is a technique that simply centers data by removing the average value of each characteristic, and then scales it by dividing non-constant characteristics by their standard deviation. It's usually beneficial to remove the mean from each feature so that it's centered on zero. This helps us remove bias from features. The formula used to achieve this is the following:
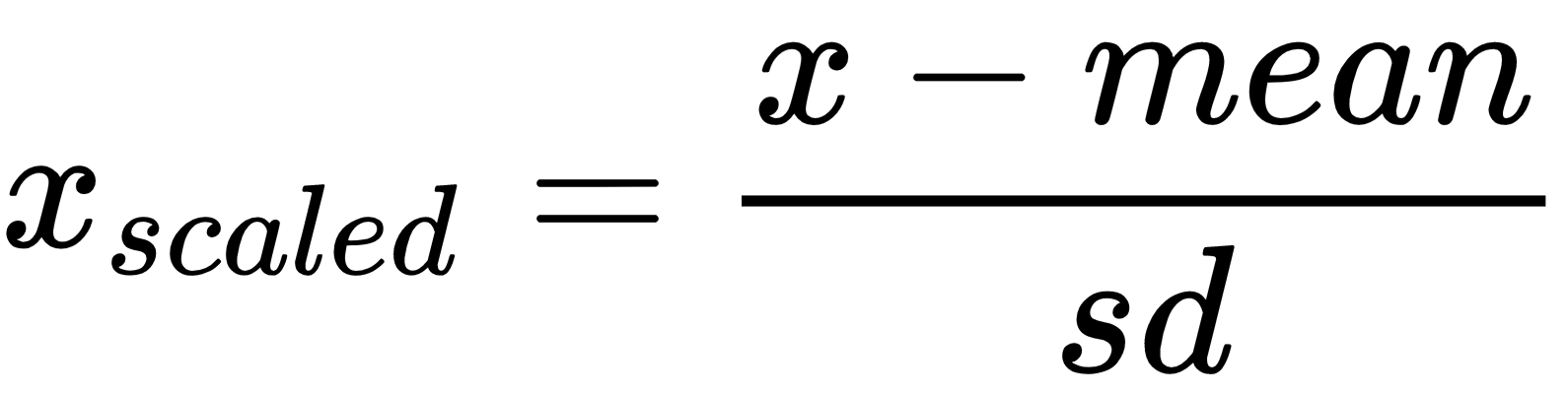
Standardization results in the rescaling of features, which in turn represents the properties of a standard normal distribution:
- mean = 0
- sd = 1
In this formula, mean is the mean and sd is the standard deviation from the mean.
How to do it...
Let's see how to preprocess data in Python:
- Let's start by importing the library:
>> from sklearn import preprocessing
The sklearn library is a free software machine learning library for the Python programming language. It features various classification, regression, and clustering algorithms, including support vector machines (SVMs), random forests, gradient boosting, k-means, and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries, NumPy and SciPy.
- To understand the outcome of mean removal on our data, we first visualize the mean and standard deviation of the vector we have just created:
>> print("Mean: ",data.mean(axis=0))
>> print("Standard Deviation: ",data.std(axis=0))
The mean() function returns the sample arithmetic mean of data, which can be a sequence or an iterator. The std() function returns the standard deviation, a measure of the distribution of the array elements. The axis parameter specifies the axis along which these functions are computed (0 for columns, and 1 for rows).
The following results are returned:
Mean: [ 1.33333333 1.93333333 -0.06666667 -2.53333333]
Standard Deviation: [1.24721913 2.44449495 1.60069429 3.30689515]
- Now we can proceed with standardization:
>> data_standardized = preprocessing.scale(data)
The preprocessing.scale() function standardizes a dataset along any axis. This method centers the data on the mean and resizes the components in order to have a unit variance.
- Now we recalculate the mean and standard deviation on the standardized data:
>> print("Mean standardized data: ",data_standardized.mean(axis=0))
>> print("Standard Deviation standardized data: ",data_standardized.std(axis=0))
The following results are returned:
Mean standardized data: [ 5.55111512e-17 -1.11022302e-16 -7.40148683e-17 -7.40148683e-17]
Standard Deviation standardized data: [1. 1. 1. 1.]
You can see that the mean is almost 0 and the standard deviation is 1.
How it works...
The sklearn.preprocessing package provides several common utility functions and transformer classes to modify the features available in a representation that best suits our needs. In this recipe, the scale() function has been used (z-score standardization). In summary, the z-score (also called the standard score) represents the number of standard deviations by which the value of an observation point or data is greater than the mean value of what is observed or measured. Values more than the mean have positive z-scores, while values less than the mean have negative z-scores. The z-score is a quantity without dimensions that is obtained by subtracting the population's mean from a single rough score and then dividing the difference by the standard deviation of the population.
There's more...
Standardization is particularly useful when we do not know the minimum and maximum for data distribution. In this case, it is not possible to use other forms of data transformation. As a result of the transformation, the normalized values do not have a minimum and a fixed maximum. Moreover, this technique is not influenced by the presence of outliers, or at least not the same as other methods.
See also
- Scikit-learn's official documentation of the sklearn.preprocessing.scale() function: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.scale.html.






















