H2O is an open source, machine learning platform that plays extremely well with Spark; in fact, it was one of the first third-party packages deemed "Certified on Spark".

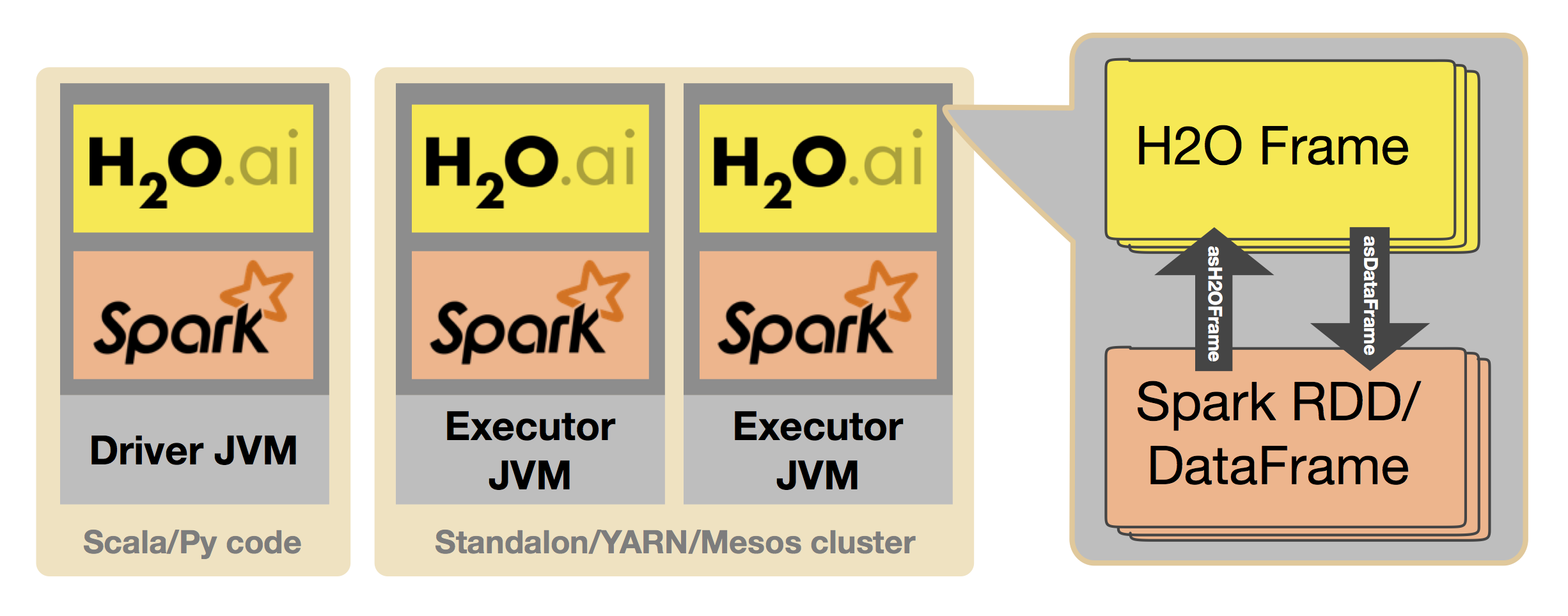
Sparkling Water (H2O + Spark) is H2O's integration of their platform within the Spark project, which combines the machine learning capabilities of H2O with all the functionality of Spark. This means that users can run H2O algorithms on Spark RDD/DataFrame for both exploration and deployment purposes. This is made possible because H2O and Spark share the same JVM, which allows for seamless transitions between the two platforms. H2O stores data in the H2O frame, which is a columnar-compressed representation of your dataset that can be created from Spark RDD and/or DataFrame. Throughout much of this book, we will be referencing algorithms from Spark's MLlib library and H2O's platform, showing how to use both the libraries to get the best results possible for a given task.
The following is a summary of the features Sparkling Water comes equipped with:
- Use of H2O algorithms within a Spark workflow
- Transformations between Spark and H2O data structures
- Use of Spark RDD and/or DataFrame as inputs to H2O algorithms
- Use of H2O frames as inputs into MLlib algorithms (will come in handy when we do feature engineering later)
- Transparent execution of Sparkling Water applications on top of Spark (for example, we can run a Sparkling Water application within a Spark stream)
- The H2O user interface to explore Spark data