Dynamic Programming (DP) represents a set of algorithms that can be used to calculate an optimal policy given a perfect model of the environment in the form of an MDP. The fundamental idea of DP, as well as reinforcement learning in general, is the use of state values and actions to look for good policies.
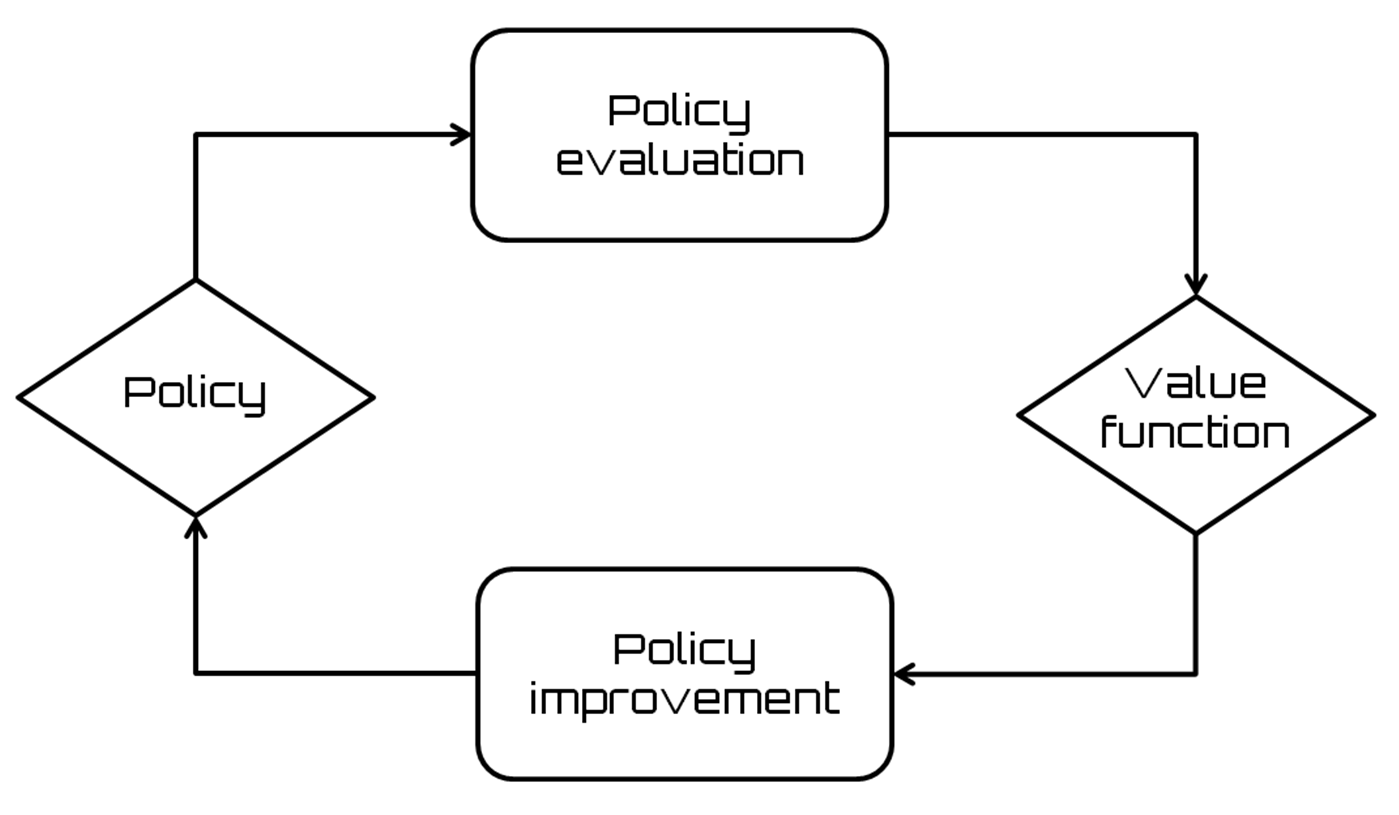
The DP methods approach the resolution of MDP processes through the iteration of two processes called policy evaluation and policy improvement:
- The policy evaluation algorithm consists of applying an iterative method to the resolution of the Bellman equation. Since convergence is guaranteed to us only for k → ∞, we must be content to have good approximations by imposing a stopping condition.
- The policy improvement algorithm improves policy based on current values.
A Bellman equation, named after Richard E. Bellman, an American applied mathematician, is a necessary condition for the optimality associated with the DP method. It allows us to obtain the value of a decision problem at some point in time in terms of payoff from some initial choices and the value of the remaining decision problem resulting from those initial choices.
The iteration of the two aforementioned processes is shown in the following diagram:
A disadvantage of the policy iteration algorithm is that we have to evaluate the policy at every step. This involves an iterative process in which we do not know a priori the time of convergence, which will depend, among other things, on how the starting policy was chosen.
One way to overcome this drawback is to cut off the evaluation of the policy at a specific step. This operation does not change the guarantee of convergence to the optimal value. A special case in which the assessment of the policy is blocked step by step (also called sweep) defines the value iteration algorithm. In the value iteration algorithm, a single iteration of calculation of the values is performed between each step of the policy improvement. In the following snippet, a pseudocode for a value-iteration algorithm is shown:
initialize value function V
repeat
for all s
for all a
update Q function
V = max Q function
until V converge
Thus, in the value iteration algorithm, the system was initiated by setting a random value function. Starting from this value, a new function is sought in an iterative process which, compared to the previous one, has been improved, until reaching the optimal value function.
As we said previously, the DP algorithms are therefore essentially based on two processes that take place in parallel: policy evaluation and policy improvement. The repeated execution of these two processes makes the general process converge toward the optimal solution. In the policy iteration algorithm, the two phases alternate and one ends before the other begins.
In policy iteration algorithms, we start by initializing the system with a random policy, so we first must find the value function of that policy. This phase is called the policy evaluation step. So, we find a new policy, also improved compared to the previous one, based on the previous value function, and so on. In this process, each policy presents an improvement over the previous one until the optimal policy is reached. In the following snippet, a pseudocode for a policy iteration algorithm is shown:
initialize value function V and policy π
repeat
evaluate V using policy π
improve π using V
until convergence
DP methods operate through the entire set of states that can be assumed by the environment, performing a complete backup for each state at each iteration. Each update operation performed by the backup updates the value of a state based on the values of all possible successor states, weighed for their probability of occurrence, induced by the policy of choice and by the dynamics of the environment. Full backups are closely related to the Bellman equation; they are nothing more than the transformation of the equation into assignment instructions.
When a complete backup iteration does not bring any change to the state values, convergence is obtained and, therefore, the final state values fully satisfy the Bellman equation. The DP methods are applicable only if there is a perfect model of the environment, which must be equivalent to an MDP.
Precisely for this reason, the DP algorithms are of little use in reinforcement learning, both for their assumption of a perfect model of the environment, and for the high and expensive computation, but it is still opportune to mention them, because they represent the theoretical basis of reinforcement learning. In fact, all the methods of reinforcement learning try to achieve the same goal as that of the DP methods, only with lower computational cost and without the assumption of a perfect model of the environment.
The DP methods converge to the optimal solution with a number of polynomial operations with respect to the number of states n and actions m, against the number of exponential operations m*n required by methods based on direct search.
The DP methods update the estimates of the values of the states, based on the estimates of the values of the successor states, or update the estimates on the basis of past estimates. This represents a special property, which is called bootstrapping. Several methods of reinforcement learning perform bootstrapping, even methods that do not require a perfect model of the environment, as required by the DP methods.