






















































We begin with the data range descriptive statistic. This will be the easiest descriptive statistic that we cover in this chapter. This is basically grabbing the maximum and minimum of a range of values. So, in this section, we're going to be taking a look at using the maximum and minimum functions in order to find the range of a dataset, and we're going to be combining those functions into a single function that returns a tuple of values. And finally, we're going to compute the range of our away-team runs using the function that we prototyped previously.
Let's go to our Haskell notebook in the Jupyter environment. In the last section, we pulled a listing of all the away-team scores for each game in the 2015 season of Major League Baseball. If you're rejoining this section after a break, you may have to find the Kernel and Restart & Run All feature inside the Notebook system:
Now we get a warning message, saying that this will clear all of our variables, but that's okay because all of the variables are going to be rebuilt by the notebook.
The last thing we did was pass in index 9 to get the away scores. Now, let's store this in a variable called awayRuns:

In order to find the range of this dataset, we're going to utilize two functions, maximum awayRuns and minimum awayRuns:
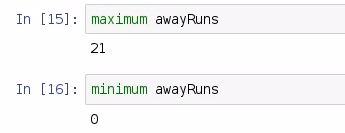
We see that the maximum number of runs scored by any away team in the 2015 season was 21, and we see that the minimum was 0. Let's take a moment to examine the type signatures of the maximum and minimum functions:

They both take a list of values and return a single value, and the values are bound by the Ord type. With that knowledge, we're going to create a function, called range, that takes a value and returns a tuple of values bound by the Ord type. Let's go. Our quick function should probably look like this:

So, we've called this a range, and we have bound our values by the Ord type. We have also accepted a range of values, and returned our tuple of values. And then, we entered range xs, which will extend from minimum xs to maximum xs. Now, let's test this function.
Testing range awayRuns, we see that we get a range of 0 to 21:
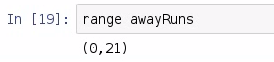
Now, what if we pass an empty list, or what if we just passed a list of one value? These are some things that we didn't consider in this function that I just wrote, so let's explore that briefly:

We see that we get an error message—Prelude.minimum: empty list—and that's because our data was passed to the minimum function. It saw that we had an empty list and it threw an error. What we really ought to do is to package our return in a Maybe so that we could potentially return nothing, and adjust this for cases where we have empty list:
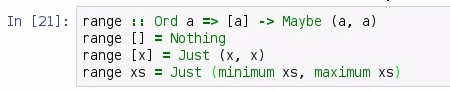
The preceding screenshot shows our improved range function. We use a little bit of pattern matching in order to adjust to some of the conditions that we should be looking for in a proper range function. So, we still have a list of values that are bound by the Ord type, but now, we are packaging our return inside of a Maybe. That way, we can adjust the circumstances in which an empty list is passed, such as by returning nothing. If we have a single value, we can just return that value twice, and not even have to worry with the minimum and maximum. But if we get anything else, we can utilize our minimum and maximum functions. This means that we can produce the range of an empty list (range []), range [1], and our full range awayRuns:

Great. So, this improved function is going to be our prototype for the remaining descriptive statistics in this book. We're going to be adjusting accordingly based on the inputs given, and returning Nothing in cases where no results should be given. In the next section, we're going to be discussing how to compute the mean of a dataset.




