






















































Mastering HTTP
Now that we have a better understanding of the HTTP concept, let’s take a look at the different parts of HTTP that we need to understand in order to build a web application.
We have already seen the request and response, but let’s take a deeper look at the different parts that compose the request and the response (headers, payloads, versions, and methods).
HTTP headers
Each request and response has a set of headers. These are key-value pairs and provide additional information about the request or the response.
While both the request and response headers may look similar, they are not the same, although they do share common key-value pairs.
Request headers
We will start by analyzing in Figure 9.6 what is included in the request header:

Figure 9.6 – Attributions and copyright licensing by Mozilla Contributors is licensed under CC-BY-SA 2.5
Let’s group the different header properties:
- Representation headers:
content-typeandcontent-length - General headers:
keep-aliveandupgrade-insecure-requests - Request headers:
accept,accept-encoding,accept-language,host, anduser-agent
Just by looking at the headers, we can understand many things about a request, such as the type of content the client is expecting, the language, and the browser used. The server can use this information to provide a better response to the client.
Important info
This is just a small list of the possible headers. There are many more headers that we can use to provide more information about the request or response. We can even create our own key-value pairs. You can find the list of the HTTP headers here: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers.
Response headers
We will finish by analyzing in the Figure 9.7 what is included in the response header
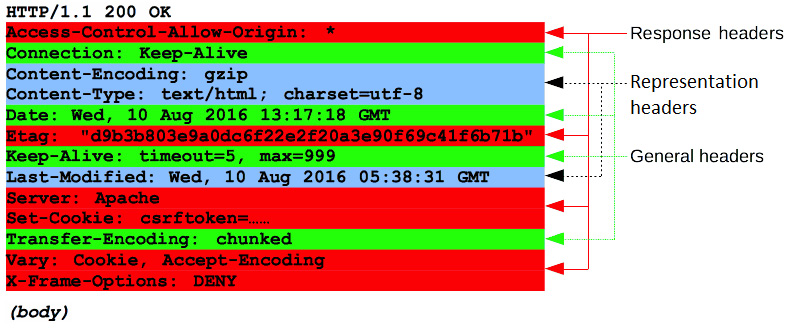
Figure 9.7 – Attributions and copyright licensing by Mozilla Contributors is licensed under CC-BY-SA 2.5
The response headers are very similar to the request headers, but they are not the same. They can be grouped as follows:
- Representation headers:
content-type,content-encoding, andlast-modified - General headers:
connection,date,keep-alive, andtransfer-encoding - Response headers:
access-control-allow-origin,etag,server,set-cookie,vary, andx-frame-options
With the response headers, we can also provide additional information that will help the browsers and the web applications to digest and render the information properly.
The response headers are very important for the security of the application, as there are many headers that can prevent certain attacks in the web browser environment. For example, we can use x-frame-options to prevent the application from being loaded in an iframe, or use feature-policy to prevent the application from using features such as the camera or microphone. We will explore this in Chapter 15.
Status codes
Overall, one of the most important pieces of information that we can find in the response is the status code.
The status code allows us to understand whether the request was successful or not and can even provide more granular feedback. We can classify status codes into the following groups:
- 1xx: Informational
- 2xx: Success
- 3xx: Redirection
- 4xx: Client Error
- 5xx: Server Error
The most common status codes are 200 OK, 201 Created, 301 Moved Permanently, 400 Bad Request, 401 Unauthorized, 403 Forbidden, 404 Not Found, 429 Too Many Requests, 500 Internal Server Error, and 503 Service Unavailable. You can find the complete list of the status codes here: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status.
As you can see, if you know the given status code, you can understand what happened with your request. For example, a 429 error code occurs when the client has sent too many requests in a given amount of time (“rate limiting”), but if you receive a 401 then the error is related to your authentication. Finally, if in the same scenario you receive 403, you are correctly authenticated but you don’t have enough permission to perform the given operation, such as deleting another user account.
We all have experienced the 404 error code, which is very common when we try to access a resource that doesn’t exist. For example, if we try to access the following URL, https://www.google.com/invented-resource, we will receive a 404 error code.
418 I’m a teapot
There is a strong culture on the internet to build fancy 404 pages. You can find a lot of examples online, but not many people know that there is a special error code 418 that RFC 2324 (https://tools.ietf.org/html/rfc2324) describes as follows:
“Any attempt to brew coffee with a teapot should result in the error code “418 I’m a teapot”. The resulting entity body MAY be short and stout.”
While this might seem just like a running joke, it is actually supported by many entities including Node (https://github.com/nodejs/node/issues/14644) and Google.
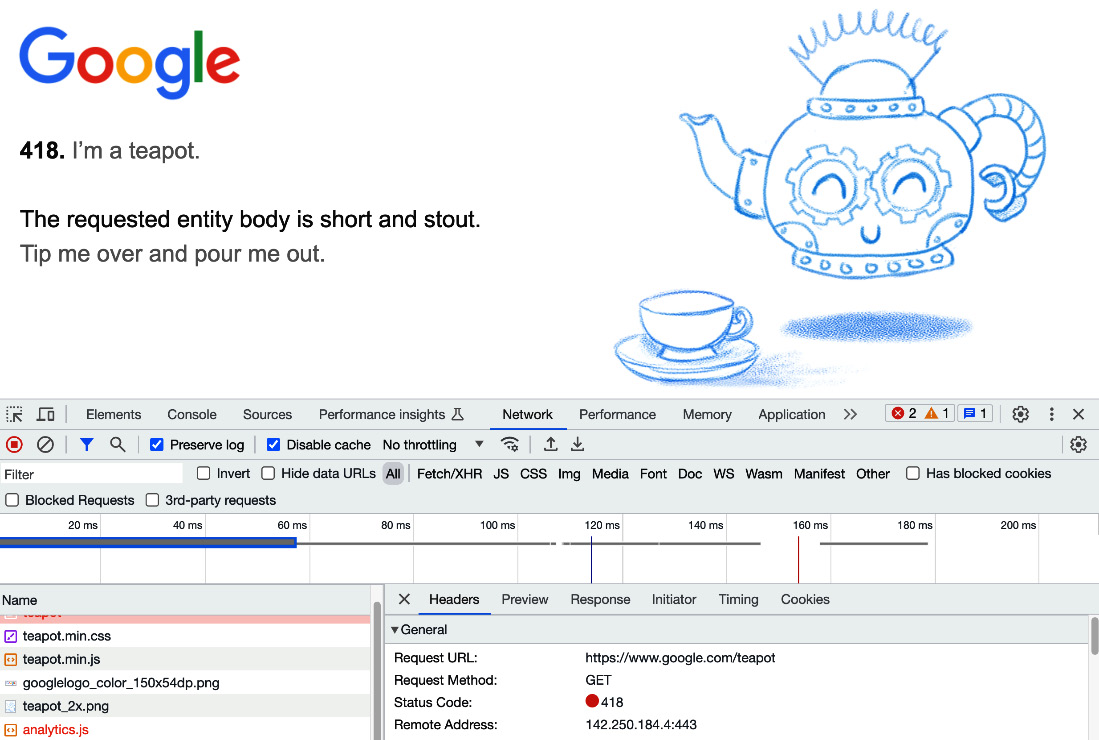
Figure 9.8 – Web browser screenshot of google.com/teapot
As Shane Brunswick said on the Save 418 Movement website (https://save418.com/):
And I do agree with him: behind these complex systems there are humans, and we should not forget that, in the same way that we should not forget that the internet could not exist without the open source movement and the hacker culture.
Request methods
Just as status codes are very important to understand responses, the request methods are essential to understand requests.
There are many request methods, but the most common are the following: GET, POST, PUT, PATCH, and DELETE. You can find the complete list of the request methods here: https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods.
The way that we backend developers use them can differ a bit, but the most common way is the following:
GET: Retrieve a resourcePOST: Create a resourcePUT: Update a resourcePATCH: Partially update a resourceDELETE: Delete a resource
We will explore them in detail in Chapter 11, when we create an actual REST API with all the endpoints.
In the early days of the internet, we used forms to send data to the server and specified the given method in the form. See the following, for example:
<form action="/user" method="POST"> <input type="text" name="username" /> <input type="password" name="password" /> <input type="submit" value="Submit" /> </form>
The preceding code was a common way to send data to a server in order to create a new user, but nowadays we use JavaScript to send data to the server. For example, we can use the fetch API to send data to the server as follows:
fetch('/user', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
username: 'john',
password: '1234'
})
}) And then we would use the response to inform the user whether the request was successful or not. While using JavaScript to send data to the server is more complex, it gives us more flexibility and control over the request.
Important note
When you enter a URL in the browser, the browser sends a GET request to the server. This is the default method that the browser uses. You have been using HTTP methods for a long time without knowing it.
HTTP payloads
HTTP messages can carry a payload, which means that we can send data to the server, and servers likewise can send data to their clients. This is often done with POST requests.
Payloads can be in many formats, but the most common are the following:
application/json: Used when sharing JSON dataapplication/x-www-form-urlencoded: Used when sending simple texts in ASCII, sending data in the URLmultipart/form-data: Used when sending binary data (such as files) or non-ASCII textstext/plain: Used when sending plain text, such as a log file- You can find the complete list of the content types here: https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types.
HTTP versions
HTTP has evolved over the years, and we have different versions of the protocol:
|
Version |
Year |
Status |
|
|
1991 |
Obsolete |
|
|
1996 |
Obsolete |
|
|
1997 |
Standard |
|
|
2015 |
Standard |
|
|
2022 |
Standard |
Currently, the most used version of the protocol is the HTTP/1.1 version, but the HTTP/2 version is gaining popularity. The HTTP/3 version is quite new and not widely supported yet.
Nowadays, Node supports the HTTP/1.1 and HTTP/2 versions, but it doesn’t support the HTTP/3 version yet. There is an ongoing strategic initiative to support it: https://github.com/nodejs/node/issues/38478.
In the next section, we will learn how important Uniform Resource Locators (URLs) are and how we can use them to structure access to resources in our web applications.



