Virtualization is an enterprise for the architecture of most workloads and services in modern data centers. Virtualization brings a lot of benefits to computing, such as the improved capability to both horizontal and vertical scaling, to be able to add layers of host redundancy to support highly available solutions.
However, virtualization also introduces potential pitfalls, such as overcommitting hardware resources.
SharePoint Server is fully supported on virtualized platforms, as well as on traditional bare-metal platforms. Virtualization adds a layer of abstraction to the entire process, potentially making it more difficult to understand all of the components affecting your environment's performance.
The areas that we'll look at include the following:
- Core requirements
- Server infrastructure
- Processors
- Server roles
- Storage
- Network
- Database
Let's review each of these areas in the coming sections.
Core requirements
SharePoint Server 2019 has the following minimum hardware requirements:
|
Installation Scenario
|
Memory
|
Processor
|
Hard Disk Space
|
|
Dedicated Role Server
|
16 GB
|
64-bit, 4 cores
|
80 GB for system drive
80 GB for each additional drive
|
When planning for a highly performant, highly available server deployment, it is recommended that you choose a MinRole topology with dedicated server roles and redundant components. Current information on the SharePoint Server requirements can be found on the requirements page at https://docs.microsoft.com/en-us/sharepoint/install/hardware-and-software-requirements-2019.
Server infrastructure
As previously stated, most modern data centers utilize a high amount of virtualization. Virtualization, in and of itself, is a mechanism that allows a server (or host) to run more than one instance of a particular type of software (whether it's a full operating system running as a virtual machine, such as Windows Server 2019, or a container system, such as Docker, running applications).
In either of these cases, virtualization requires some overhead to allow the virtualization software to coordinate resources for the virtual machines or containers. This overhead subtracts from the overall amount of CPU cycles available to a service application and user requests.
With that being said, most SharePoint deployments will utilize virtual machines for some or all of the functions. Many organizations still choose to run database servers (due to their high transaction rates) in a more traditional fashion. If your organization chooses a virtualization strategy to support a SharePoint system, you will need to plan accordingly to ensure that the virtual infrastructure provided can meet the performance and user experience requirements of your organization.
Processors
Processors perform the computational tasks necessary to render content and applications. Per the minimum requirements, Microsoft recommends (four) 64-bit processor cores for a SharePoint Server instance. Task and context switching has a high degree of impact on overall performance. If your organization chooses to use virtualization, be careful to not oversubscribe or overcommit the number of processing resources presented to virtual machines.
Server roles
In the Selecting and configuring a Farm topology section of this chapter, we discussed the different roles available, particularly Dedicated versus Shared.
Shared roles, by their nature, take up more system resources than dedicated roles. Shared roles also introduce the potential for more task switching (time that the computer spends switching between threads to process transactions). For the highest-performing farm, it is recommended that each server performs only one role or function in a SharePoint farm. SharePoint services can be scaled both horizontally and vertically to accommodate multiple performance scenarios.
Storage
Storage (as a physical resource) is arguably one of the most important parts of a high-performance solution. Nearly all content and data stored or accessed inside a SharePoint environment is stored in some sort of database, which in turn rests on physical storage media. Storage is important to a SharePoint environment in two ways: the amount of data volume (capacity) and the speed at which data can be stored or retrieved.
When determining storage requirements for a high-performance system, there are a number of items to consider:
- The number of transactions (such as uploading, downloading, viewing, and so on), each of which generates I/O activity and is measured in I/O Operations Per Second (IOPS)
- The number of documents or other artifacts stored (and their associated metadata)
- The amount of data volume, including versioning
The general rule of thumb is to plan for I/O requirements first. A system's storage performance is generally governed by how many individual disks can be tasked at a particular time to act on data.
An individual disk's IOPS can be calculated using the following formula:
1000/(average disk latency + average disk seek time)
For example, a high-end 15,000 RPM mechanical drive with a seek time of 2.5 ms and a latency of 1.7 ms results in an IOPS value of 238. Typical mechanical hard drives deliver an IOPS ranging from 55 to 250, while SSD drive performance delivers 3,000–40,000 IOPS per disk.
Utilizing the principles you learned earlier for fault-tolerant design, you need to make sure that you design your storage in a way that can withstand the failure of one or more disk components. Disk subsystems typically achieve redundancy and performance using a mixture of technologies and configurations:
- RAID
- Multipathing
- Disk configurations
- Database capacity
Let's examine how each of these affects the storage infrastructure.
RAID
A RAID solution is a storage architecture that combines various aspects of performance, fault tolerance, and storage management. It is a form of storage virtualization, combining all or parts of physical disks to present a contiguous, logical allocation of storage to a host.
A group of disks operating in a RAID configuration is known as a RAID set. RAID subsystems work by saving data in either a striped (split into chunks and distributed) or mirrored (duplicated) fashion to the disks in the RAID set. Different combinations of striping and mirroring are referred to as RAID levels.
Additionally, RAID sets can include a feature called parity, which is a mathematical computation performed on data as a sort of error checking mechanism. In the event of disk failure, parity can be used to recover or rebuild the data on the inoperable disk. A RAID set is set to be in a degraded state when one or more disks in the set have failed but the volume as a whole is able to continue servicing requests.
To a large extent, a particular RAID set's performance depends not only on the RAID level but also on the read/write ratio. The read performance of a RAID set can be calculated using the formula. Each level has its own set of performance and redundancy characteristics, the most common of which are displayed in the following list:
- RAID 0: A RAID 0 configuration offers no fault-tolerance benefit. Data is striped between two or more disks evenly. In the event that any single disk in a RAID 0 set fails, all of the data is lost. RAID 0 provides a high level of overall read and write performance since it can engage multiple disks simultaneously to store and retrieve data. RAID 0 also provides the most possible storage, since there is no capacity overhead used to provide redundancy:
A RAID 0 set's performance can be expressed by simply multiplying the number of IOPS per disk and the number of disks—for example, a four-disk RAID 0 set with disks that can each perform 125 IOPS results in a max throughput of 1,000 IOPS.
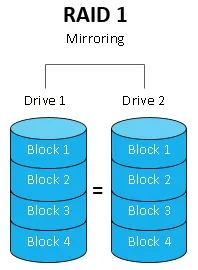
- RAID 1: RAID 1 is the exact opposite of RAID 0. While RAID 0 has no fault tolerance whatsoever, RAID 1 can sustain the failures of up to half of the disks in a set. RAID 1 is commonly known as drive mirroring because incoming data is simultaneously written to two (or more) disks. RAID 1 only works with even numbers of disks. A two-disk RAID 1 set has a 50% capacity overhead as each disk has a full copy of all of the data. A two-disk RAID 1 set also has a 50% performance reduction on write activities since the data must be written twice. This configuration is commonly used for operating system drives:
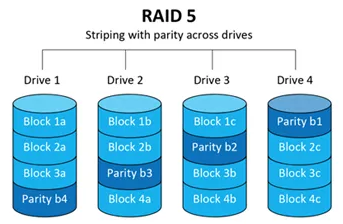
- RAID 5: A RAID 5 set utilizes disk striping (dividing a piece of data into multiple blocks and spreading those blocks among multiple drives) as well as parity (an error-checking calculation that is stored as a block on a drive). Effectively speaking, one drive of a RAID set is dedicated to storing parity calculations. RAID 5 requires a minimum of three drives to implement (which means a 33% storage capacity overhead). The most common configuration utilizes four drives, resulting in a 25% storage capacity overhead. RAID 5 volumes have very fast read times as multiple disks are being engaged. However, they do have a bit of performance overhead when both computing parity for writing as well as computing parity on the fly when the set is in a degraded state. This configuration is commonly used for file shares or database volumes with low to medium activity:
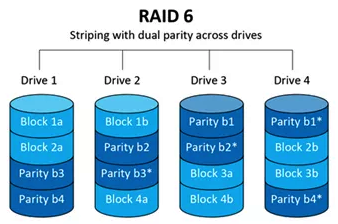
- RAID 6: Building on the parity concept of RAID 5, RAID 6 introduces an additional parity bit to allow a drive array to sustain failures on two drives. This increased parity leads to both a reduction in storage capacity as well as increased performance overhead since parity is computed and written twice. RAID 6 volumes require a minimum of four disks to implement. This configuration is commonly used for file shares or database volumes with low to medium activity:
- RAID 10: RAID 10 is a combination of the capabilities of both RAID 1's mirroring and RAID 0's striping. It's commonly configured with four disks. RAID 10 has excellent read performance, as well as a 50% write performance penalty. RAID 10's total capacity is 50% of the disk capacity, but it can recover from up to two failed disks. This configuration provides both the highest performance and highest recoverability, but it also incurs the highest unusable amount of unusable storage—effectively, half the disks in the array. RAID 10, from a performance and resilience perspective, is typically the best choice for high-volume databases:
As you can see from the preceding diagrams and explanations, a RAID 10 disk subsystem is likely the best choice for high-performance SharePoint farms. Microsoft recommends the use of RAID 10 for SharePoint and SQL server configurations.
Multipathing
From a storage connectivity standpoint, multipathing allows a computer to connect to external storage through more than one route. Multipathing is typically configured when connecting to Storage Area Networks (SANs) via iSCSI or fiber storage networking. Configuring multipathing requires either multiple single-port storage adapters or a single multi-port storage adapter and a multipathing software package.
If your SharePoint farm or SQL database server environment uses physical servers (as opposed to virtualized servers), multipathing is an excellent way to provide both storage redundancy and storage performance.
Disk configurations
If you are using virtual machines in your SharePoint environment, you should evaluate the way you attach them to physical storage, including the following:
- Disk connection methods
- Fixed versus dynamic or thin-provisioned volumes
When you connect or attach disks to a virtual machine and begin configuring it, you generally have three options: exposing raw disk storage (in Hyper-V, this is referred to as a pass-through disk) to the virtual machine, connecting to raw disk using iSCSI or using Network Attached Storage (NAS)), or provisioning a VHD/VHDX file on a storage array and attaching that to the virtual machine configuration.
In earlier versions of Hyper-V, pass-through disks were generally considered the fastest method because there were fewer layers between the virtual machine and the disk access. Modern Hyper-V boasts a negligible difference, so it is probably best not to use them as they could present challenges to high availability or snapshots. You may want to test the performance between direct attach storage methods (such as iSCSI) to see whether they yield any performance gain.
If you decided to provision standard VHD/VHDX virtual hard drive files, it's important to provision them as fixed disks (where the entire volume of the virtual disk is pre-allocated) as opposed to using dynamically expanding disks (sometimes referred to as thin provisioning). Using thin provisioning or dynamically expanding disks greatly reduces the performance of a disk's volume since the storage is no longer contiguous. Disks serving the I/O requests will likely have to travel more to read or write data, introducing latency into the equation.
Database capacity
Part of the storage planning calculation is knowing (or estimating) how much data is stored. When calculating capacity needs, the following formula can be used:
Content database size = ((D × V) × S) + (10 KB × (L + ( V × D)))
Here, we have the following:
- D is the number of documents to be stored, including any growth (most organizations tend to estimate growth over a period of 3 or 5 years). For computing departmental or project sites, you may want to use a number such as 10 or 20 documents per user; for My Sites, you may want to use a larger number (such as 500 or 1,000 per person).
- V is the number of versions that are stored (must be non-zero).
- S represents the average size of a document. Depending on the sites that will be stored in a particular content database, it may be useful to re-estimate this value for each content database (for example, My Sites will likely have a different usage profile than a departmental or project site).
- L is the estimated number of list items per site. If you have no pre-existing estimates, Microsoft recommends using a value of three times the amount of D.
- 10 KB represents the amount of storage volume consumed by metadata. If you plan on deploying a very metadata-driven environment, you may wish to adjust this number.
By applying the preceding formula to the following values, you can calculate the amount of storage capacity that a particular content database might be projected to need:
|
Variable
|
Value
|
|
Number of documents (D)
|
500,000
|
|
Number of versions per document (V)
|
5
|
|
Number of list items (L)
|
1,500,000
|
|
Average size per document
|
50 KB
|
The calculation is as follows:
Content database size = (((500,000 x 5)) x 50) + ((10KB * (1,500,000 + (500,000 x 5))), or 165 GB of total storage.
Network
In order to produce a high-performance farm, you also need to ensure that the network connectivity between servers is optimal. Generally speaking, you should adhere to these guidelines:
- All servers should have a Local Area Network (LAN) bandwidth and latency to SQL servers used in the SharePoint farm. The latency should be 1 ms or less.
- Microsoft does not recommend connecting to a SQL environment over a Wide Area Network (WAN).
- If configuring a site-redundant solution with SQL AlwaysOn located in a remote data center, you should ensure that you have adequate WAN bandwidth to perform the necessary log shipping or mirroring activities.
- Web and application servers should be configured with multiple network adapters to support user traffic, SQL traffic, and backup traffic.
- If connecting to iSCSI storage, ensure that any iSCSI network adapters are configured to only be used for iSCSI communication and not normal network communication.
These recommendations will help you build a farm that is both resilient and high-performing.

 United States
United States
 Great Britain
Great Britain
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Singapore
Singapore
 Hungary
Hungary
 Ukraine
Ukraine
 Luxembourg
Luxembourg
 Estonia
Estonia
 Lithuania
Lithuania
 South Korea
South Korea
 Turkey
Turkey
 Switzerland
Switzerland
 Colombia
Colombia
 Taiwan
Taiwan
 Chile
Chile
 Norway
Norway
 Ecuador
Ecuador
 Indonesia
Indonesia
 New Zealand
New Zealand
 Cyprus
Cyprus
 Denmark
Denmark
 Finland
Finland
 Poland
Poland
 Malta
Malta
 Czechia
Czechia
 Austria
Austria
 Sweden
Sweden
 Italy
Italy
 Egypt
Egypt
 Belgium
Belgium
 Portugal
Portugal
 Slovenia
Slovenia
 Ireland
Ireland
 Romania
Romania
 Greece
Greece
 Argentina
Argentina
 Netherlands
Netherlands
 Bulgaria
Bulgaria
 Latvia
Latvia
 South Africa
South Africa
 Malaysia
Malaysia
 Japan
Japan
 Slovakia
Slovakia
 Philippines
Philippines
 Mexico
Mexico
 Thailand
Thailand



















