






















































Data Cleaning
Data cleaning includes processes such as filling in missing values and handling inconsistencies. It detects corrupt data and replaces or modifies it.
Missing Values
The concept of missing values is important to understand if you want to master the skill of successful management and understanding of data. Let's take a look at the following figure:
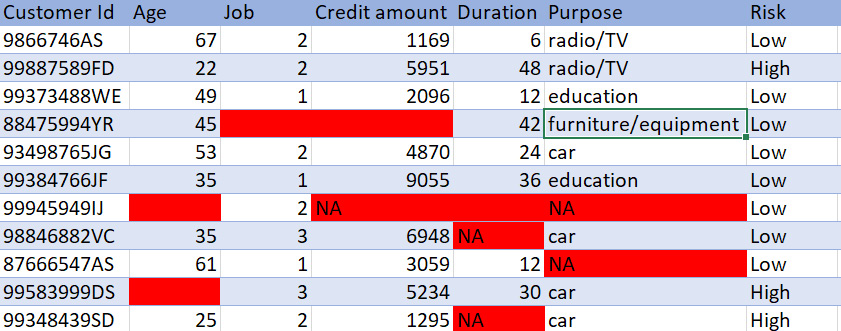
Figure 1.14: Bank customer credit data
As you can see, the data belongs to a bank; each row is a separate customer and each column contains their details, such as age and credit amount. There are some cells that have either NA or are just empty. This is missing data. Each piece of information about the customer is crucial for the bank. If any of the information is missing, then it will be difficult for the bank to predict the risk of providing a loan to the customer.
Handling Missing Data
Intelligent handling of missing data will result in building a robust model capable of handling complex tasks. There are many ways to handle missing data. Let's now look at some of those ways.
Removing the Data
Checking missing values is the first and the most important step in data pre-processing. A model cannot accept data with missing values. This is a very simple and commonly used method to handle missing values: we delete a row if the missing value corresponds to the places in the row, or we delete a column if it has more than 70%-75% of missing data. Again, the threshold value is not fixed and depends on how much you wish to fix.
The benefit of this approach is that it is quick and easy to do, and in many cases no data is better than bad data. The drawback is that you may end up losing important information, because you're deleting a whole feature based on a few missing values.
Exercise 2: Removing Missing Data
In this exercise, we will be loading the Banking_Marketing.csv dataset into the pandas DataFrame and handling the missing data. This dataset is related to direct marketing campaigns of a Portuguese banking institution. The marketing campaigns involved phone calls to clients to try and get them to subscribe to a particular product. The dataset contains the details of each client contacted, and whether they subscribed to the product. Follow these steps to complete this exercise:
Note
The Banking_Marketing.csv dataset can be found at this location: https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/Banking_Marketing.csv.
- Open a Jupyter notebook. Insert a new cell and add the following code to import pandas and fetch the Banking_Marketing.csv dataset:
import pandas as pd
dataset = 'https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/Banking_Marketing.csv'
#reading the data into the dataframe into the object data
df = pd.read_csv(dataset, header=0)
- Once you have fetched the dataset, print the datatype of each column. To do so, use the dtypes attribute from the pandas DataFrame:
df.dtypes
The preceding code generates the following output:

Figure 1.15: Data types of each feature
- Now we need to find the missing values for each column. In order to do that, we use the isna() function provided by pandas:
df.isna().sum()
The preceding code generates the following output:
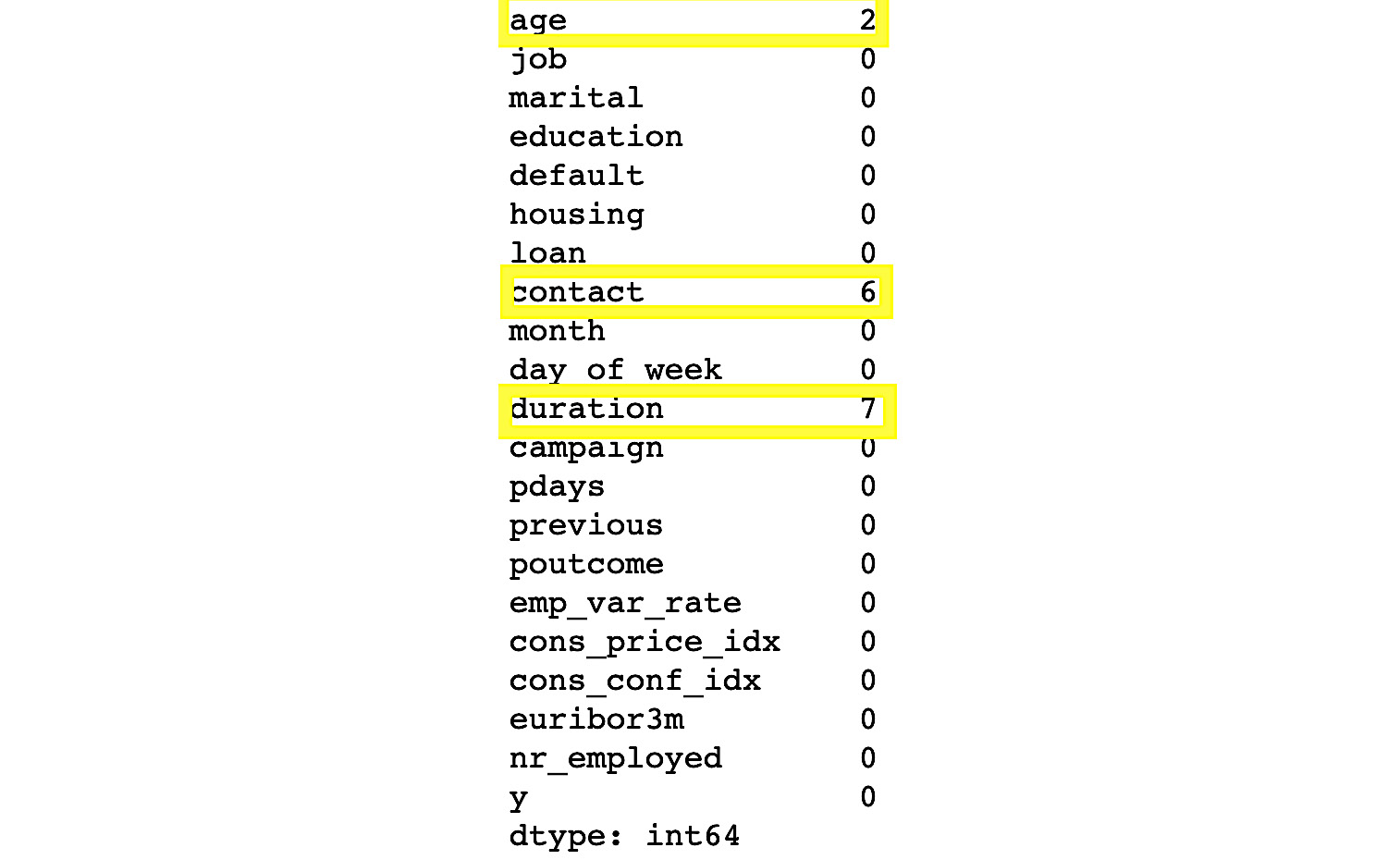
Figure 1.16: Missing values of each column in the dataset
In the preceding figure, we can see that there is data missing from three columns, namely age, contact, and duration. There are two NAs in the age column, six NAs in contact, and seven NAs in duration.
- Once you have figured out all the missing details, we remove all the missing rows from the DataFrame. To do so, we use the dropna() function:
#removing Null values
data = data.dropna()
- To check whether the missing vales are still present, use the isna() function:
df.isna().sum()
The preceding code generates the following output:

Figure 1.17: Each column of the dataset with zero missing values
You have successfully removed all missing data from the DataFrame. In the next section, we'll look at the second method of dealing with missing data, which uses imputation.
Mean/Median/Mode Imputation
In the case of numerical data, we can compute its mean or median and use the result to replace missing values. In the case of the categorical (non-numerical) data, we can compute its mode to replace the missing value. This is known as imputation.
The benefit of using imputation, rather than just removing data, is that it prevents data loss. The drawback is that you don't know how accurate using the mean, median, or mode is going to be in a given situation.
Let's look at an exercise in which we will use imputation method to solve missing data problems.
Exercise 3: Imputing Missing Data
In this exercise, we will be loading the Banking_Marketing.csv dataset into the pandas DataFrame and handle the missing data. We'll make use of the imputation method. Follow these steps to complete this exercise:
Note
The Banking_Marketing.csv dataset can be found at this location: https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/Banking_Marketing.csv.
- Open a Jupyter notebook and add a new cell. Load the dataset into the pandas DataFrame. Add the following code to do this:
import pandas as pd
dataset = 'https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/Banking_Marketing.csv'
df = pd.read_csv(dataset, header=0)
- Impute the numerical data of the age column with its mean. To do so, first find the mean of the age column using the mean() function of pandas, and then print it:
mean_age = df.age.mean()
print(mean_age)
The preceding code generates the following output:
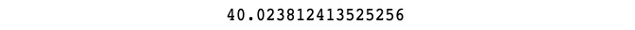
Figure 1.18: Mean of the age column
- Once this is done, impute the missing data with its mean using the fillna() function. This can be done with the following code:
df.age.fillna(mean_age, inplace=True)
- Now we impute the numerical data of the duration column with its median. To do so, first find the median of the duration column using the median() function of the pandas. Add the following code to do so:
median_duration = df.duration.median()
print(median_duration)
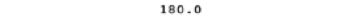
Figure 1.19: Median of the duration
- Impute the missing data of the duration with its median using the fillna() function.
df. duration.fillna(median_duration,inplace=True)
- Impute the categorical data of the contact column with its mode. To do so, first, find the mode of the contact column using the mode() function of pandas. Add the following code to do this:
mode_contact = df.contact.mode()[0]
print(mode_contact)
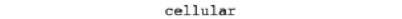
Figure 1.20: Mode of the contact
- Impute the missing data of the contact column with its mode using the fillna() function. Add the following code to do this:
df.contact.fillna(mode_contact,inplace=True)
Unlike mean and median, there may be more than one mode in a column. So, we just take the first mode with index 0.
You have successfully imputed the missing data in different ways and made the data complete and clean.
Another part of data cleaning is dealing with outliers, which will be discussed in the next section.
Outliers
Outliers are values that are very large or very small with respect to the distribution of the other data. We can only find outliers in numerical data. Box plots are one good way to find the outliers in a dataset, as you can see in the following figure:
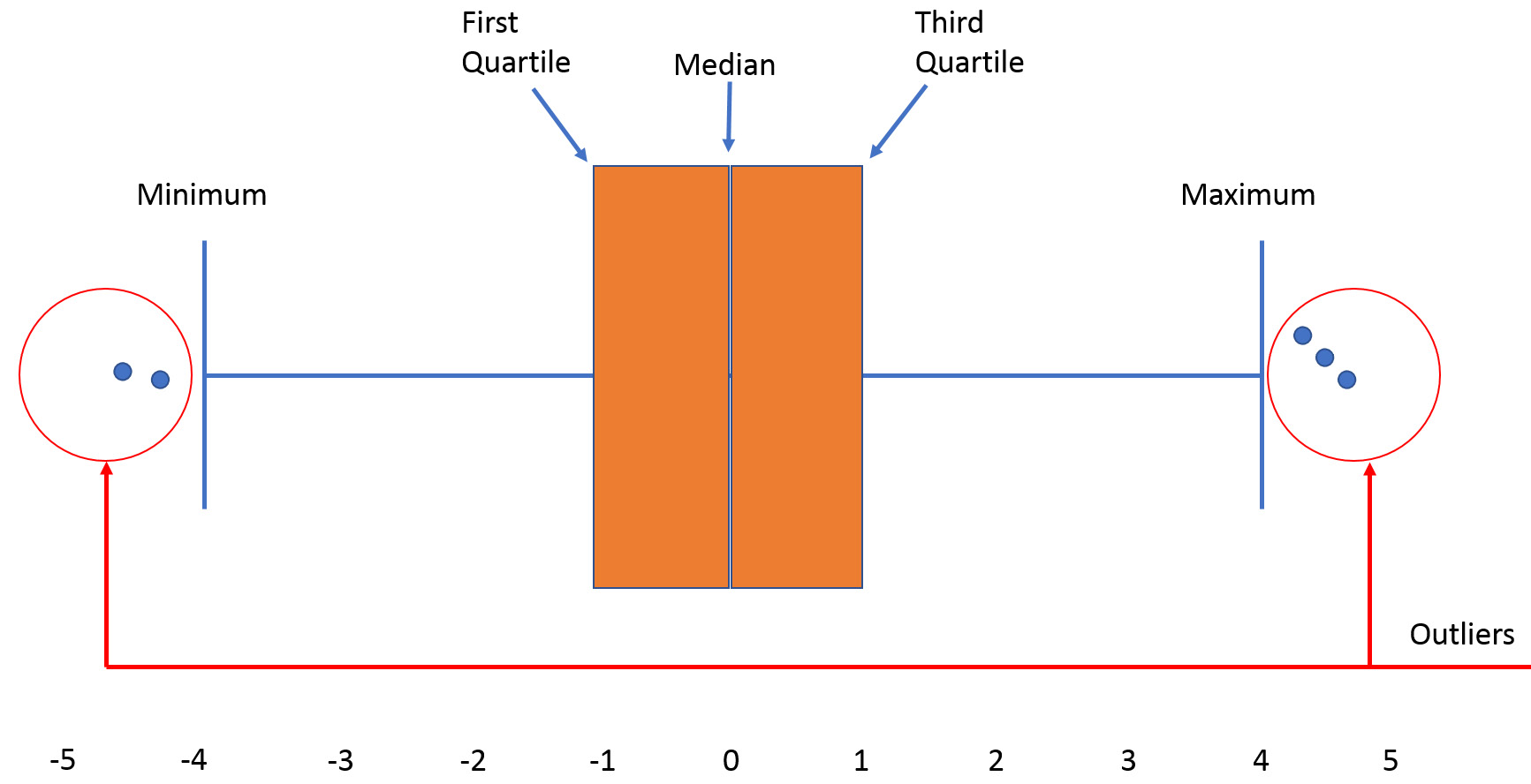
Figure 1.21: Sample of outliers in a box plot
Note
An outlier is not always bad data! With the help of business understanding and client interaction, you can discern whether to remove or retain the outlier.
Let's learn how to find outliers using a simple example. Consider a sample dataset of temperatures from a place at different times:
71, 70, 90, 70, 70, 60, 70, 72, 72, 320, 71, 69
We can now do the following:
- First, we'll sort the data:
60,69, 70, 70, 70, 70, 71, 71, 72, 72, 90, 320
- Next, we'll calculate the median (Q2). The median is the middle data after sorting.
Here, the middle terms are 70 and 71 after sorting the list.
The median is (70 + 71) / 2 = 70.5
- Then we'll calculate the lower quartile (Q1). Q1 is the middle value (median) of the first half of the dataset.
First half of the data = 60, 69, 70, 70, 70, 70
Points 3 and 4 of the bottom 6 are both equal to 70.
The average is (70 + 70) / 2 = 70
Q1 = 70
- Then we calculate the upper quartile (Q3).
Q3 is the middle value (median) of the second half of the dataset.
Second half of the data = 71, 71, 72, 72, 90, 320
Points 3 and 4 of the upper 6 are 72 and 72.
The average is (72 + 72) / 2 = 72
Q3 = 72
- Then we find the interquartile range (IQR).
IQR = Q3 – Q1 = 72 – 70
IQR = 2
- Next, we find the upper and lower fences.
Lower fence = Q1 – 1.5 (IQR) = 70 – 1.5(2) = 67
Upper fence = Q3 + 1.5 (IQR) = 71.5 + 1.5(2) = 74.5
Boundaries of our fences = 67 and 74.5
Any data points lower than the lower fence and greater than the upper fence are outliers. Thus, the outliers from our example are 60, 90 and 320.
Exercise 4: Finding and Removing Outliers in Data
In this exercise, we will be loading the german_credit_data.csv dataset into the pandas DataFrame and removing the outliers. The dataset contains 1,000 entries with 20 categorial/symbolic attributes prepared by Prof. Hofmann. In this dataset, each entry represents a person who takes credit from a bank. Each person is classified as a good or bad credit risk according to the set of attributes. Follow these steps to complete this exercise:
Note
The link to the german_credit_data.csv dataset can be found here: https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/german_credit_data.csv.
- Open a Jupyter notebook and add a new cell. Write the following code to import the necessary libraries: pandas, NumPy, matplotlib, and seaborn. Fetch the dataset and load it into the pandas DataFrame. Add the following code to do this:
import pandas as pd
import numpy as np
%matplotlib inline
import seaborn as sbn
dataset = 'https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/german_credit_data.csv'
#reading the data into the dataframe into the object data
df = pd.read_csv(dataset, header=0)
In the preceding code, %matplotlib inline is a magic function that is essential if we want the plot to be visible in the notebook.
- This dataset contains an Age column. Let's plot a boxplot of the Age column. To do so, use the boxplot() function from the seaborn library:
sbn.boxplot(df['Age'])
The preceding code generates the following output:
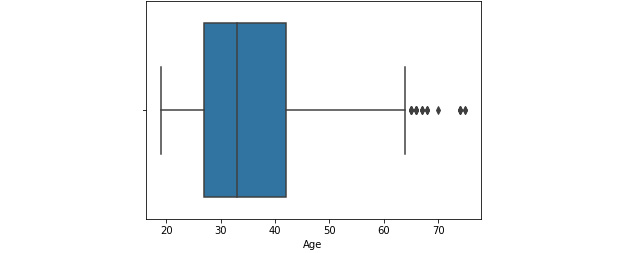
Figure 1.22: A box plot of the Age column
We can see that some data points are outliers in the boxplot.
- The boxplot uses the IQR method to display the data and the outliers (the shape of the data). But in order to print an outlier, we use a mathematical formula to retrieve it. Add the following code to find the outliers of the Age column using the IQR method:
Q1 = df["Age"].quantile(0.25)
Q3 = df["Age"].quantile(0.75)
IQR = Q3 - Q1
print(IQR)
>>> 15.0
In the preceding code, Q1 is the first quartile and Q3 is the third quartile.
- Now we find the upper fence and lower fence by adding the following code, and print all the data above the upper fence and below the lower fence. Add the following code to do this:
Lower_Fence = Q1 - (1.5 * IQR)
Upper_Fence = Q3 + (1.5 * IQR)
print(Lower_Fence)
print(Upper_Fence)
>>> 4.5
>>> 64.5
- To print all the data above the upper fence and below the lower fence, add the following code:
df[((df["Age"] < Lower_Fence) |(df["Age"] > Upper_Fence))]
The preceding code generates the following output:
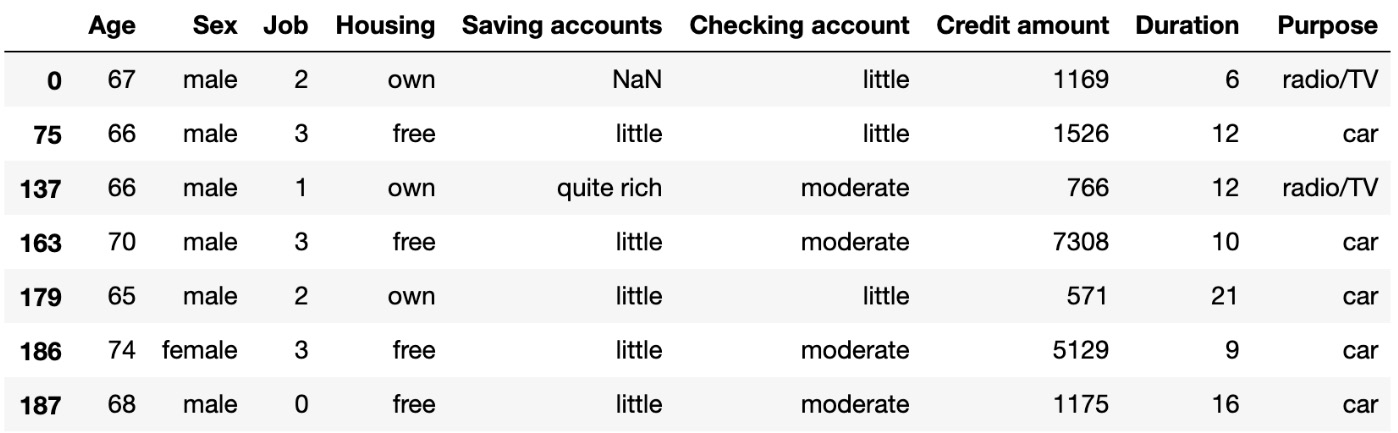
Figure 1.23: Outlier data based on the Age column
- Filter out the outlier data and print only the potential data. To do so, just negate the preceding result using the ~ operator:
df = df[~((df ["Age"] < Lower_Fence) |(df["Age"] > Upper_Fence))]
df
The preceding code generates the following output:
Figure 1.24: Potential data based on the Age column
You have successfully found the outliers using the IQR. In the next section, we will explore another method of pre-processing called data integration.




