






















































Exploring the evolution of data analytics
Data analytics has evolved over time, enabling us to do bigger and better. For many years, the focus of data analytics was limited to descriptive analysis, where the focus was to gain useful business insights from data, in the form of a report. This type of analysis was useful to answer question such as "What happened?". A hypothetical scenario would be that the sales of a company sharply declined within the last quarter.
Very quickly, everyone started to realize that there were several other indicators available for finding out what happened, but it was the why it happened that everyone was after. The core analytics now shifted toward diagnostic analysis, where the focus is to identify anomalies in data to ascertain the reasons for certain outcomes. An example scenario would be that the sales of a company sharply declined in the last quarter because there was a serious drop in inventory levels, arising due to floods in the manufacturing units of the suppliers. This form of analysis further enhances the decision support mechanisms for users, as illustrated in the following diagram:
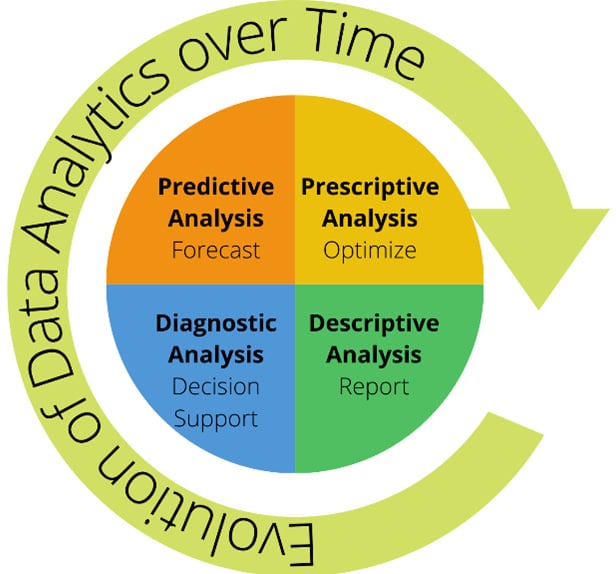
Figure 1.2 – The evolution of data analytics
Important note
Both descriptive analysis and diagnostic analysis try to impact the decision-making process using factual data only.
Since the advent of time, it has always been a core human desire to look beyond the present and try to forecast the future. If we can predict future outcomes, we can surely make a lot of better decisions, and so the era of predictive analysis dawned, where the focus revolves around "What will happen in the future?". Predictive analysis can be performed using machine learning (ML) algorithms—let the machine learn from existing and future data in a repeated fashion so that it can identify a pattern that enables it to predict future trends accurately.
Now that we are well set up to forecast future outcomes, we must use and optimize the outcomes of this predictive analysis. Based on the results of predictive analysis, the aim of prescriptive analysis is to provide a set of prescribed actions that can help meet business goals.
Important note
Unlike descriptive and diagnostic analysis, predictive and prescriptive analysis try to impact the decision-making process, using both factual and statistical data.
But how can the dreams of modern-day analysis be effectively realized? After all, data analysts and data scientists are not adequately skilled to collect, clean, and transform the vast amount of ever-increasing and changing datasets.
The data engineering practice is commonly referred to as the primary support for modern-day data analytics' needs.
The following are some major reasons as to why a strong data engineering practice is becoming an absolutely unignorable necessity for today's businesses:
- Core capabilities of compute and storage resources
- Availability of varying datasets
- The paradigm shift to distributed computing
- Adoption of cloud computing
- Data storytelling
We'll explore each of these in the following subsections.
Important note
Having a strong data engineering practice ensures the needs of modern analytics are met in terms of durability, performance, and scalability.
Core capabilities of storage and compute resources
25 years ago, I had an opportunity to buy a Sun Solaris server—128 megabytes (MB) random-access memory (RAM), 2 gigabytes (GB) storage—for close to $ 25K. The intended use of the server was to run a client/server application over an Oracle database in production. Given the high price of storage and compute resources, I had to enforce strict countermeasures to appropriately balance the demands of online transaction processing (OLTP) and online analytical processing (OLAP) of my users. One such limitation was implementing strict timings for when these programs could be run; otherwise, they ended up using all available power and slowing down everyone else.
Today, you can buy a server with 64 GB RAM and several terabytes (TB) of storage at one-fifth the price. The extra power available can do wonders for us. Multiple storage and compute units can now be procured just for data analytics workloads. The extra power available enables users to run their workloads whenever they like, however they like. In fact, it is very common these days to run analytical workloads on a continuous basis using data streams, also known as stream processing.
The installation, management, and monitoring of multiple compute and storage units requires a well-designed data pipeline, which is often achieved through a data engineering practice.
Availability of varying datasets
A few years ago, the scope of data analytics was extremely limited. Performing data analytics simply meant reading data from databases and/or files, denormalizing the joins, and making it available for descriptive analysis. The structure of data was largely known and rarely varied over time.
We live in a different world now; not only do we produce more data, but the variety of data has increased over time. In addition to collecting the usual data from databases and files, it is common these days to collect data from social networking, website visits, infrastructure logs' media, and so on, as depicted in the following screenshot:

Figure 1.3 – Variety of data increases the accuracy of data analytics
Important note
More variety of data means that data analysts have multiple dimensions to perform descriptive, diagnostic, predictive, or prescriptive analysis.
Naturally, the varying degrees of datasets injects a level of complexity into the data collection and processing process. On the flip side, it hugely impacts the accuracy of the decision-making process as well as the prediction of future trends. A well-designed data engineering practice can easily deal with the given complexity.
The paradigm shift to distributed computing
The traditional data processing approach used over the last few years was largely singular in nature. To process data, you had to create a program that collected all required data for processing—typically from a database—followed by processing it in a single thread. This type of processing is also referred to as data-to-code processing. Unfortunately, there are several drawbacks to this approach, as outlined here:
- Since vast amounts of data travel to the code for processing, at times this causes heavy network congestion. Since a network is a shared resource, users who are currently active may start to complain about network slowness.
- Being a single-threaded operation means the execution time is directly proportional to the data. Therefore, the growth of data typically means the process will take longer to finish. This could end up significantly impacting and/or delaying the decision-making process, therefore rendering the data analytics useless at times.
- Something as minor as a network glitch or machine failure requires the entire program cycle to be restarted, as illustrated in the following diagram:
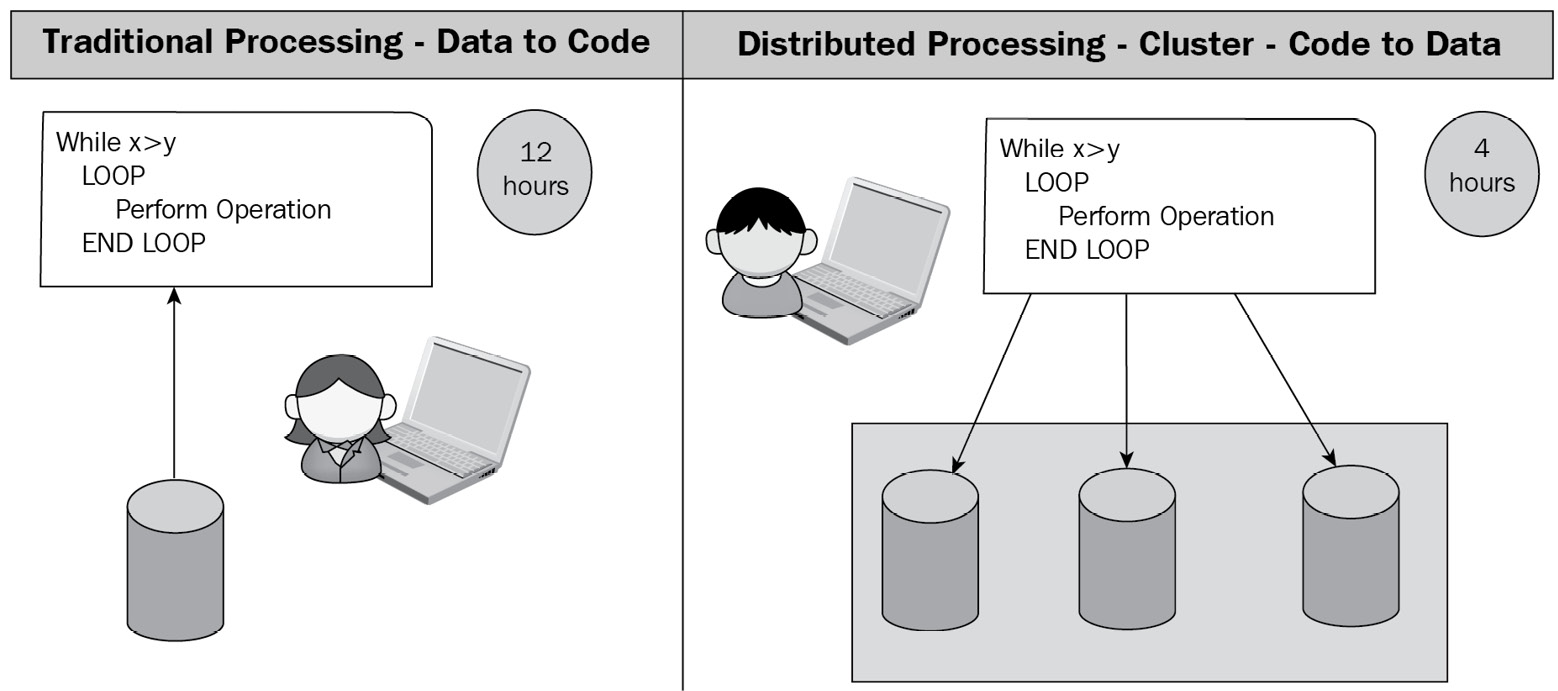
Figure 1.4 – Rise of distributed computing
The distributed processing approach, which I refer to as the paradigm shift, largely takes care of the previously stated problems. Instead of taking the traditional data-to-code route, the paradigm is reversed to code-to-data.
In a distributed processing approach, several resources collectively work as part of a cluster, all working toward a common goal. In simple terms, this approach can be compared to a team model where every team member takes on a portion of the load and executes it in parallel until completion. If a team member falls sick and is unable to complete their share of the workload, some other member automatically gets assigned their portion of the load.
Distributed processing has several advantages over the traditional processing approach, outlined as follows:
- The code-to-data paradigm shift ensures the network does not get clogged. The entire idea of distributed processing heavily relies on the assumption that data is stored in a distributed fashion across several machines, also referred to as nodes. At the time of processing, only the code portion (usually a much smaller footprint as compared to actual data) is sent over to each node that stores the portion of the data being processed. This ensures that the processing happens locally on the node where the data is stored.
- Since several nodes are collectively participating in data processing, the overall completion time is drastically reduced.
- Program execution is immune to network and node failures. If a node failure is encountered, then a portion of the work is assigned to another available node in the cluster.
Important note
Distributed processing is implemented using well-known frameworks such as Hadoop, Spark, and Flink. Modern massively parallel processing (MPP)-style data warehouses such as Amazon Redshift, Azure Synapse, Google BigQuery, and Snowflake also implement a similar concept.
Since distributed processing is a multi-machine technology, it requires sophisticated design, installation, and execution processes. That makes it a compelling reason to establish good data engineering practices within your organization.
Adoption of cloud computing
The vast adoption of cloud computing allows organizations to abstract the complexities of managing their own data centers. Migrating their resources to the cloud offers faster deployments, greater flexibility, and access to a pricing model that, if used correctly, can result in major cost savings.
In the previous section, we talked about distributed processing implemented as a cluster of multiple machines working as a group. For this reason, deploying a distributed processing cluster is expensive.
In the pre-cloud era of distributed processing, clusters were created using hardware deployed inside on-premises data centers. Very careful planning was required before attempting to deploy a cluster (otherwise, the outcomes were less than desired). You might argue why such a level of planning is essential. Let me address this:
- Since the hardware needs to be deployed in a data center, you need to physically procure it. The real question is how many units you would procure, and that is precisely what makes this process so complex.
- Order more units than required and you'll end up with unused resources, wasting money.
- Order fewer units than required and you will have insufficient resources, job failures, and degraded performance.
To order the right number of machines, you start the planning process by performing benchmarking of the required data processing jobs.
- The results from the benchmarking process are a good indicator of how many machines will be able to take on the load to finish the processing in the desired time. You now need to start the procurement process from the hardware vendors. Keeping in mind the cycle of procurement and shipping process, this could take weeks to months to complete.
- Once the hardware arrives at your door, you need to have a team of administrators ready who can hook up servers, install the operating system, configure networking and storage, and finally install the distributed processing cluster software—this requires a lot of steps and a lot of planning.
I hope you may now fully agree that the careful planning I spoke about earlier was perhaps an understatement. The complexities of on-premises deployments do not end after the initial installation of servers is completed. You are still on the hook for regular software maintenance, hardware failures, upgrades, growth, warranties, and more.
This is precisely the reason why the idea of cloud adoption is being very well received. Having resources on the cloud shields an organization from many operational issues. Additionally, the cloud provides the flexibility of automating deployments, scaling on demand, load-balancing resources, and security.
Important note
Many aspects of the cloud particularly scale on demand, and the ability to offer low pricing for unused resources is a game-changer for many organizations. If used correctly, these features may end up saving a significant amount of cost. Having a well-designed cloud infrastructure can work miracles for an organization's data engineering and data analytics practice.
Data storytelling
I started this chapter by stating Every byte of data has a story to tell. Data storytelling is a new alternative for non-technical people to simplify the decision-making process using narrated stories of data. Traditionally, decision makers have heavily relied on visualizations such as bar charts, pie charts, dashboarding, and so on to gain useful business insights. These visualizations are typically created using the end results of data analytics. The problem is that not everyone views and understands data in the same way. Let me give you an example to illustrate this further.
Here is a BI engineer sharing stock information for the last quarter with senior management:
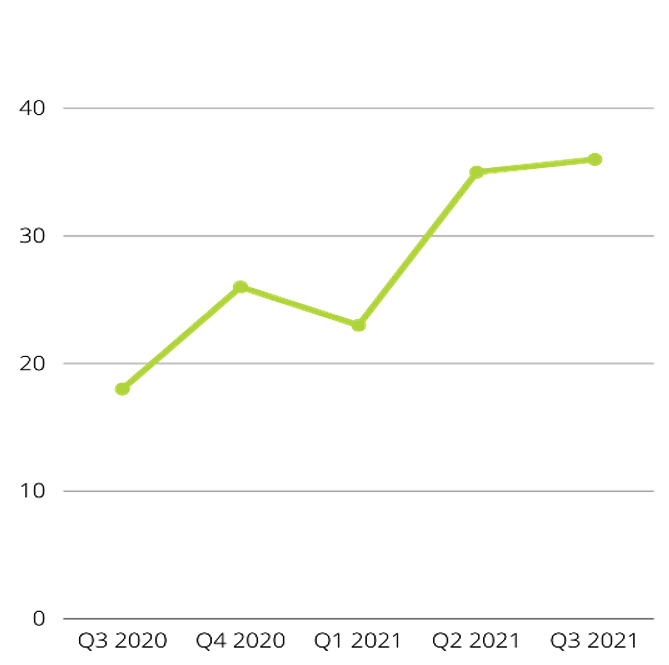
Figure 1.5 – Visualizing data using simple graphics
And here is the same information being supplied in the form of data storytelling:

Figure 1.6 – Storytelling approach to data visualization
Important note
Visualizations are effective in communicating why something happened, but the storytelling narrative supports the reasons for it to happen.
Data storytelling tries to communicate the analytic insights to a regular person by providing them with a narration of data in their natural language. This does not mean that data storytelling is only a narrative. It is a combination of narrative data, associated data, and visualizations. With all these combined, an interesting story emerges—a story that everyone can understand.
As data-driven decision-making continues to grow, data storytelling is quickly becoming the standard for communicating key business insights to key stakeholders.
There's another benefit to acquiring and understanding data: financial. Let's look at the monetary power of data next.


