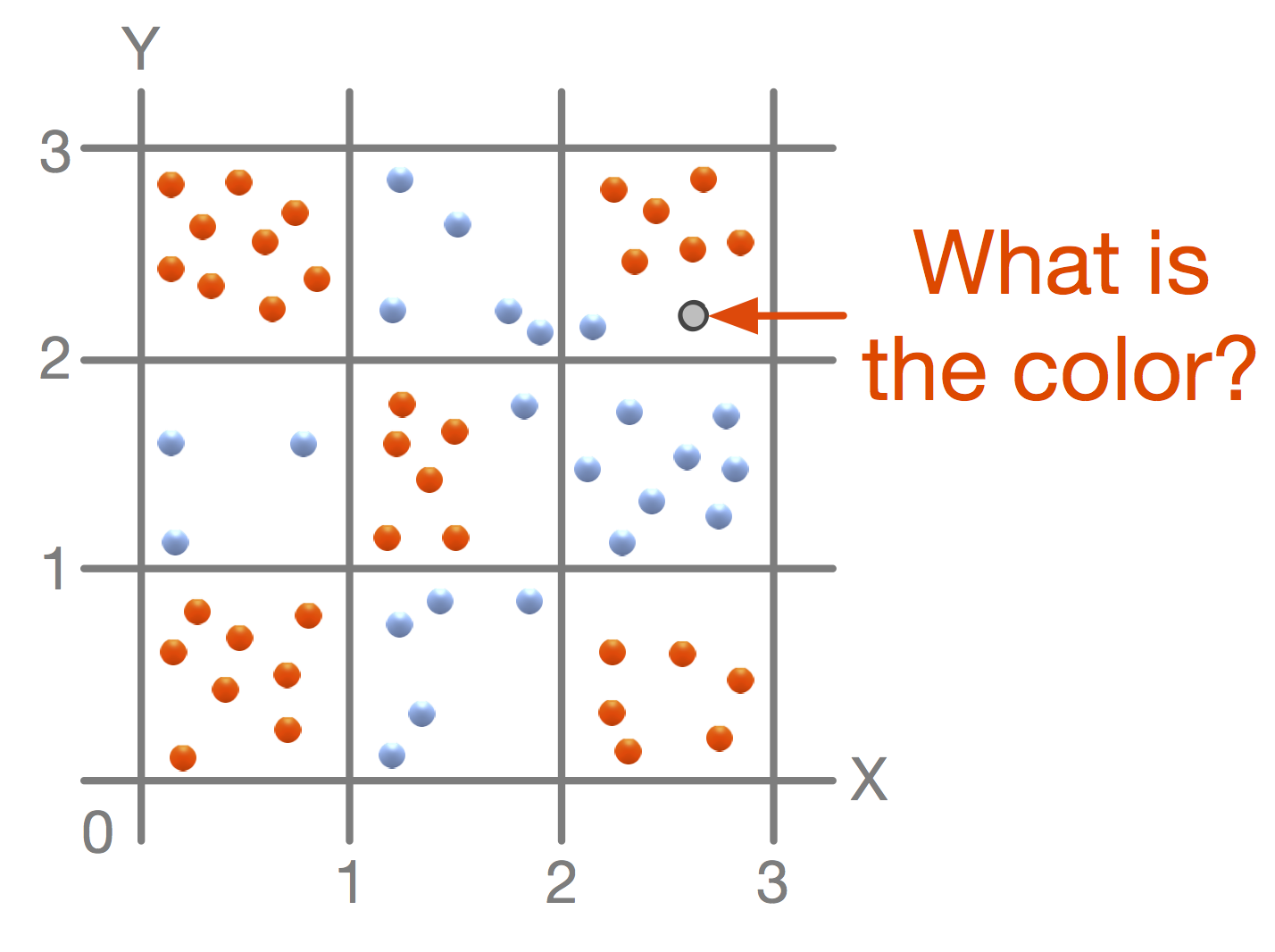
For now, let's assume that the number of points is huge and cannot fit into the memory of a single machine. Hence, we need multiple machines, and we have to partition data in such a way that each machine contains only a subset of data. This way, we solve the memory problem; however, it also means that we need to distribute the computation around a cluster of machines. This is the first difference from single-machine computing. If your data fits into a single machine memory, it is easy to make decisions about data, since the algorithm can access them all at once, but in the case of a distributed algorithm, this is not true anymore and the algorithm has to be "clever" about accessing the data. Since our goal is to build a decision tree that predicts the color of a new point in the board, we need to figure out how to make the tree that will be the same as a tree built on a single machine.
The naive solution is to build a trivial tree that separates the points based on machine boundaries. But this is obviously a bad solution, since data distribution does not reflect color points at all.
Another solution tries all the possible split decisions in the direction of the X and Y axes and tries to do the best in separating both colors, that is, divides the points into two groups and minimizes the number of points of another color. Imagine that the algorithm is testing the split via the line, X = 1.6. This means that the algorithm has to ask each machine in the cluster to report the result of splitting the machine's local data, merge the results, and decide whether it is the right splitting decision. If it finds an optimal split, it needs to inform all the machines about the decision in order to record which partition each point belongs to.
Compared with the single machine scenario, the distributed algorithm constructing decision tree is more complex and requires a way of distributing the computation among machines. Nowadays, with easy access to a cluster of machines and an increasing demand for the analysis of larger datasets, it becomes a standard requirement.
Even these two simple examples show that for a larger data, proper computation and distributed infrastructure is required, including the following:
- A distributed data storage, that is, if the data cannot fit into a single node, we need a way to distribute and process them on multiple machines
- A computation paradigm to process and transform the distributed data and to apply mathematical (and statistical) algorithms and workflows
- Support to persist and reuse defined workflows and models
- Support to deploy statistical models in production
In short, we need a framework that will support common data science tasks. It can be considered an unnecessary requirement, since data scientists prefer using existing tools, such as R, Weka, or Python's scikit. However, these tools are neither designed for large-scale distributed processing nor for the parallel processing of large data. Even though there are libraries for R or Python that support limited parallel or distributed programming, their main limitation is that the base platforms, that is R and Python, were not designed for this kind of data processing and computation.