






















































Clustering
So far, our Jira instance is running in standalone mode, which means it is serving all the requests by itself and is not yet cluster-enabled. Some of the main benefits of running Jira in a cluster are as follows:
- Improved performance at scale: By running a cluster with multiple nodes, Jira’s ability to serve concurrent user requests is greatly improved, leading to better response time and overall user satisfaction.
- High availability and failover: With multiple nodes running in a cluster, if any individual node becomes unavailable for any reason, other nodes within the cluster can continue to serve your users, thus avoiding downtime.
- Zero-downtime upgrade: Usually, when you need to upgrade Jira, there will be downtime involved in the process. When running a Jira cluster, you can upgrade each node individually at a time so that other nodes in the cluster can continue to serve your users.
To configure Jira to run in a cluster, you must do the following:
- Create a shared file home directory for both nodes to access.
- Add cluster configuration to our current Jira instance.
- Add another Jira instance to be the second node in our cluster. Technically, you can have a single node cluster, but for this exercise, we will add another node to the cluster so that you can see the cluster in action.
- Add and configure a load balancer to distribute incoming traffic to both nodes.
Now that we know what we need to run Jira in a cluster, let’s start preparing!
Preparing for clustering
The first step in enabling clustering is to prepare the hardware required. For a Jira cluster, you will have the following components:
- Load balancer: This can be any load balancer that supports session affinity (sticky sessions), such as Apache and nginx.
- Jira instance node: This will contain separate Jira instances that will be part of the cluster.
- Database: This is the same database you are using for your standalone deployment. Note that since all Jira nodes will be sharing the same database, the in-memory H2 database will not work in a cluster.
- Shared file drive: The Jira cluster needs to have a shared home directory that all Jira nodes can read and write to.
Ideally, each component listed previously should be running on its own server, so for a two-node cluster, you will need a minimum of three servers and a shared network drive. You can run multiple Jira nodes on the same server, but you should only do this for evaluation purposes, as it diminishes the benefits of having a cluster.
When preparing servers for the Jira nodes, you need to ensure the following:
- All node servers are located in the same data center or region (for cloud vendors such as AWS and Azure)
- You have the same software and hardware specifications, including memory, operating system, and Java version
- All nodes are running the same version of Jira
- The nodes have been configured to be in the same timezone
Creating JIRA_SHARED_HOME
The first step is to create a new directory where the cluster can store its data files. We will refer to this directory as JIRA_SHARED_HOME. This can be a network drive that allows all Jira nodes to read from and write to. Copy over the following directories from your standalone Jira instance’s JIRA_HOME directory to the new shared directory:
datapluginslogosimportexportcaches
Enabling clustering
The second step is to enable clustering for your first Jira node. This is done by adding a new cluster.properties file to its local JIRA_HOME directory.
- Shut down your Jira standalone instance.
- Create a new file called
cluster.properties. - Add the following lines to the files:
# This ID must be unique across the cluster jira.node.id = node1 # The location of the shared home directory for all Jira nodes jira.shared.home = /location/to/the/shared/jira_cluster_home # The following lines are needed if you want to run multiple nodes on the same server ehcache.listener.hostName=localhost ehcache.listener.port=40001 ehcache.object.port = 40021
- Start Jira.
Adding a node to the load balancer
With the first cluster node up and running, we can add another node. We need to add this node to the load balancer so that it can start routing traffic to it. The exact configuration will differ, depending on what you use for the load balancer. The following is an example using Apache:
<Proxy balancer://jiracluster> # Jira node 1 BalancerMember http://jira1.internal.atlassian.com:8080 route=node1 # Jira node 2, add this when we have the 2nd node up and running # BalancerMember http://jira2.internal.atlassian.com:8080 route=node2 # Load Balancer Settings ProxySet lbmethod=byrequests ProxySet stickysession=JSESSIONID </Proxy>
Note that for Apache, you will need to enable the proxy_balancer_module module.
Adding new nodes to the cluster
To add a new node to the cluster, follow these steps:
- Copy over the
JIRA_HOMEdirectory from our existing Jira instance to the new node server. - Install a new Jira instance on the new server.
- Edit the
cluster.propertiesfiles and change thejira.node.idvalue. - Add the new node to the load balancer.
- Start the new Jira node.
If you are running the second node on the same server, you will also need to change the port numbers for ehcache.listener.port and ehcache.object.port in the cluster.properties file, and the port numbers in the server.xml file, as mentioned in the Changing Jira’s port number and context path section.
And with this, you should have a two-node Jira cluster up and running. Now, if you log into Jira and go to Administration | System | Clustering, you should see both nodes listed, with the node currently serving you highlighted in bold, as shown here:
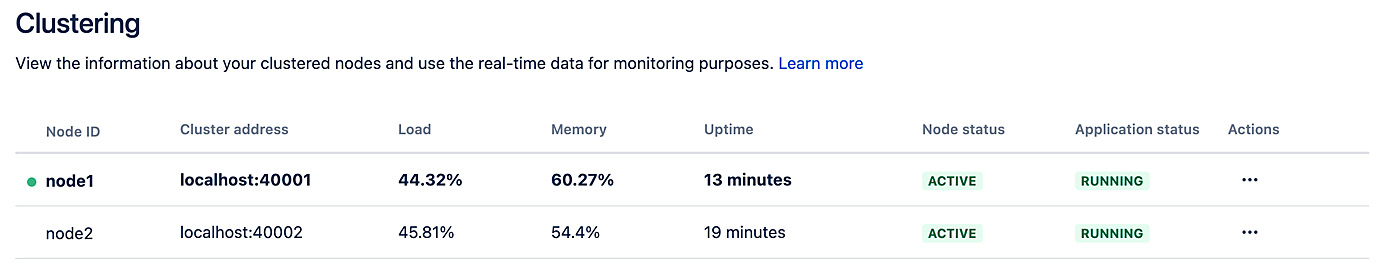
Figure 1.21 – Cluster nodes in Jira
On this page, you can see all the nodes in your cluster and their status. This is very useful to help you troubleshoot your cluster if a node becomes unresponsive or is under heavy load.










