






















































The architecture of a legacy app
In this section, we will look at how Android applications used to be built in the past and what difficulties developers had with the approach taken.
Before we start analyzing an older application, we must distinguish the architecture and design of an application. To borrow from the construction industry, we can define architecture as a plan for the structure of a building; a design would be a plan to create each part of the building. Translating this into the world of software engineering, we can say that the architecture of an application or a system would be defining a plan that would incorporate the business and technical requirements, while software design deals with integrating all the components, modules, and frameworks into this plan. In an ideal world, you would want to recognize the architecture of an application in the same way you would recognize the architecture of your house.
Now, let's look at the four main components of an Android application:
- Activities: These represent the entry points for interacting with the user.
- Services: These represent the entry points for having an app run in the background for all kinds of reasons, such as large downloads or audio playback.
- Broadcast Receivers: These allow the system to interact with an application for a variety of reasons.
- Content Providers: These represent a way for an application to manage application data.
Using and relying on these components created a challenge for developers because an app's architecture became dependent on the Android framework, mainly when it came to implementing unit tests. To understand why this is a problem, let's look at an example of what some older application code would look like. Let's suppose you have been asked to fetch some data from a backend service. The data would be served in the form of JSON through an HTTP connection.
It wasn't uncommon to see a class such as BaseRequest.java, which would execute the request and depend on abstraction in the form of JsonMapper.java, to convert the data from a String into a Plain Old Java Object (POJO). The following code represents an example of how fetching the data might be implemented:
public class BaseRequest<O> {
private final JsonMapper<O> mapper;
protected BaseRequest(JsonMapper<O> mapper) {
this.mapper = mapper;
}
public O execute() {
try {
URL url = new URL("schema://host.com/path");
HttpURLConnection urlConnection =
(HttpURLConnection) url.openConnection();
int code = urlConnection.getResponseCode();
StringBuilder sb = new StringBuilder();
BufferedReader rd = new BufferedReader(new
InputStreamReader(urlConnection.
getInputStream()));
String line;
while ((line = rd.readLine()) != null) {
sb.append(line);
}
return mapper.convert(new JSONObject
(sb.toString()));
} catch (Exception e) {
…
} finally {
if (urlConnection != null) {
urlConnection.disconnect();
}
}
return null;
}
}
In the execute method, we would use HttpURLConnection to connect to the backend service and retrieve the data. Then, we would read it into a String, which would then be converted into a JSONObject and then passed to JsonMapper to be converted into a POJO.
The JsonMapper.java interface would look something like this:
interface JsonMapper<T> {
T convert(JSONObject jsonObject) throws JSONException;
}
This interface represents the abstraction of converting a JSONObject into any POJO.
The use of generics allows us to apply this logic to any POJO. In our case, the POJO should look something like ConcreteData.java:
public class ConcreteData {
private final String field1;
private final String field2;
public ConcreteData(String field1, String field2) {
this.field1 = field1;
this.field2 = field2;
}
public String getField1() {
return field1;
}
public String getField2() {
return field2;
}
}
The ConcreteData class will be responsible for holding the data we will receive from the backend service. In this case, we just have two String instance variables.
Now, we need to create a concrete JsonMapper.java that will be responsible for converting a JSONObject into ConcreteData:
public class ConcreteMapper implements JsonMapper<ConcreteData> {
@Override
public ConcreteData convert(JSONObject jsonObject) {
return new ConcreteData(jsonObject.optString
("field1"), jsonObject.optString("field2"));
}
}
The convert method creates a new ConcreteData object, extracts the data from the JSONObject object, and populates the field1 and field2 values.
Next, we must create a ConcreteRequest.java that will extend BaseRequest and use ConcreteMapper:
public class ConcreteRequest extends BaseRequest<ConcreteData> {
public ConcreteRequest() {
super(new ConcreteMapper());
}
}
This class will inherit the execute method from BaseRequest and supply a new ConcreteMapper object so that we can convert the backend data into ConcreteData.
Finally, we can use this in our Activity to execute the request and update our user interface (UI) with the result. Here, we have a limitation: we cannot execute long-running operations on the main (UI) thread and we cannot update our views from any other thread except the UI thread. This means that we would need something to help with this. Luckily, Android provides the AsyncTask class, which offers a set of methods for doing work on a separate thread and then processing the results on the main thread. However, we risk creating a context leak (if, for any reason, the Activity object is destroyed, then the garbage collector will not be able to collect the Activity object while AsyncTask is running since Activity has a dependency on AsyncTask) by using an inner AsyncTask class. To circumvent this, the recommended approach is to create a WeakReference for our Activity. This way, if the Activity object is destroyed either by the user or the system, its reference can be collected by the garbage collector.
Now, let's look at the code for our MainActivity:
public class MainActivity extends Activity {
private TextView textView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
this.textView = findViewById(R.id.text_view);
new LoadConcreteDataTask(this).execute();
}
private void update(ConcreteData concreteData) {
textView.setText(concreteData.getField1());
}
}
This class is responsible for loading the UI and starting LoadConcreteDataTask. The update method will then be called by LoadConcreteDataTask to show the data in the user interface.
LoadConcreteDataTask must be an inner class of MainActivity:
public class MainActivity extends Activity {
…
private static class LoadConcreteDataTask extends
AsyncTask<Void, Void, ConcreteData> {
private final WeakReference<MainActivity>
mainActivityWeakReference;
private LoadConcreteDataTask(MainActivity
mainActivity) {
this.mainActivityWeakReference = new
WeakReference<>(mainActivity);
}
@Override
protected ConcreteData doInBackground(Void...
voids) {
return new ConcreteRequest().execute();
}
@Override
protected void onPostExecute(ConcreteData
concreteData) {
super.onPostExecute(concreteData);
MainActivity mainActivity =
mainActivityWeakReference.get();
if (mainActivity != null) {
mainActivity.update(concreteData);
}
}
}
}
In LoadConcreteDataTask, we take advantage of the doInBackground method, which is executed on a separate thread to load our data and then update our UI in the onPostExecute method. We also hold a WeakReference to MainActivity so that it can be safely garbage collected when destroyed. This also means that we will need to check if the reference still exists before updating the user interface.
The class diagram for the preceding code looks as follows:
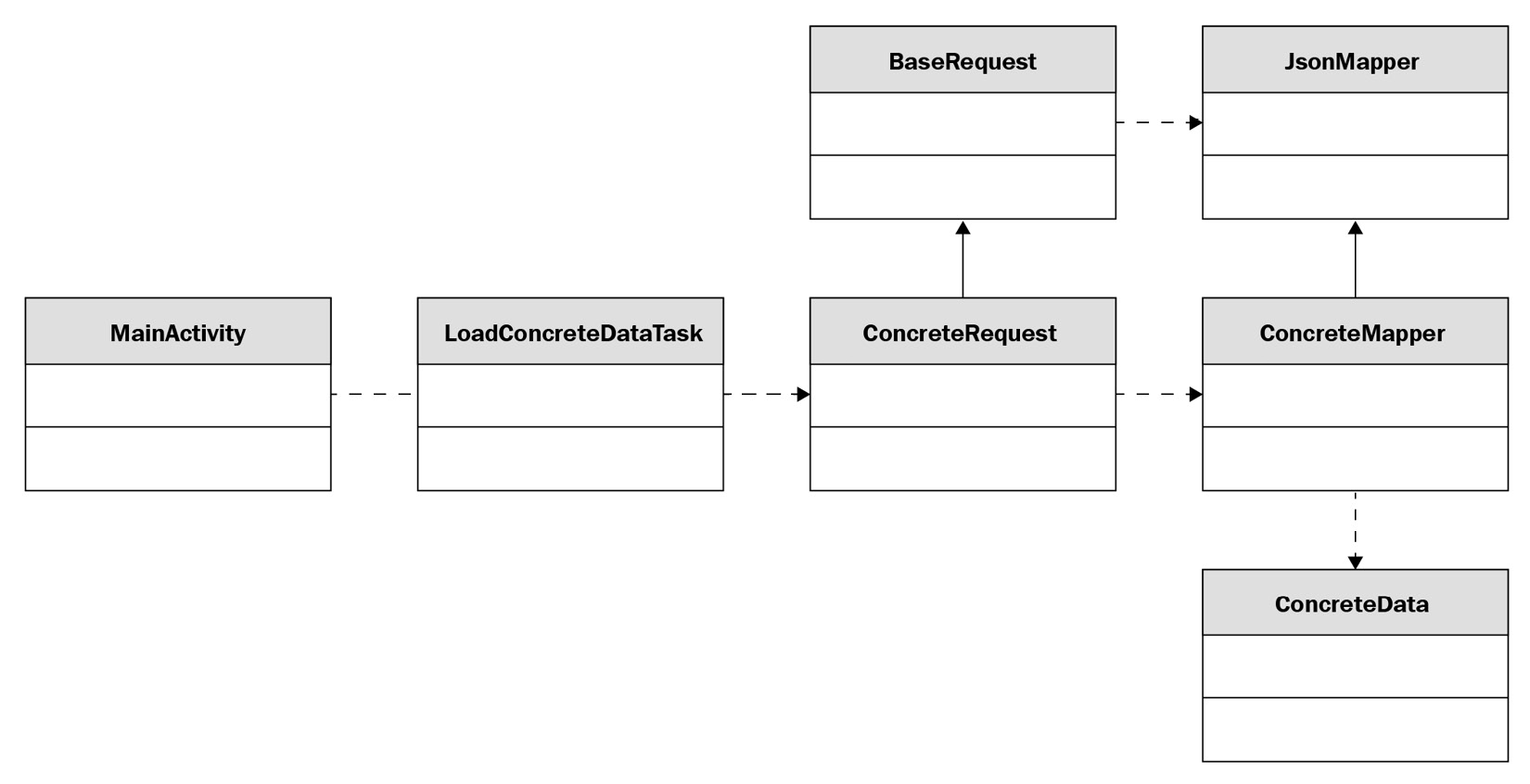
Figure 1.1 – A class diagram for an older Android app
Here, we can see how the dependencies move from MainActivity toward the ConcreteRequest class, with one exception between MainActivity and LoadConcreteDataTask, where both classes depend on each other. This is a problem because the classes are then coupled together and making a change to one implies making a change to the other. Later in this chapter, we will look at some principles that can help us avoid such dependencies.
Now that we have an idea of what a legacy application looks like, let's see what issues we may encounter if we follow this path.
Legacy analysis
In this section, we will analyze some of the problems that legacy applications have.
Let's ask ourselves the following questions:
- What can we unit test?
- What happens if, instead of showing the value of
field1fromConcreteData, we need to showfield1+field2? - What happens when the requirements for this particular screen change and data needs to be retrieved from another endpoint on top of this one?
- What happens if we need to introduce caching or SQLite persistence?
- What happens if another activity needs this particular use case?
Let's answer these questions:
- Answer 1: The answers to all of these questions will come with headaches. The first question is a mix of technical limitations and doubtful design techniques. The technical limitation comes from the fact that the code will execute on the device or an emulator, but we want our unit tests to be executed on our development machines. This is the reason we have the split between the
androidTestandtestdirectories. Theoretically, we can write our unit tests so that they can run on the emulator, but that takes more time and instability. We can now execute these types of tests in the cloud using technologies such as Firebase Test Lab, but that would inevitably cost us money and it's in our interest to avoid taking in such costs. Realistically, we are left with one option and that is to test as much as possible using local unit tests instead of instrumented ones. To solve this, we will need to separate the Android components we use from the Java components. - Answer 2: The second question produces a similar problem. The easiest choice here would be to put that concatenation into
MainActivityor add a method into theConcreteDataclass that will return the concatenated result. But either of these will come with downsides. If we move the concatenation intoMainActivity, we will put logic that can be unit tested into a class that is very hard and shouldn't be unit tested. If we create a method to concatenate inConcreteData, we risk giving responsibility to this class that it shouldn't have since it's related more to the UI than the actual representation of the JSON itself. What if, in the future, the networking aspect is developed by another team? You would need to rely on that particular team to create this update. - Answer 3: The answer to the third question looks straightforward as well. We must create new concrete implementations for the new data to be added and the associated request. Then, we will either create a separate class that will extend
AsyncTaskor execute both requests in the sameLoadConcreteDataclass and then update the UI. If we create a separateAsyncTask, then we will need to make the activity responsible for managing the results and balance the twoAsyncTasks, which again creates a problem concerning testing. If we execute the requests in the sameAsyncTask, then the responsibility ofAsyncTaskincreases, which we may want to avoid. - Answer 4: The fourth question presents us with a new challenge. Let's say we add a new database class that contains all the methods to perform create, read, update, and delete (CRUD) operations. Which one of our classes would have a dependency on this class? The choices here would be between the two request classes and
LoadConcreteDataTask. Here, we run into the same issues that we did in the previous questions. If we used the request classes, we would end up being more responsible for dealing with HTTP connections than handling calls to the database. If we useLoadConcreteDataTask, we make the answer to the fifth question even harder. - Answer 5: Based on the previous answers, we notice that a lot of work may end up being moved to the
LoadConcreteDataTaskclass. Now, let's imagine that another activity with a completely different UI and a different interpretation of that data will rely on the same use case. One solution is to duplicateLoadConcreteDataTaskinto the new activity. This is not a great idea because a change in the requirements will make the developers change all the tasks. A better approach would be to create a new abstraction that will remove the dependency betweenLoadConcreteDataTaskandActivity. This would allow us to reuse the same class for both activities. Let's say that the activities would need different types of data for each interpretation. Here, we could follow theJsonMapperexample and create an interface that would convertConcreteDatainto a generic type, provide two implementations for each activity, and create the necessary POJOs to convert into.
Another question that can be asked here is, "What amount of work would be necessary to export the business logic into another project?" This is an important question because it highlights how we should structure our code so that it can be reused by others without making it a pain for them to integrate. If we were to answer this, we must first ask, "Where's the business logic?" The answer would probably be LoadConcreteDataTask. Can we export that and publish it somewhere where other developers can get it?
The answer is no, because of its dependency on MainActivity. This question highlights an important aspect of defining an architecture, namely drawing the boundaries around your components. A component can be defined as the smallest piece of deliverable code. In our case, it would be the equivalent of a module. Now, let's say we were in a place where we could ship out our LoadConcreteDataTask. A follow-up question would be, "Would the data be hosted on the same service?" followed by, "Is it in the same JSON format?" Here, we would need to draw a boundary between LoadConcreteDataTask and BaseRequest and remove such dependencies on how the data is retrieved.
The reason these questions were raised and answered is that all those scenarios have happened in the past and they will all likely happen in the life cycle of an application. We, as developers, tend to answer those questions in our code differently based either on time constraints, the rigor imposed on the team we work in, our ambition to deliver something fast by constantly challenging ourselves, and our experience or the team's experience. The fact that we had the option to make a less desirable solution or to be stuck in a situation where we had to pick between the frying pan or the fire represents a problem. Sometimes, it is good to take a step back from our daily routine, ask ourselves some of these questions, do mind experiments to see how our code may end up in those scenarios, and assess what would happen if that would happen now or 1 or 2 years from now.
A common scenario a lot of Android developers found themselves in was having a lack of businesses investing in testing because it would take too much time and there was a need to go to market. In many of these cases, the apps became harder to maintain over time, so more developers needed to be hired to keep the same productivity as a team compared to when they had fewer developers. When code is written with the notion that it needs to be unit tested, then the way we write that code becomes more rigorous and more maintainable. We start keeping track of how we create instances and separate the things we can test from the things we can't, we apply creational design patterns, and we also shorten the sizes of the methods in our classes, among other things.
We now have an idea of how applications used to be written in the past and the problems that were caused by the approaches that were taken, such as issues with the testability and maintainability of an application due to dependencies on the Android framework. Next, we will look at some design principles that will prove useful in how we write an application.










