






















































Building RAG architecture systems
In the dynamic landscape of modern business, the relentless pursuit of efficiency and accuracy urges organizations to adopt cutting-edge technologies. Among these, automation stands as a cornerstone, particularly in processing and automating workflows. However, traditional methods suffer when they’re subjected to large volumes of data with intricate tasks, and human-led processes often fall short due to error-prone manual interventions.
This section explores the transformative landscape of automation, discussing the pivotal role RAG plays in revolutionizing business operations. MongoDB, known for its prowess in data management and flexible schemas, offers a compelling synergy with RAG through its vector search and full-text search capabilities. Delving into the architectural details of RAG, this section dissects its constituent building blocks, offering practical insights into constructing automated document-processing workflows that harness the full potential of LLMs and MongoDB Vector Search.
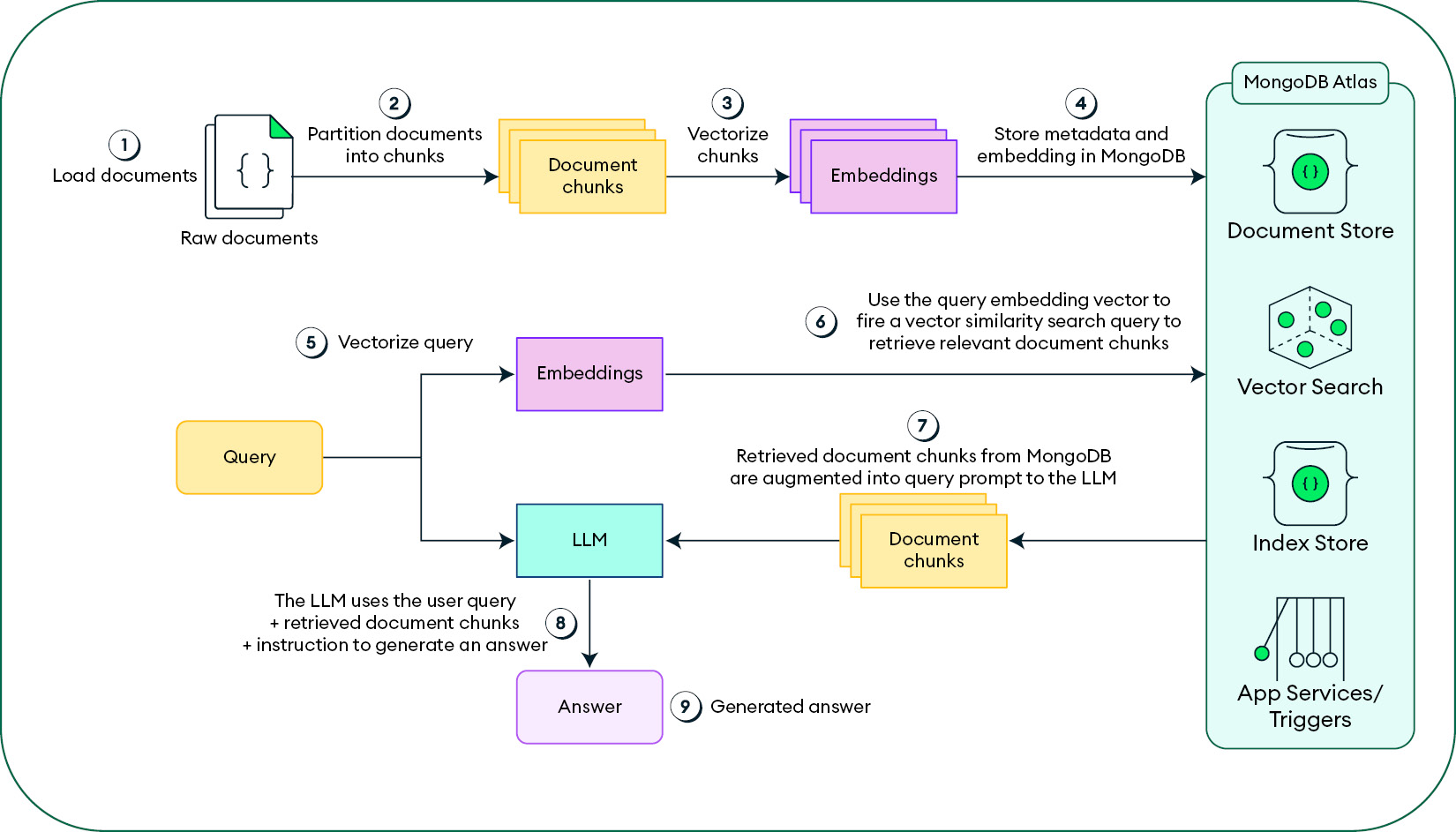
Figure 8.6: Building blocks of RAG architecture
Let’s go over the key components of the RAG architecture in detail:
- Document loading: Initially, documents are loaded from data storage. This involves text extraction, parsing, formatting, and cleaning to prepare the data for document splitting.
- Document splitting: The next step is to break down the documents into smaller, manageable segments or chunks. Strategies for splitting can vary, from fixed-size chunking to content-aware chunking that considers the content structure.
- Text embedding: These document chunks are then transformed into vector representations (embeddings) using techniques such as OpenAIEmbeddings, Sentence e-BERT, and Instructor Embeddings. This step is crucial for understanding the semantic content of the chunks.
- Vector store: The generated vectors, each associated with unique document chunks, are stored in a vector store alongside the document chunks and other metadata extracted from the MongoDB Atlas collection. Atlas Vector Search indexes and Apache Lucene search can be built through the MongoDB Atlas UI for easy and fast retrieval.
- Query processing: When a user submits a query, it is also converted into a vector representation using the same embedding technique as mentioned in Step 3.
- Document retrieval: The retriever component locates and fetches document chunks that are semantically like the query. This retrieval process employs vector similarity search techniques and MongoDB Atlas using the Hierarchical Navigable Small Worlds (HNSW) algorithm to perform a fast nearest neighbor search to retrieve relevant documents without compromising the accuracy of the retrieved search results.
- Document chunk post-filtering: The relevant document chunks are retrieved from the MongoDB collection with the help of the Unified Query API and can be post-filtered easily to transform the output document chunks into the required format.
- LLM prompt creation: The retrieved document chunks and the query are combined to create a context and prompt for the LLM.
- Answer generation: Finally, the LLM generates a response based on the prompt, completing the RAG process.
In the context of RAG systems, there are two primary types: simple (or naive) RAG and advanced RAG. In practical scenarios, this classification helps address different types of personas and questions the applications are handling, and it’s common to encounter both simple and complex RAG queries within the same workflow and from the same persona. As a developer, it is important to reason out the functionalities that the application is expected to serve before deciding on the building blocks involved in the RAG architecture.
When building your RAG architecture system, consider the following points to help with programming and planning:
- Workflow specificity: Define the specific workflow you intend to automate with RAG; it may be related to question answering (QA), data augmentation, summarization, reasoning, or assertion. Maybe your customers frequently ask a specific set of three or four types of queries.
- User experience: Collaborate with your target user group to understand the types of queries they are likely to ask to identify the user group journey, which might be a simple single-state response or a multi-state chat flow.
- Data sources: First, identify the nature of your data source—whether it’s unstructured or structured. Next, map the locations of these data sources. Once you’ve done that, classify the data based on whether it serves operational or analytical purposes. Finally, observe the data patterns to determine whether answers are readily available in one location or if you’ll need to gather information from multiple sources.
These pointers will help you determine whether you need to go for a simple RAG system or an advanced RAG system and also help you to determine the essential building blocks to consider while constructing your RAG architecture.
Now, let’s delve deeper into the building blocks of this architecture with some code examples to better explain the nuances. However, before you develop RAG-powered applications, let’s look at the fundamentals of how to process source documents to maximize the accuracy of the rated responses from the RAG application. The following strategies will come in handy while processing documents before storing them in a MongoDB Atlas collection.
Chunking or document-splitting strategies
Chunking or document splitting is a critical step in handling extensive texts within RAG systems. When dealing with large documents, the token limits imposed by language models (such as gpt-3.5-turbo) necessitate breaking them into manageable chunks. However, a naive fixed-chunk-size approach can lead to fragmented sentences across chunks, affecting subsequent tasks such as QA.
To address this, consider semantics when dividing documents. Most segmentation algorithms use chunk size and overlap principles. Chunk size (measured by characters, words, or tokens) determines segment length, while overlaps ensure continuity by sharing context between adjacent chunks. This approach preserves semantic context and enhances RAG system performance.
Now, let’s delve into the intricacies of document-splitting techniques, particularly focusing on content-aware chunking. While fixed-size chunking with overlap is straightforward and computationally efficient, more sophisticated methods enhance the quality of text segmentation. The following are the various document-splitting techniques:
- Recursive chunking: This technique includes the following approaches:
- Hierarchical approach: Recursive chunking breaks down input text into smaller chunks iteratively. It operates hierarchically, using different separators or criteria at each level.
- Customizable structure: By adjusting the criteria, you can achieve the desired chunk size or structure. Recursive chunking adapts well to varying document lengths.
- Sentence splitting: Sentence splitting involves various strategies, such as the ones listed here:
- Naive splitting: This method relies on basic punctuation marks (such as periods and new lines) to divide text into sentences. While simple, it might not handle complex sentence structures well.
- spaCy: Another robust NLP library, spaCy, offers accurate sentence segmentation. It uses statistical models and linguistic rules.
- Natural Language Toolkit (NLTK): NLTK, a powerful Python library for NLP, provides efficient sentence tokenization. It considers context and punctuation patterns.
- Advanced tools: Some tools employ smaller models to predict sentence boundaries, ensuring precise divisions.
- Specialized techniques: Specialized techniques include the following:
- Structured content: For documents with specific formats (e.g., Markdown, LaTeX), specialized techniques come into play.
- Intelligent division: These methods analyze the content’s structure and hierarchy. They create semantically coherent chunks by understanding headings, lists, and other formatting cues.
In summary, while fixed-size chunking serves as a baseline, content-aware techniques consider semantics, context, and formatting intricacies. Choosing the right method depends on your data’s unique characteristics and the requirements of your RAG system. While choosing the retriever for storing and retrieving these chunks, you may want to consider solutions such as document hierarchies and knowledge graphs. MongoDB Atlas has a flexible schema and a simple unified query API to query data from it.
Now let’s use the recursive document-splitting strategy to build a simple RAG application.
Simple RAG
A simple RAG architecture implements a naive approach where the model retrieves a predetermined number of documents from the knowledge base based on their similarity to the user’s query. These retrieved documents are then combined with the query and input into the language model for generation, as shown in Figure 8.7.

Figure 8.7: Naive RAG
To build a simple RAG application, you will use the dataset you loaded to the MongoDB Atlas collection in the Information retrieval with MongoDB Vector Search section of this chapter. With this application, you’ll be able perform queries on the available movies and create a recommender system.
LLM
This example will use the OpenAI APIs and gpt-3.5-turbo, but there are other variations of LLM models made available from OpenAI, such as gpt-4o and gpt-4o-mini. The same prompting technique can be used with other LLMs, such as claude-v2 or mistral8x-7B, to achieve similar results.
The following is the sample code to invoke the OpenAI LLM using LangChain:
from openai import OpenAI
client = OpenAI()
def invoke_llm(prompt, model_name='gpt-3.5-turbo-0125'):
"""
Queries with input prompt to OpenAI API using the chat completion api gets the model's response.
"""
response = client.chat.completions.create(
model=model_name,
messages=[
{
«role»: «user»,
«content»: prompt
}
],
temperature=0.2,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
chatbot_response = response.choices[0].message.content.strip()
return chatbot_response
invoke_llm("This is a test") Here is the result:
'Great! What do you need help with?'
Now that you have the APIs to call MongoDB Atlas Vector Search for retrieval and an API for invoking an LLM, you can combine these two tools to create a RAG system.
Prompt
A prompt to an LLM is a user-provided instruction or input that guides the model’s response. It can be a question, a statement, or a command, and is designed to drive the LLM to respond with a specific output. The effectiveness of a prompt can greatly influence the quality of the results generated by a RAG-based system, making prompt engineering a crucial aspect for interacting with these models. Good prompts are clear, specific, and structured to communicate the user’s intent to the LLM, enabling it to generate the most accurate and helpful responses possible.
The following is an example of a prompt to perform QA on a private knowledge base:
def get_prompt(question, context):
prompt = f"""Question: {question}
System: Let's think step by step.
Context: {context}
"""
return prompt
def get_recommendation_prompt(query, context):
prompt = f"""
From the given movie listing data, choose a few great movie recommendations.
User query: {query}
Context: {context}
Movie Recommendations:
1. Movie_name: Movie_overview
"""
return prompt To demonstrate the benefits of RAG over a foundational LLM, let's first ask the LLM a question without vector search context and then with it included. This will demonstrate how you can improve the accuracy of the results and reduce hallucinations while utilizing a foundational LLM, such as gpt-3.5-turbo, that was not trained on a private knowledge base.
Here is the query response without vector search:
print(invoke_llm("In which movie does a footballer go completely blind?")) This is the result:
The Game of Their Lives" (2005), where the character Davey Herold, a footballer, goes completely blind after being hit in the head during a game
Although the LLM’s response shows it struggles with factual accuracy, there is still promise in using it alongside human oversight for enterprise applications. Together, these systems can work effectively to power applications for businesses. To help overcome this issue, you need to add context to the prompt through vector search results.
Let's see how you can use the invoke_llm function with the query_vector_search method to provide the relevant context alongside the user query to generate a response with a factually correct answer:
idea = "In which movie does a footballer go completely blind?"
search_response = query_vector_search(idea, prefilter={"year":{"$gt": 1990}}, postfilter={"score": {"$gt":0.8}},topK=10)
premise = "\n".join(list(map(lambda x:x['final'], search_response)))
print(invoke_llm(get_prompt(idea, premise))) Here is the result:
The movie in which a footballer goes completely blind is "23 Blast."
Similarly, you can use the get_recommendation_prompt method to generate some movie recommendations using a simple RAG framework:
question = "I like Christmas movies, any recommendations for movies release after 1990?"
search_response = query_vector_search(question,topK=10)
context = "\n".join(list(map(lambda x:x['final'], search_response)))
print(invoke_llm(get_recommendation_prompt("I like Christmas movies, any recommendations for movies release after 1990?", context))) Here is the result:

Figure 8.8: Sample output from the simple RAG application
The simple RAG system you just built can handle straightforward queries that need answers to the point. Some examples are a customer service chatbot responding to a basic question such as “Where is the customer support center in Bangalore?” or helping you find all the restaurants where your favorite delicacy is served in Koramangala. The chatbot can retrieve the contextual piece of information in its retrieval step and generate an answer to this question with the help of the LLM.
Advanced RAG
An advanced RAG framework incorporates more complex retrieval techniques, better integration of retrieved information, and often, the ability to iteratively refine both the retrieval and generation processes. In this section, you will learn how to build an intelligent recommendation engine on fashion data that can identify the interest of the user and then generate relevant fashion product or accessory recommendations only when there is intent to purchase a product in the user’s utterance. You will be building an intelligent conversation chatbot that leverages the power of LangChain, MongoDB Atlas Vector Search, and OpenAI in this section.
The advanced RAG system in the current example will demonstrate the following features:
- Utilize an LLM to generate multiple searchable fashion queries given a user’s chat utterance
- Classify the user’s chat utterance as to whether there is an intent to purchase
- Develop a fusion stage that will also fetch vector similarity search results from multiple search queries to fuse them as a single recommendation set that is reranked with the help of an LLM
The flow of steps when a user queries the RAG system is depicted in Figure 8.9:
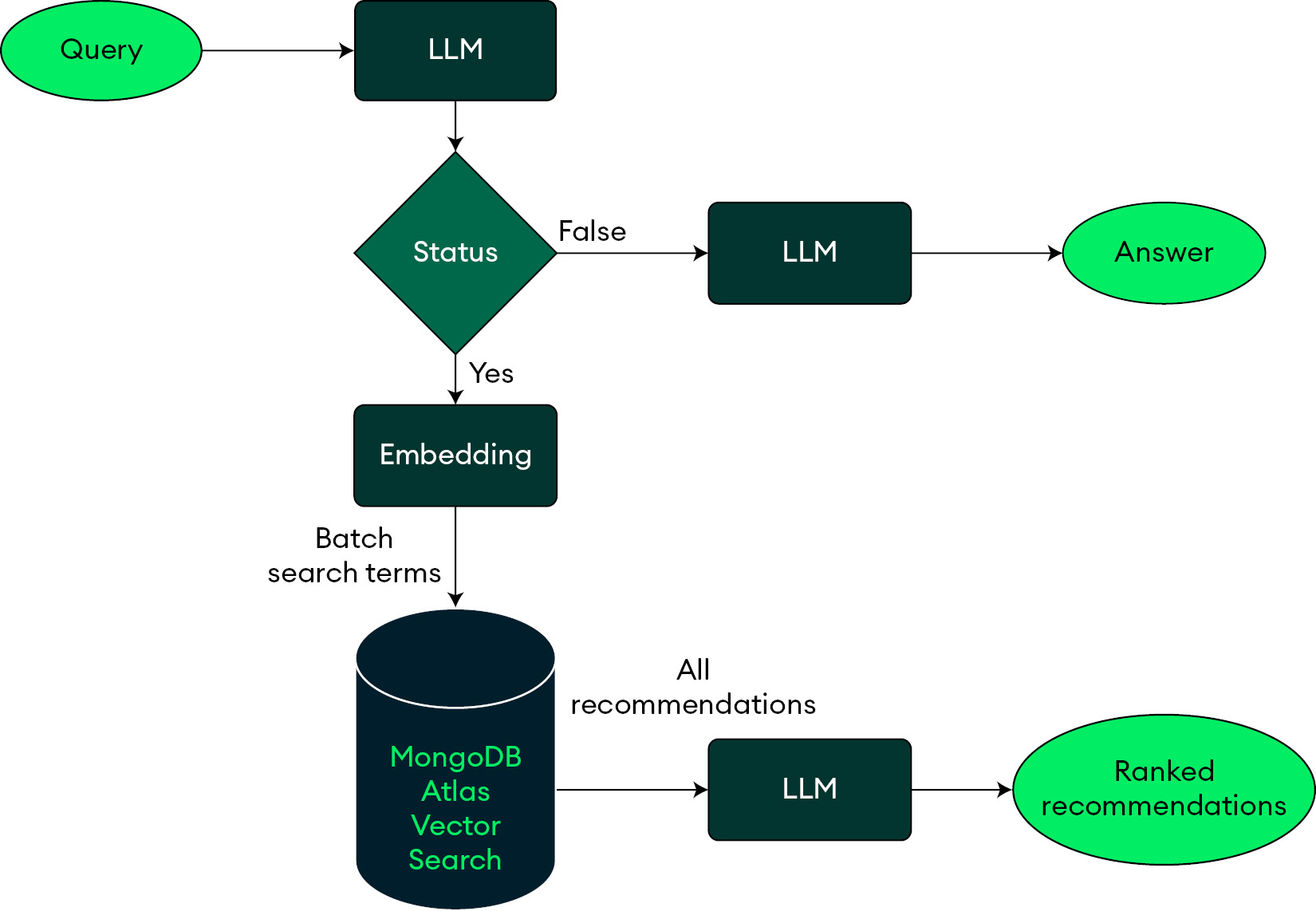
Figure 8.9: Sample advanced RAG, flowchart for query processing and recommendation
Let’s walk through the code to load the sample dataset and build the advanced RAG system with all the features that were listed at the beginning of this section.
Loading the dataset
For this example, you will utilize fashion data from a popular e-commerce company. The following code shows you how to load a dataset from an S3 bucket to a pandas DataFrame and then insert these documents into a MongoDB Atlas collection, search.catalog_final_myn:
import pandas as pd import s3fs import os import boto3 s3_uri= "https://ashwin-partner-bucket.s3.eu-west-1.amazonaws.com/fashion_dataset.jsonl" df = pd.read_json(s3_uri, orient="records", lines=True) print(df[:3]) from pymongo import MongoClient mongo_client = MongoClient(os.environ["MONGODB_CONNECTION_STR"]) # Upload documents along with vector embeddings to MongoDB Atlas Collection col = mongo_client["search"]["catalog_final_myn"] col.insert_many(df.to_dict(orient="records"))
Here is the result:

Figure 8.10: Sample view of the fashion dataset with OpenAI embeddings
Creating a vector search index
As you can see in Figure 8.10, the vector embeddings are already provided as part of the dataset. Therefore, the next step is to create a vector search index. You can create the vector search index by following the steps detailed in Chapter 5, Vector Databases, using the following index mapping:
{
"fields": [
{
"type": "vector",
"numDimensions": 1536,
"path": "openAIVec",
"similarity": "cosine"
}
]
} Fashion recommendations using advanced RAG
You have successfully loaded the new fashion dataset into the MongoDB Atlas collection and also created a vector search index with all the building blocks in place. You can now use the following code to set up an advanced RAG system and build a recommender system with the features mentioned earlier:
from langchain_core.output_parsers import JsonOutputParser # type: ignore
from langchain_core.prompts import PromptTemplate # type: ignore
from langchain_core.pydantic_v1 import BaseModel, Field # type: ignore
from langchain_openai import ChatOpenAI # type: ignore
from langchain_community.embeddings import OpenAIEmbeddings # type: ignore
from langchain_mongodb.vectorstores import MongoDBAtlasVectorSearch # type: ignore
from pymongo import MongoClient # type: ignore
from typing import List
from itertools import chain
import certifi # type: ignore
import os
from dotenv import load_dotenv # type: ignore
load_dotenv()
from functools import lru_cache
@lru_cache
def get_openai_emb_transformers():
"""
Returns an instance of OpenAIEmbeddings for OpenAI transformer models.
This function creates and returns an instance of the OpenAIEmbeddings class,
which provides access to OpenAI transformer models for natural language processing.
The instance is cached using the lru_cache decorator for efficient reuse.
Returns:
embeddings (OpenAIEmbeddings): An instance of the OpenAIEmbeddings class.
"""
embeddings = OpenAIEmbeddings()
return embeddings
@lru_cache
def get_vector_store():
"""
Retrieves the vector store for MongoDB Atlas.
Returns:
MongoDBAtlasVectorSearch: The vector store object.
"""
vs = MongoDBAtlasVectorSearch(collection=col, embedding=get_openai_emb_transformers(), index_name="vector_index_openAi_cosine", embedding_key="openAIVec", text_key="title")
return vs
@lru_cache(10)
def get_conversation_chain_conv():
"""
Retrieves a conversation chain model for chat conversations.
Returns:
ChatOpenAI: The conversation chain model for chat conversations.
"""
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0.2, max_tokens=2048)
# chain = ConversationChain(llm=llm, memory=ConversationBufferWindowMemory(k=5))
return llm
# Define your desired data structure.
class ProductRecoStatus(BaseModel):
"""
Represents the status of product recommendations.
Attributes:
relevancy_status (bool): Product recommendation status conditioned on the context of the input query.
True if the query is related to purchasing fashion clothing and/or accessories.
False otherwise.
recommendations (List[str]): List of recommended product titles based on the input query context and
if the relevancy_status is True.
"""
relevancy_status: bool = Field(description="Product recommendation status is conditioned on the fact if the context of input query is to purchase a fashion clothing and or fashion accessories.")
recommendations: List[str] = Field(description="list of recommended product titles based on the input query context and if recommendation_status is true.")
class Product(BaseModel):
"""
Represents a product.
Attributes:
title (str): Title of the product.
baseColour (List[str]): List of base colours of the product.
gender (List[str]): List of genders the product is targeted for.
articleType (str): Type of the article.
mfg_brand_name (str): Manufacturer or brand name of the product.
"""
title: str = Field(description="Title of the product.")
baseColour: List[str] = Field(description="List of base colours of the product.")
gender: List[str] = Field(description="List of genders the product is targeted for.")
articleType: str = Field(description="Type of the article.") mfg_brand_name: str = Field(description="Manufacturer or brand name of the product.")
class Recommendations(BaseModel):
"""
Represents a set of recommendations for products and a message to the user.
Attributes:
products (List[Product]): List of recommended products.
message (str): Message to the user and context of the chat history summary.
"""
products: List[Product] = Field(description="List of recommended products.")
message: str = Field(description="Message to the user and context of the chat history summary.")
reco_status_parser = JsonOutputParser(pydantic_object=ProductRecoStatus)
reco_status_prompt = PromptTemplate( template="You are AI assistant tasked at identifying if there is a product purchase intent in the query and providing suitable fashion recommendations.\n{format_instructions}\n{query}\n\
#Chat History Summary: {chat_history}\n\nBased on the context of the query, please provide the relevancy status and list of recommended products.",
input_variables=["query", "chat_history"],
partial_variables={"format_instructions": reco_status_parser.get_format_instructions()},
)
reco_parser = JsonOutputParser(pydantic_object=Recommendations)
reco_prompt = PromptTemplate(
input_variables=["question", "recommendations", "chat_history"],
partial_variables={"format_instructions": reco_parser.get_format_instructions()},
template="\n User query:{question} \n Chat Summary: {chat_history} \n Rank and suggest me suitable products for creating grouped product recommendations given all product recommendations below feature atleast one product for each articleType \n {recommendations} \n show output in {format_instructions} for top 10 products"
)
def get_product_reco_status(query: str, chat_history: List[str] = []):
"""
Retrieves the recommendation status for a product based on the given query and chat history.
Args:
query (str): The query to be used for retrieving the recommendation status.
chat_history (List[str]): The chat history containing previous conversations.
Returns:
The response containing the recommendation status.
"""
llm = get_conversation_chain_conv()
chain = reco_status_prompt | llm | reco_status_parser
resp = chain.invoke({"query": query, "chat_history": chat_history})
return resp
def get_sorted_results(product_recommendations):
all_titles = [rec['title'] for rec in product_recommendations['products']]
results = list(col.find({"title": {"$in":all_titles}}, {"_id": 0 , "id":1, "title": 1, "price": 1, "baseColour": 1, "articleType": 1, "gender": 1, "link" : 1, "mfg_brand_name": 1}))
sorted_results = []
for title in all_titles:
for result in results:
if result['title'] == title:
sorted_results.append(result)
break
return sorted_results
def get_product_recommendations(query: str, reco_queries: List[str], chat_history: List[str]=[]):
"""
Retrieves product recommendations based on the given query and chat history.
Args:
query (str): The query string for the recommendation.
chat_history (List[str]): The list of previous chat messages.
filter_query (dict): The filter query to apply during the recommendation retrieval.
reco_queries (List[str]): The list of recommendation queries.
Returns:
dict: The response containing the recommendations.
"""
vectorstore = get_vector_store()
retr = vectorstore.as_retriever(search_kwargs={"k": 10})
all_recommendations = list(chain(*retr.batch(reco_queries)))
llm = get_conversation_chain_conv()
llm_chain = reco_prompt | llm | reco_parser
resp = llm_chain.invoke({"question": query, "chat_history": chat_history, "recommendations": [v.page_content for v in all_recommendations]})
resp = get_sorted_results(resp)
return resp The preceding code carries out the following tasks:
- Importing the necessary modules and functions from various libraries. These include
JsonOutputParserfor parsing JSON output,PromptTemplatefor creating prompts,BaseModelandFieldfor defining data models, andMongoDBAtlasVectorSearchfor interacting with a MongoDB Atlas vector store. It also importsMongoClientfor connecting to MongoDB,load_dotenvfor loading environment variables, andlru_cachefor caching function results. - It defines three functions, each decorated with
lru_cacheto cache their results for efficiency.get_openai_emb_transformersreturns an instance ofOpenAIEmbeddings, which provides access to OpenAI transformer models for NLP.get_vector_storeretrieves the vector store for MongoDB Atlas.get_conversation_chain_convretrieves a conversation chain model for chat conversations. - It defines three classes using Pydantic’s
BaseModelandField. These classes represent the status of product recommendations (ProductRecoStatus), a product (Product), and a set of recommendations for products and a message to the user (Recommendations). - Creating instances of
JsonOutputParserandPromptTemplatefor parsing JSON output and creating prompts, respectively. These instances are used to create conversation chains in the next section. - It defines two functions for retrieving the recommendation status for a product and retrieving product recommendations based on a given query and chat history.
get_product_reco_statususes a conversation chain to determine the recommendation status for a product based on a given query and chat history.get_product_recommendationsretrieves product recommendations based on a given query and chat history, a filter query, and a list of recommendation queries. It uses a vector store retriever to get relevant documents for each recommendation query, and then uses a conversation chain to generate the final recommendations.
Let’s now use these methods to create a product recommendations example. Enter the following code and then examine its output:
query = "Can you suggest me some casual dresses for date occasion with my boyfriend" status = get_product_reco_status(query) print(status) print(get_product_recommendations(query, reco_queries=status["recommendations"], chat_history=[])
This is the status output:
{'relevancy_status': True,
'recommendations': ['Floral Print Wrap Dress',
'Off-Shoulder Ruffle Dress',
'Lace Fit and Flare Dress',
'Midi Slip Dress',
'Denim Shirt Dress']} You can see from the preceding example output that the LLM is able to classify the product intent purchase as positive and recommend suitable queries by performing vector similarity search on the MongoDB Atlas collection.
This is the product recommendations output:
Figure 8.11: Sample output from the advanced RAG chatbot with recommendations for the user's search intent
Conversely, you can test the same methods to find a suitable place for a date instead of ideas for gifts or what to wear. In this case, the model will classify the query as having negative product purchase intent and not provide any search term suggestions:
query = "Where should I take my boy friend for date" status = get_product_reco_status(query) print(status) print(get_conversation_chain_conv().invoke(query).content)
Here is the status output:
{'relevancy_status': False, 'recommendations': []} Here is the output from the LLM:

Figure 8.12: Sample output from the advanced RAG system when there is no purchase intent in the query
Advanced RAG introduces the concept of modularity when building RAG architecture systems. The above example focuses on developing a user flow-based approach for the sample advanced RAG system. It also explores how to leverage LLMs for conditional decision making, recommendation generation, and re-ranking the recommendations retrieved from the retriever system. The goal is to enhance the user experience during interactions with the application.

