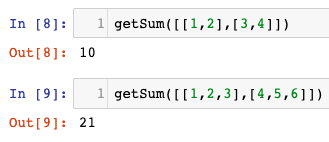
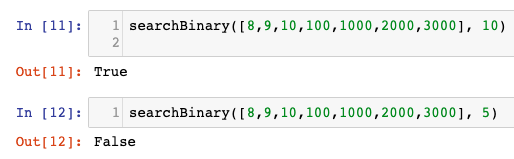
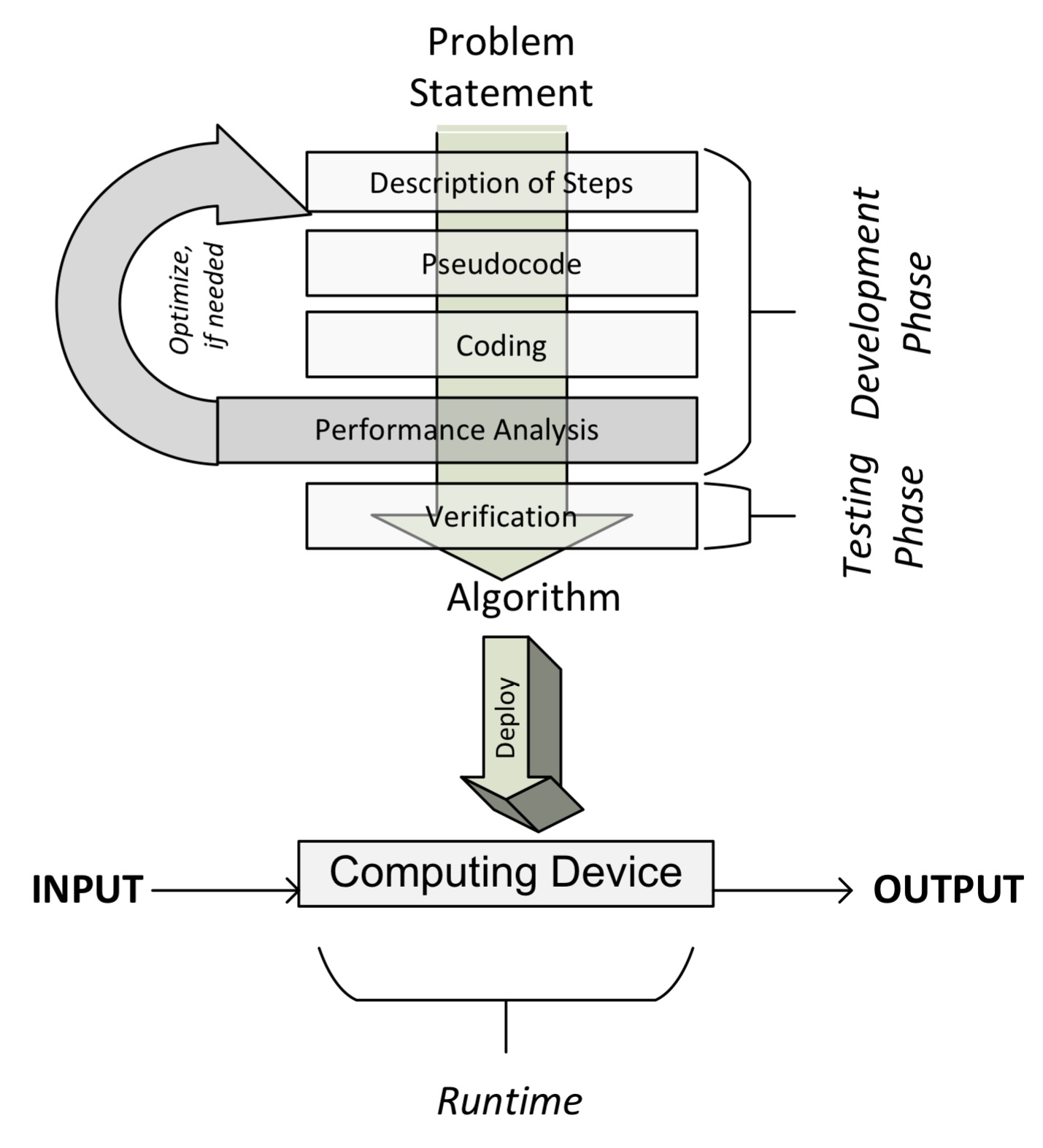
Analyzing the performance of an algorithm is an important part of its design. One of the ways to estimate the performance of an algorithm is to analyze its complexity.
Complexity theory is the study of how complicated algorithms are. To be useful, any algorithm should have three key features:
It should be correct. An algorithm won't do you much good if it doesn't give you the right answers.
A good algorithm should be understandable. The best algorithm in the world won't do you any good if it's too complicated for you to implement on a computer.
A good algorithm should be efficient. Even if an algorithm produces a correct result, it won't help you much if it takes a thousand years or if it requires 1 billion terabytes of memory.
There are two possible types of analysis to quantify the complexity of an algorithm:
Space complexity analysis: Estimates the runtime memory requirements needed to execute the algorithm.
Time complexity analysis: Estimates the time the algorithm will take to run.