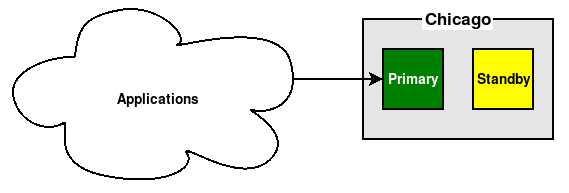
These rules are simple, but that's one of the reasons they're often overlooked. Always communicate with the Primary node through at least one proxy.
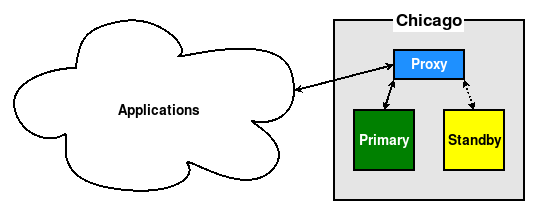
Even if this is merely an abstract network name, or an ephemeral IP address, doing so prevents problems that could occur, as seen in the following diagram:
What happens when the Primary PostgreSQL node is offline and the cluster is now being managed by the Standby? We have to reconfigure—and possibly restart—any and all applications that connect directly to it. With one simple change, we can avoid that concern, as seen here:
By following the second guideline, all traffic is directed through the Proxy, thus ensuring that either the Primary or Standby will stay online and remain accessible without further invasive changes. Now, we can switch the active primary node, perform maintenance, or even replace nodes entirely, and the application stack will only see the proxy.
We've encountered clusters that do not follow these two guidelines. Sometimes, applications will actually communicate directly with the primary node as assigned by the inventory reference number. This means any time the infrastructure team or vendor needs to reassign or rename nodes, the application becomes unusable for a short period of time.
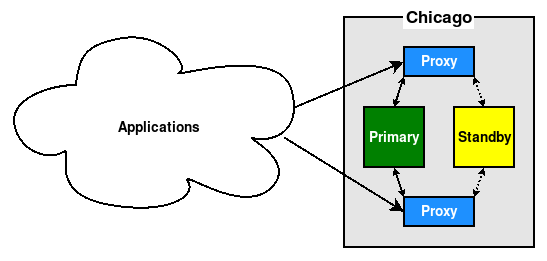
Sometimes, hardware load balancers are utilized to redirect application traffic to PostgreSQL. On other occasions, this is done with connection multiplexing software such as PgBouncer or HAProxy. In these cases the proxy is not simply a permanent network name or IP address that is associated with the PostgreSQL cluster, but a piece of hardware. This means that a software or hardware failure could also affect the proxy itself.
In this case, we recommend using two proxies, as seen here:
This is especially useful in microarchitectures, which may consist of dozens or even hundreds of different application servers. Each may target a different proxy such that a failure of either only affects the application servers assigned to it.