






















































Generating IR from the AST
The LLVM code generator takes a module in LLVM IR as input and turns it into object code or assembly text. We need to transform the AST representation into IR. To implement an IR code generator, we will look at a simple example first and then develop the classes needed for the code generator. The complete implementation will be divided into three classes:
CodeGeneratorCGModuleCGProcedure
The CodeGenerator class is the general interface used by the compiler driver. The CGModule and CGProcedure classes hold the state required for generating the IR code for a compilation unit and a single function.
We’ll begin by looking at the Clang-generated IR.
Understanding the IR code
Before generating the IR code, it’s good to know the main elements of the IR language. In Chapter 2, The Structure of a Compiler, we had a brief look at IR. An easy way to get more knowledge of IR is to study the output from clang. For example, save this C source code, which implements the Euclidean algorithm for calculating the greatest common divisor of two numbers, as gcd.c:
unsigned gcd(unsigned a, unsigned b) {
if (b == 0)
return a;
while (b != 0) {
unsigned t = a % b;
a = b;
b = t;
}
return a;
} Then, you can create the gcd.ll IR file by using clang and the following command:
$ clang --target=aarch64-linux-gnu -O1 -S -emit-llvm gcd.c
The IR code is not target-independent, even if it often looks like it is. The preceding command compiles the source file for an ARM 64-bit CPU on Linux. The -S option instructs clang to output an assembly file, and with the additional specification of -emit-llvm, an IR file is created. The optimization level, -O1, is used to get an easily readable IR code. Clang has many more options, all of which are documented in the command-line argument reference at https://clang.llvm.org/docs/ClangCommandLineReference.html. Let’s have a look at the generated file and understand how the C source maps to the LLVM IR.
A C file is translated into a module, which holds the functions and the data objects. A function has at least one basic block, and a basic block contains instructions. This hierarchical structure is also reflected in the C++ API. All data elements are typed. Integer types are represented by the letter i, followed by the number of bits. For example, the 64-bit integer type is written as i64. The most basic float types are float and double, denoting the 32-bit and 64-bit IEEE floating-point types. It is also possible to create aggregate types such as vectors, arrays, and structures.
Here is what the LLVM IR looks like. At the top of the file, some basic properties are established:
; ModuleID = 'gcd.c' source_filename = "gcd.c" target datalayout = "e-m:e-i8:8:32-i16:16:32-i64:64-i128:128-n32:64-S128" target triple = "aarch64-unknown-linux-gnu"
The first line is a comment informing you about which module identifier was used. In the following line, the filename of the source file is named. With clang, both are the same.
The target datalayout string establishes some basic properties. The different parts are separated by -. The following information is included:
- A small
emeans that bytes in memory are stored using the little-endian schema. To specify a big endian, you must use a bigE. M:specifies the name mangling that’s applied to symbols. Here,m:emeans that ELF name mangling is used.- The entries in
iN:A:Pform, such asi8:8:32, specify the alignment of data, given in bits. The first number is the alignment required by the ABI, and the second number is the preferred alignment. For bytes (i8), the ABI alignment is 1 byte (8) and the preferred alignment is 4 bytes (32). nspecifies which native register sizes are available.n32:64means that 32-bit and 64-bit wide integers are natively supported.Sspecifies the alignment of the stack, again in bits.S128means that the stack maintains a 16-byte alignment.
Note
The provided target data layout must match what the backend expects. Its purpose is to communicate the captured information to the target-independent optimization passes. For example, an optimization pass can query the data layout to get the size and alignment of a pointer. However, changing the size of a pointer in the data layout does not change the code generation in the backend.
A lot more information is provided with the target data layout. You can find more information in the reference manual at https://llvm.org/docs/LangRef.html#data-layout.
Last, the target triple string specifies the architecture we are compiling for. This reflects the information we gave on the command line. The triple is a configuration string that usually consists of the CPU architecture, the vendor, and the operating system. More information about the environment is often added. For example, the x86_64-pc-win32 triple is used for a Windows system running on a 64-bit X86 CPU. x86_64 is the CPU architecture, pc is a generic vendor, and win32 is the operating system. The parts are connected by a hyphen. A Linux system running on an ARMv8 CPU uses aarch64-unknown-linux-gnu as its triple. aarch64 is the CPU architecture, while the operating system is linux running a gnu environment. There is no real vendor for a Linux-based system, so this part is unknown. Parts that are not known or unimportant for a specific purpose are often omitted: the aarch64-linux-gnu triple describes the same Linux system.
Next, the gcd function is defined in the IR file:
define i32 @gcd(i32 %a, i32 %b) { This resembles the function signature in the C file. The unsigned data type is translated into the 32-bit integer type, i32. The function name is prefixed with @, and the parameter names are prefixed with %. The body of the function is enclosed in curly braces. The code of the body follows:
entry: %cmp = icmp eq i32 %b, 0 br i1 %cmp, label %return, label %while.body
The IR code is organized into so-called basic blocks. A well-formed basic block is a linear sequence of instructions, which begins with an optional label and ends with a terminator instruction. So, each basic block has one entry point and one exit point. LLVM allows malformed basic blocks at construction time. The label of the first basic block is entry. The code in the block is simple: the first instruction compares the %b parameter against 0. The second instruction branches to the return label if the condition is true and to the while.body label if the condition is false.
Another characteristic of the IR code is that it is in a static single assignment (SSA) form. The code uses an unlimited number of virtual registers, but each register is only written once. The result of the comparison is assigned to the named virtual register, %cmp. This register is then used, but it is never written again. Optimizations such as constant propagation and common-sub-expression elimination work very well with the SSA form and all modern compilers are using it.
SSA
The SSA form was developed in the late 1980s. Since then, it has been widely used in compilers because it simplifies data flow analysis and optimizations. For example, the identification of common sub-expressions inside a loop becomes much easier if the IR is in SSA form. A basic property of SSA is that it establishes def-use and use-def chains: for a single definition, you know of all uses (def-use), and for each use, you know the unique definition (use-def). This knowledge is used a lot, such as in constant propagation: if a definition is determined to be a constant, then all uses of this value can be easily replaced with that constant value.
To construct the SSA form, the algorithm from Cytron et al. (1989) is very popular, and it is also used in the LLVM implementation. Other algorithms have been developed too. An early observation is that these algorithms become simpler if the source language does not have a goto statement.
An in-depth treatment of SSA can be found in the book SSA-based Compiler Design, by F. Rastello and F. B. Tichadou, Springer 2022.
The next basic block is the body of the while loop:
while.body: %b.loop = phi i32 [ %rem, %while.body ], [ %b, %entry ] %a.loop = phi i32 [ %b.loop, %while.body ], [ %a, %entry ] %rem = urem i32 %a.loop, %b.loop %cmp1 = icmp eq i32 %rem, 0 br i1 %cmp1, label %return, label %while.body
Inside the loop of gcd, the a and b parameters are assigned new values. If a register can be only written once, then this is not possible. The solution is to use the special phi instruction. The phi instruction has a list of basic blocks and values as parameters. A basic block presents the incoming edge from that basic block, and the value is the value from that basic block. At runtime, the phi instruction compares the label of the previously executed basic block with the labels in the parameter list.
The value of the instruction is the value that’s associated with the label. For the first phi instruction, the value is the %rem register if the previously executed basic block was while.body. The value is %b if entry was the previously executed basic block. The values are the ones at the start of the basic block. The %b.loop register gets a value from the first phi instruction. The same register is used in the parameter list of the second phi instruction, but the value is assumed to be the one before it is changed through the first phi instruction.
After the loop’s body, the return value must be chosen:
return: %retval = phi i32 [ %a, %entry ], [ %b.loop, %while.body ] ret i32 %retval }
Again, a phi instruction is used to select the desired value. The ret instruction not only ends this basic block but also denotes the end of this function at runtime. It has the return value as a parameter.
There are some restrictions on the use of phi instructions. They must be the first instructions of a basic block. The first basic block is special: it has no previously executed block. Therefore, it cannot begin with a phi instruction.
LLVM IR reference
We’ve only touched the very basics of the LLVM IR. Please visit the LLVM Language Reference Manual at https://llvm.org/docs/LangRef.html to look up all the details.
The IR code itself looks a lot like a mix of C and assembly language. Despite this familiar style, it is not clear how we can easily generate the IR code from an AST. The phi instruction in particular looks difficult to generate. But don’t be scared – in the next section, we’ll implement a simple algorithm to just do that!
Learning about the load-and-store approach
All local optimizations in LLVM are based on the SSA form shown here. For global variables, memory references are used. The IR language knows load and store instructions, which are used to fetch and store those values. You can use this for local variables too. These instructions do not belong to the SSA form, and LLVM knows how to convert them into the required SSA form. Therefore, you can allocate memory slots for each local variable and use load and store instructions to change their value. All you need to remember is the pointer to the memory slot where a variable is stored. The clang compiler uses this approach.
Let’s look at the IR code for load and store. Compile gcd.c again, but this time without enabling optimization:
$ clang --target=aarch64-linux-gnu -S -emit-llvm gcd.c
The gcd function now looks different. This is the first basic block:
define i32 @gcd(i32, i32) {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i32, align 4
%6 = alloca i32, align 4
store i32 %0, ptr %4, align 4
store i32 %1, ptr %5, align 4
%7 = load i32, ptr %5, align 4
%8 = icmp eq i32 %7, 0
br i1 %8, label %9, label %11 The IR code now relies on the automatic numbering of registers and labels. The names of the parameters are not specified. Implicitly, they are %0 and %1. The basic block has no label, so 2 is assigned. The first few instructions allocate memory for the four 32-bit values. After that, the %0 and %1 parameters are stored in the memory slots pointed to by registers %4 and %5. To compare %1 to 0, the value is explicitly loaded from the memory slot. With this approach, you do not need to use the phi instruction! Instead, you load a value from a memory slot, perform a calculation on it, and store the new value back in the memory slot. The next time you read the memory slot, you get the last computed value. All the other basic blocks for the gcd function follow this pattern.
The advantage of using load and store instructions in this way is that it is fairly easy to generate the IR code. The disadvantage is that you generate a lot of IR instructions that LLVM will remove with the mem2reg pass in the very first optimization step, after converting the basic block into SSA form. Therefore, we generate the IR code in SSA form directly.
We’ll start developing IR code generation by mapping the control flow to basic blocks.
Mapping the control flow to basic blocks
The conceptual idea of a basic block is that it is a linear sequence of instructions that are executed in that order. A basic block has exactly one entry at the beginning, and it ends with a terminator instruction, which is an instruction that transfers the control flow to another basic block, such as a branch instruction, a switch instruction, or a return instruction. See https://llvm.org/docs/LangRef.html#terminator-instructions for a complete list of terminator instructions. A basic block can begin with phi instructions, but inside a basic block, neither phi nor branch instructions are allowed. In other words, you can only enter a basic block at the first instruction, and you can only leave a basic block at the last instruction, which is the terminator instruction. It is not possible to branch to an instruction inside a basic block or to branch to another basic block from the middle of a basic block. Please note that a simple function call with the call instruction can occur inside a basic block. Each basic block has exactly one label, marking the first instruction of the basic block. Labels are the targets of branch instructions. You can view branches as directed edges between two basic blocks, resulting in the control flow graph (CFG). A basic block can have predecessors and successors. The first basic block of a function is special in the sense that no predecessors are allowed.
As a consequence of these restrictions, control statements of the source language, such as WHILE and IF, produce several basic blocks. Let’s look at the WHILE statement. The condition of the WHILE statement controls if the loop body or the next statement is executed. The condition must be generated in a basic block of its own because there are two predecessors:
- The basic block resulting from the statement before
WHILE - The branch from the end of the loop body back to the condition
There are also two successors:
- The beginning of the loop body
- The basic block resulting from the statement following
WHILE
The loop body itself has at least one basic block:
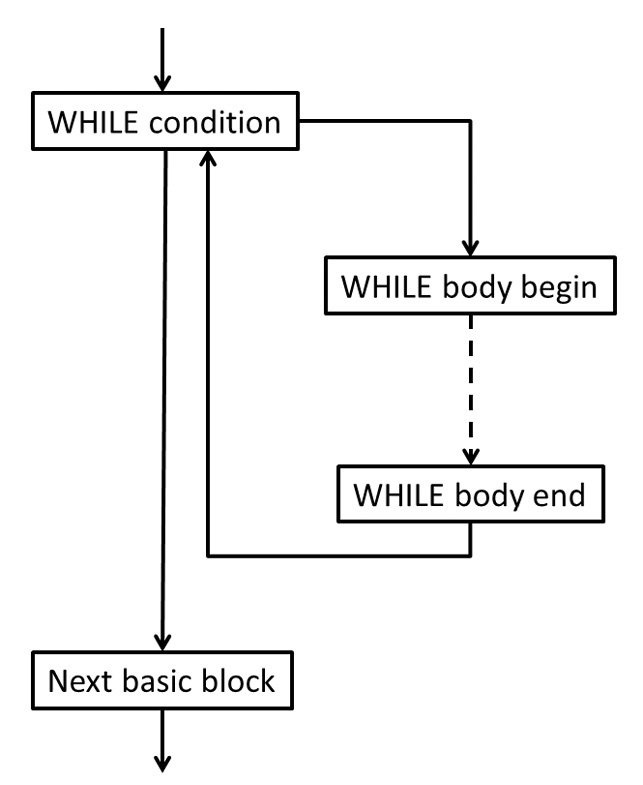
Figure 4.1 – The basic blocks of a WHILE statement
The IR code generation follows this structure. We store a pointer to the current basic block in the CGProcedure class and use an instance of llvm::IRBuilder<> to insert instructions into the basic block. First, we create the basic blocks:
void emitStmt(WhileStatement *Stmt) {
llvm::BasicBlock *WhileCondBB = llvm::BasicBlock::Create(
CGM.getLLVMCtx(), "while.cond", Fn);
llvm::BasicBlock *WhileBodyBB = llvm::BasicBlock::Create(
CGM.getLLVMCtx(), "while.body", Fn);
llvm::BasicBlock *AfterWhileBB = llvm::BasicBlock::Create(
CGM.getLLVMCtx(), "after.while", Fn); The Fn variable denotes the current function and getLLVMCtx() returns the LLVM context. Both are set later. We end the current basic block with a branch to the basic block, which will hold the condition:
Builder.CreateBr(WhileCondBB);
The basic block for the condition becomes the new current basic block. We generate the condition and end the block with a conditional branch:
setCurr(WhileCondBB); llvm::Value *Cond = emitExpr(Stmt->getCond()); Builder.CreateCondBr(Cond, WhileBodyBB, AfterWhileBB);
Next, we generate the loop body. Finally, we add a branch back to the basic block of the condition:
setCurr(WhileBodyBB); emit(Stmt->getWhileStmts()); Builder.CreateBr(WhileCondBB);
With that, we have generated the WHILE statement. Now that we’ve generated the WhileCondBB and Curr blocks, we can seal them:
sealBlock(WhileCondBB); sealBlock(Curr);
The empty basic block for statements following WHILE becomes the new current basic block:
setCurr(AfterWhileBB); }
Following this schema, you can create an emit() method for each statement of the source language.











