






















































In this section, we will provide an overview of the major applications of NLP. While the topics listed here are not quite exhaustive, they will give the reader a sense of the wide range of applications where NLP is used.
Applications of NLP
Analyzing sentiment
The sentiment in a sentence or text reflects the overall positive, negative, or neutral opinion or thought of the person who produces or consumes it. It indicates whether a person is happy, unhappy, or neutral about the subject or context that describes the text. It can be quantified as a discrete value, such as 1 for happy, -1 for unhappy, and 0 for neutral, or it can be quantified on a continuous scale of values, from 0-1. Sentiment analysis, therefore, is the process of deriving this value from a piece of text that can be obtained from different data sources, such as social networks, product reviews, news articles, and so on. One real-world application of sentiment analysis is in social network data to derive actionable insights, such as customer satisfaction, product or brand popularity, fashion trends, and so on. The screenshot that follows shows one of the applications of sentiment analysis, in capturing the overall opinion of a particular news article about Google. The reader may refer to the application, or API, from Google Cloud at https://cloud.google.com/natural-language/:

The preceding screenshot indicates that sentiment data is captured for the whole document, as well as at the individual sentence level.
Recognizing named entities
NER is a type of text annotation task. In NER, words or tokens in a piece of text are labeled or annotated into categories, such as organizations, locations, people, and so on. In effect, NER converts unstructured text data into structured data that can later be used for further analysis. The following screenshot is a visualization from the Google Cloud API. The reader can try out the API with the link provided in the preceding subsection:
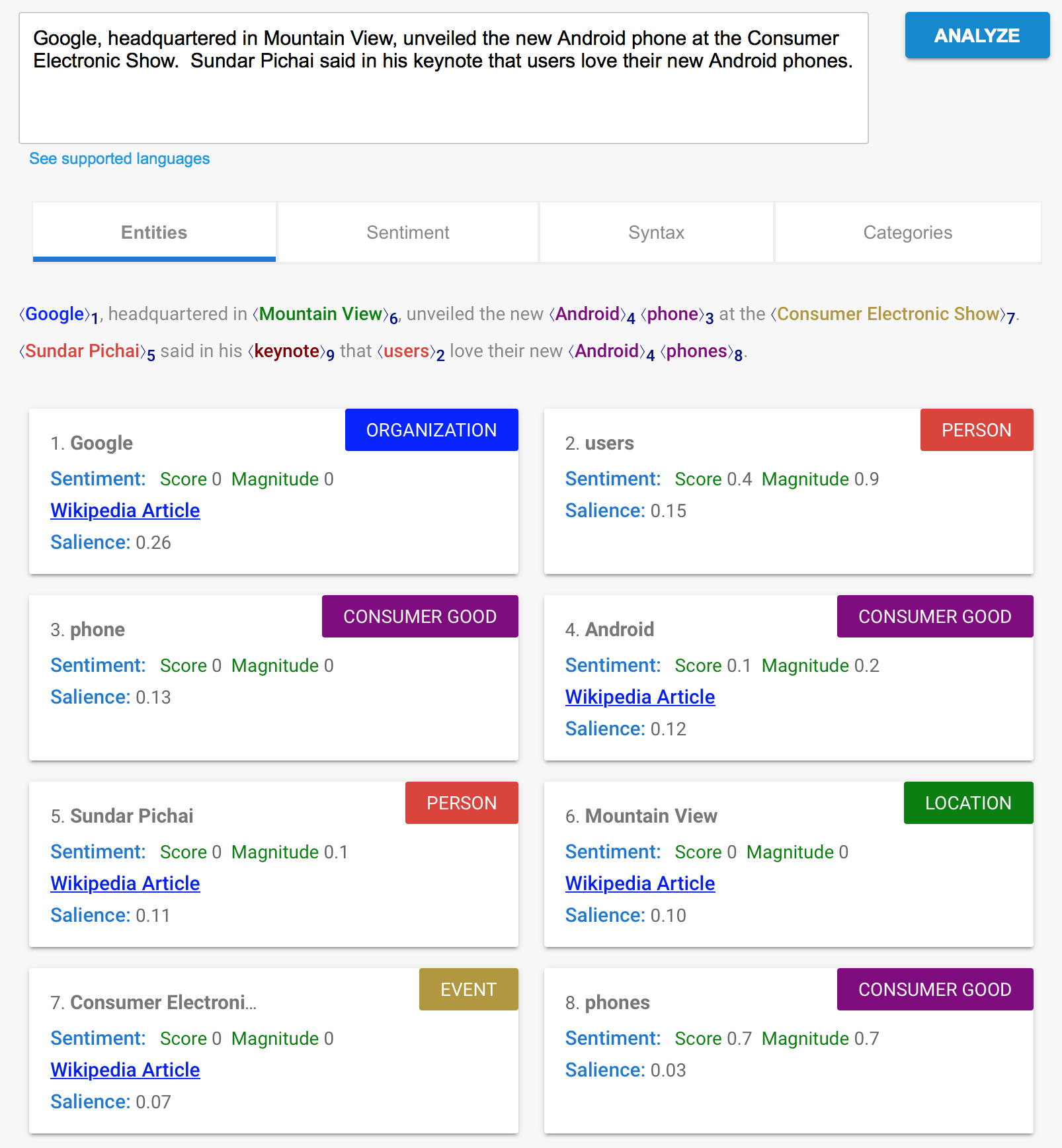
The output result in the preceding screenshot shows how the different entities, such as ORGANISATION (Google), PERSON (Sundar Pitchai), EVENT (CONSUMER ELECTRONICS SHOW), and so on, are automatically extracted from the unstructured raw text by NER. The output also gives the sentiment for each label or category, based on sentiment analysis. The reader can experiment with different text using the link provided earlier. When we click on the Categories tab, we can see the following:

The preceding screenshot shows how the system also classifies a particular piece of text into Computer & Electronics, News, and so on, using the recognized named entities in the text. Such a categorization, called topic modeling, is another important NLP task, used to identify the main theme or topic of a sentence or document.
Linking entities
Another practical application is entity linking. One good example of it can be found in the Microsoft Azure Text Analytics API, at https://azure.microsoft.com/is-is/services/cognitive-services/text-analytics/. The following screenshot shows output from a sample text:
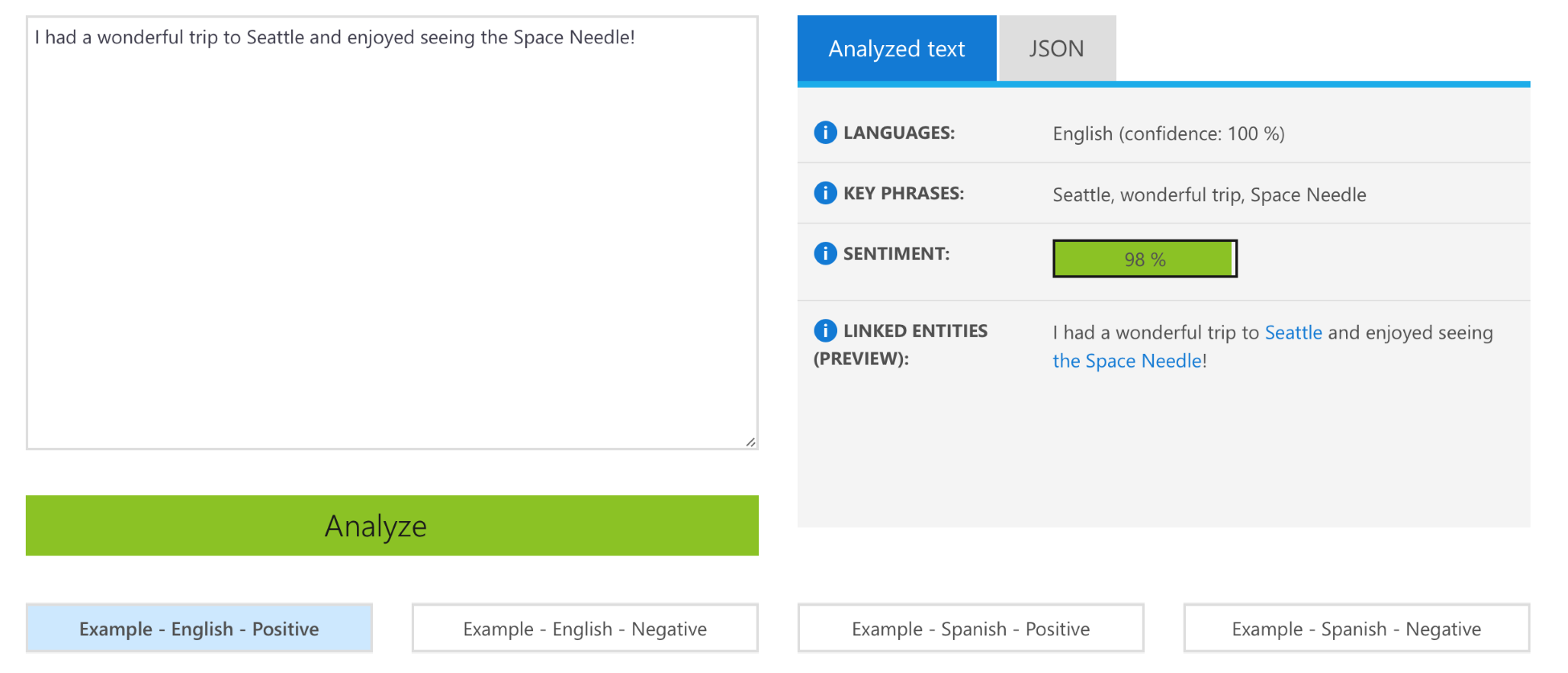
The preceding screenshot shows how the system has automatically extracted the entity Seattle as a place. Interestingly, it has also correctly extracted the Space Needle as a landmark place, by linking it with Seattle. This shows how powerful named entity linking can be when extracting useful relationships between entities.
Translating text
Machine translation is the task of translating a given piece of text from one language to another target language. The language of the task is first identified, and then translated into the target language. The translation app from Google has proven very useful for traveling and has taken down language barriers. The latest techniques have improved the translation accuracy by a large margin.
Following is an example of translation from Chinese to English, using Google Translate at https://cloud.google.com/translate/:
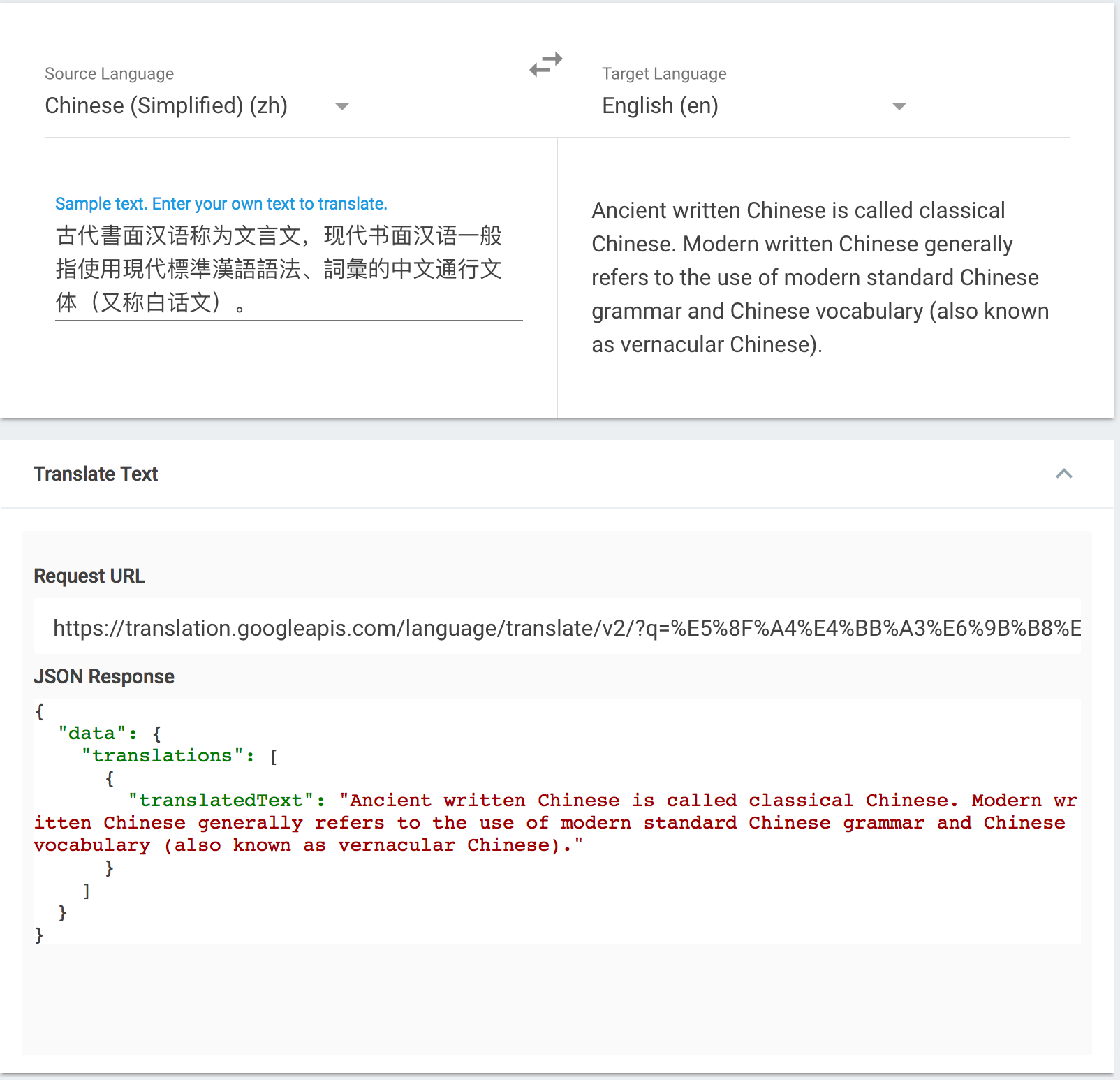
The preceding screenshot also shows the JSON response of the translated text, when we use the Translation API service from Google (https://cdn-images-1.medium.com/max/1600/1*3f4l4lrLFFhgvVsvjhNzAQ.jpeg).
Natural Language Inference
Natural Language Inference (NLI) tasks classify the relationship between a premise and hypothesis. During inference, a premise and hypothesis are given as input to output whether a hypothesis is true based on a given premise.
Semantic Role Labeling
Semantic Role Labeling (SRL) determines the relationship between a given sentence and a predicate, such as a verb. Sometimes, the inference is provided as a question. An example of a role might be: where or when did something happen? The following is a visualization from http://demo.allennlp.org/semantic-role-labeling:
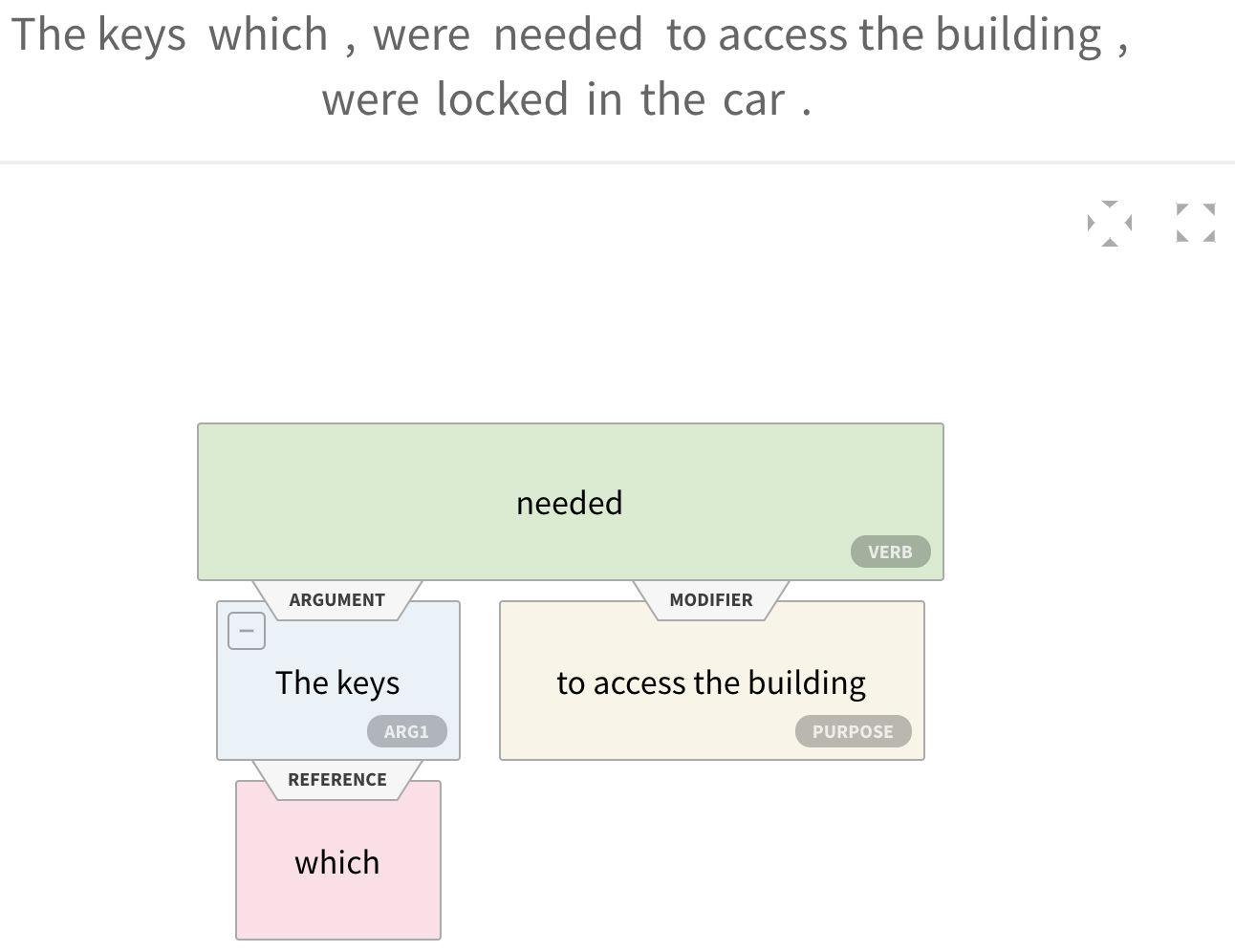
The preceding visualization shows semantic labeling, which created semantic associations between the different pieces of text, such as The keys being needed for the purpose to access the building. The reader may experiment with different examples using the URL link provided earlier.
Relation extraction
Relation extraction predicts a relationship when a text and type of relation are provided. There may be cases where the relationships can't be extracted. The following screenshot shows an example of relation extraction, based on predicates and objects:
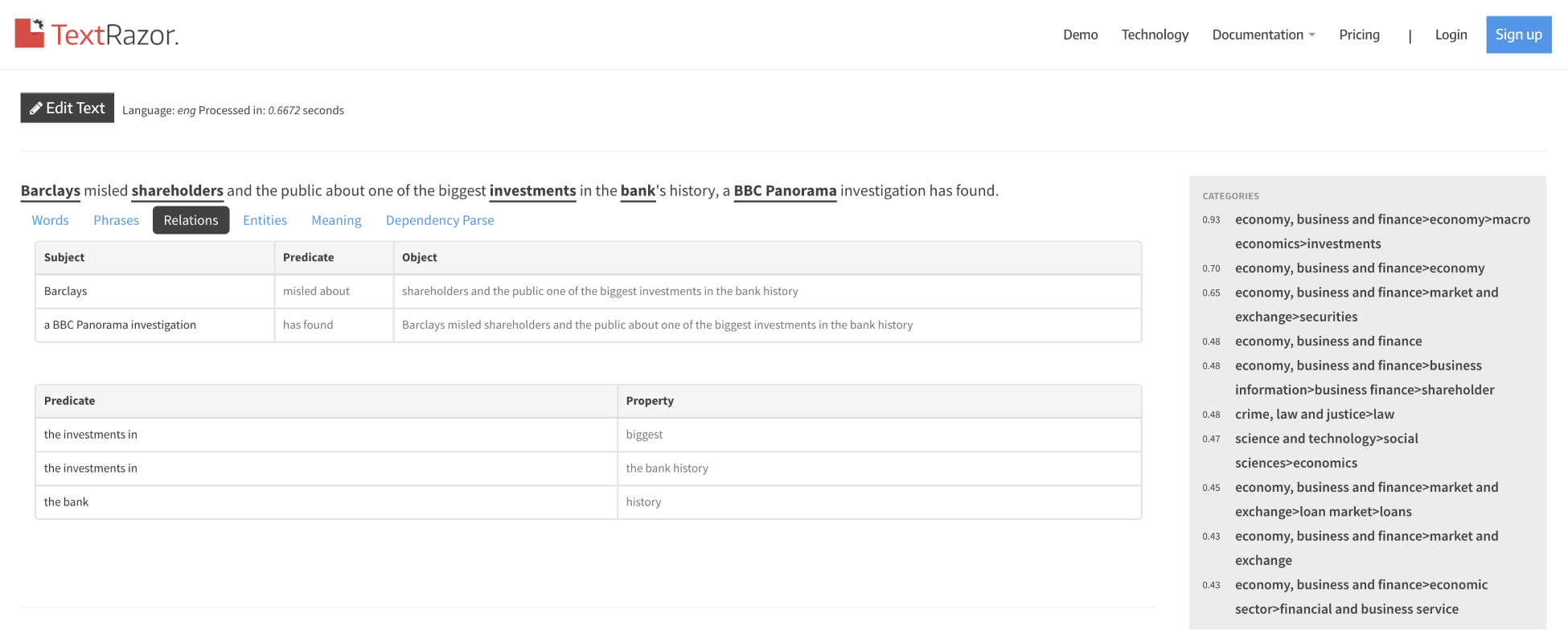
Example of relation extraction
The preceding example shows relationship extraction from the sample text to a subject, a predicate, and objects.
SQL query generation, or semantic parsing
Semantic parsing helps to convert a natural language into SQL queries in order to query a database. The following screenshot shows an example of converting a free text query to a DBpedia database SPARQL query, which is quite similar to SQL:
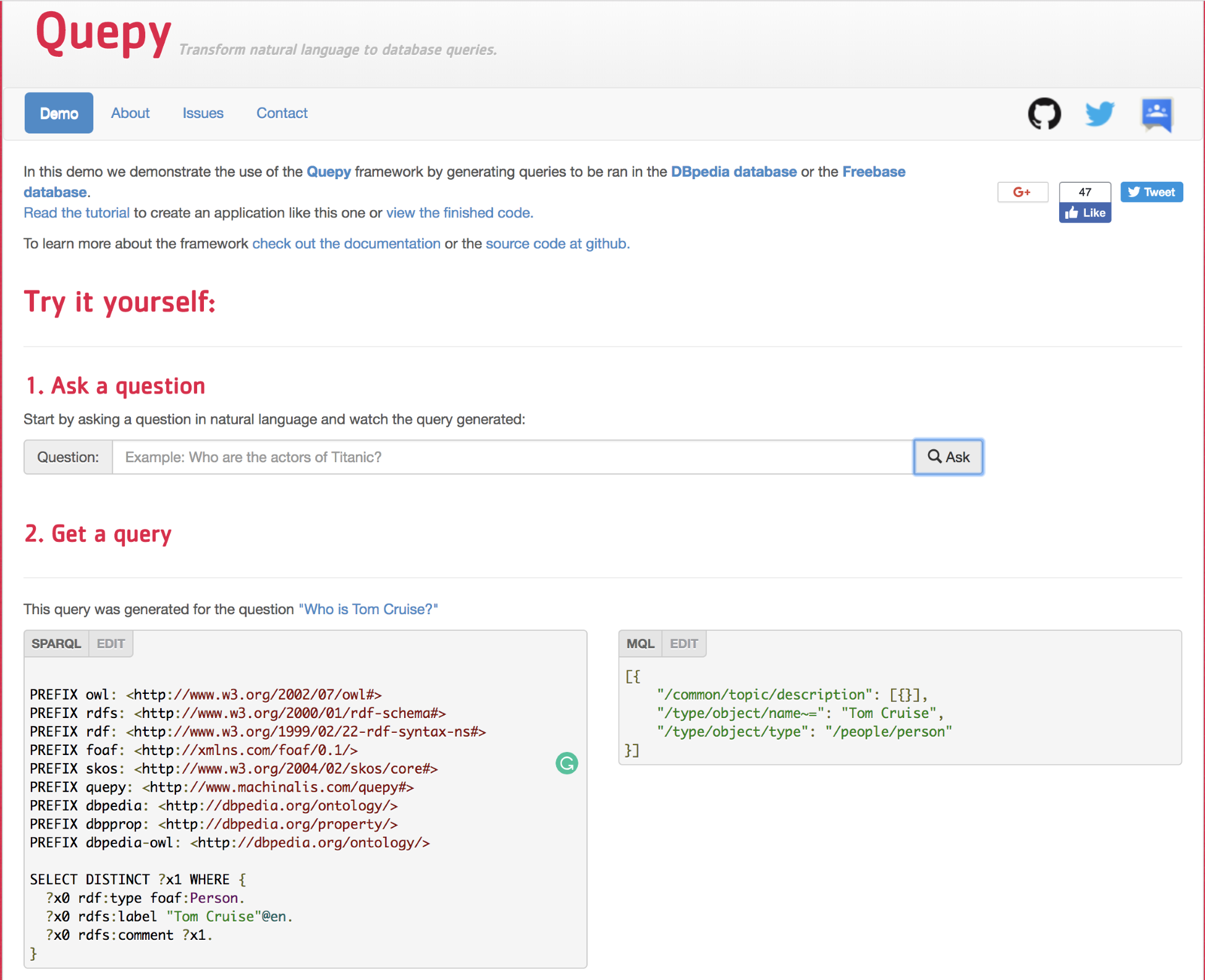
The preceding visualization shows the query Who is Tom Cruise, converted into a SPARQL query at the bottom. You can experiment with other queries at http://quepy.machinalis.com/.
Machine Comprehension
Machine Comprehension (MC) answers questions from a paragraph. It is akin to school children doing comprehension tests. The following screenshot is a visualization from http://demo.allennlp.org/machine-comprehension, for the question Who stars in The Matrix? The answer is shown in the screenshot, along with the paragraph:

We can also see a visualization of how the model works, by highlighting certain words:

Textual Entailment
Textual Entailment (TE) predicts whether the facts in different texts are the same. The following is a visualization from http://demo.allennlp.org/textual-entailment:

The premise is: If you help the needy, God will reward you. The hypothesis is: Giving money to the poor has good consequences. The probabilities of Entailment, Contradiction, and Neutral are presented.
Coreference resolution
Pronoun resolution resolves the pronouns in a text when there are several people interacting. The following is a visualization from http://demo.allennlp.org/coreference-resolution:

Searching
Searching websites for information is an integral part of accessing the internet, and is an application of NLP. The search services are provided by Bing API, from https://azure.microsoft.com/en-us/services/cognitive-services/bing-web-search-api/:

Search results displaying Yosemite National Park
Search APIs can be integrated with applications for a better user experience.
Question answering and chatbots
For question answering systems, a context is supplied with a question in order to generate an answer. The schema of a chatbot is shown in the following screenshot from https://aws.amazon.com/lex/details/:

Chatbots are application-specific, as integration varies among applications.
Converting text-to-voice
Sometimes, a text has to be converted into a voice. It can be useful for a personal bot to speak back to a user.
Let's look at how to use the AWS API for text-to-speech Amazon Polly. With the API, you can pass the text and convert it to speech. The audio file can be either streamed or downloaded.
The voice should be natural sounding, to connect with the user. Google can provide this in 30 different voices, in 12 different languages. The speed and pitch can be adjusted. Go to https://cloud.google.com/text-to-speech/ and try out a demo. The following screenshot shows an example; all of the parameters can be tuned:

Tuning of parameters
The requests can be sent from any connected device, such as a mobile, car, TV, and so on. It can be used for customer service, presenting educational text, or for animation content.
Converting voice-to-text
Sometimes, a voice has to be converted to text. This is a speech recognition problem. The Google speech recognition system works in 120 languages. The audio can be streamed, or a prerecorded video can be sent. Formatting can be done for different categories, such as proper nouns and punctuation. The following example is from https://cloud.google.com/speech-to-text/:
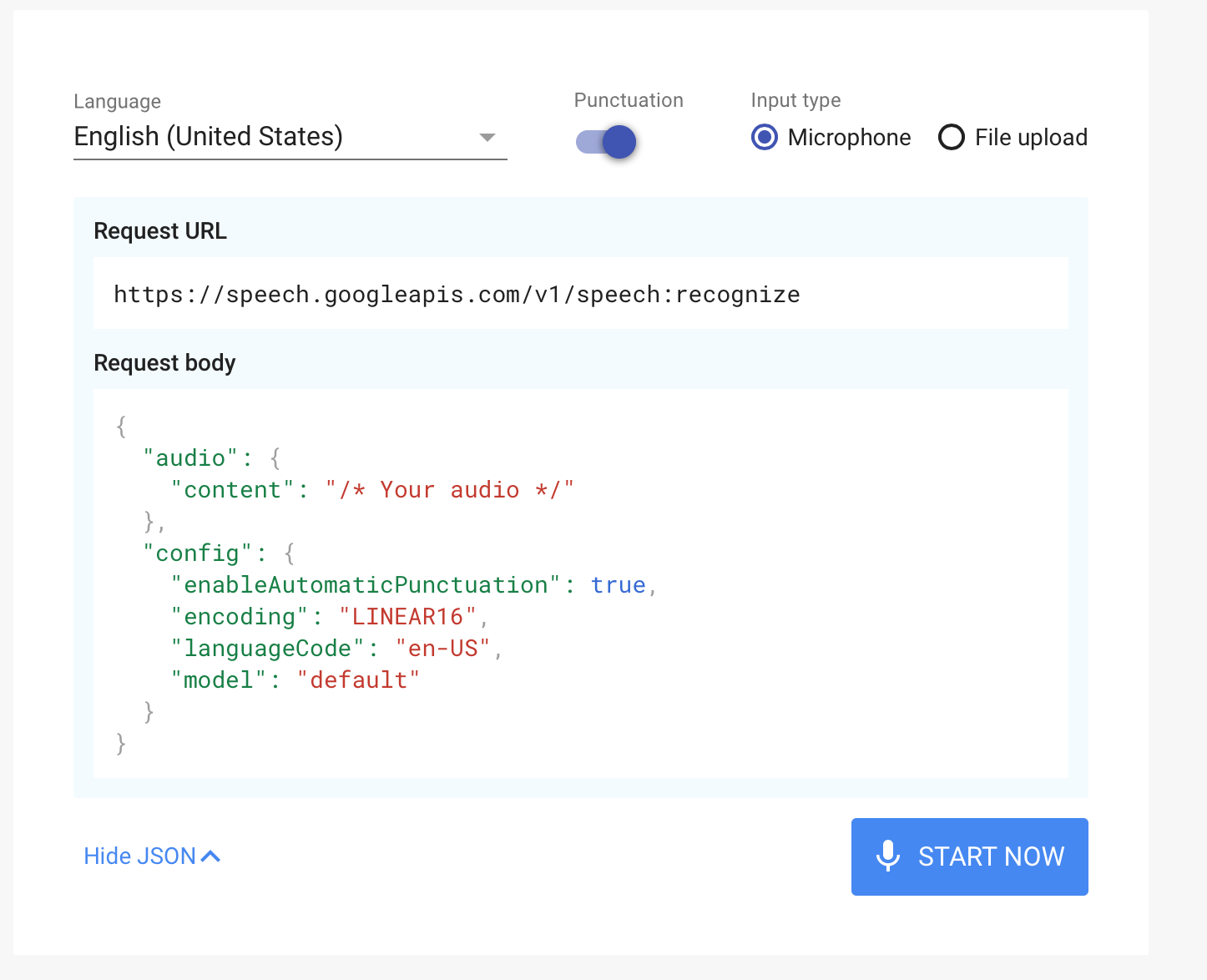
There are different models provided, for videos, phone calls, and search-based audio. This works even when there is background noise, and the system can filter inappropriate content.
Speaker identification
Speaker identification is the task of finding the name of the person that is speaking. Check out a demo at https://azure.microsoft.com/en-us/services/cognitive-services/speaker-recognition/#identification:

The voices of several people can be identified with audio clips.
Spoken dialog systems
Home assistants, such as Google Voice, Apple's Siri, and Amazon's Alexa, are examples of spoken dialog systems. All of the applications, such as chatbots, voice-to-text, text-to-voice, speaker identification, and searching, can be combined to form the experience of spoken dialog systems.
Other applications
There are several other applications of NLP; the following is a list of some of them:
- Detecting spam: The emails that we receive can be classified as spam or not spam.
- News classification: It can be useful to classify a news item based on several categories.
- Identifying the speakers, gender, or age: From a piece of text, the writer's gender and age can be detected. Similar attributes can be marked with voice data.
- Discovering topics: The topics of an article can be identified.
- Generating text: Text generated by machines has a lot of interesting applications.
- Finding duplicates: Skype has launched a live translation feature that involves speech to text, machine translation, and text-to-speech.
- Summarizing text: The summarization task takes a text as input and outputs a summary of that text. The summary is usually much shorter than the original text. For example, after a meeting, the transcript text can be summarized and sent to everyone.
- Comprehending paragraphs: Paragraph comprehension is the high school task of answering questions, with respect to a given piece of prose.
- Constituency parsing: Constituency parsing predicts a tree composition of a sentence into its constituents http://demo.allennlp.org/constituency-parsing.



