






















































Deep Q-Networks
Deep Q-networks, DQNs for short, are deep learning neural networks designed to approximate the Q-function (value-state function), it is one of the most popular value-based reinforcement learning algorithms. The model was proposed by Google's DeepMind in NIPS 2013, in the paper entitled Playing Atari with Deep Reinforcement Learning. The most important contribution of this paper was that they used the raw state space directly as input to the network; the input features were not hand-crafted as done in earlier RL implementations. Also, they could train the agent with exactly the same architecture to play different Atari games and obtain state of the art results.
This model is an extension of the simple Q-learning algorithm. In Q-learning algorithms a Q-table is maintained as a cheat sheet. After each action the Q-table is updated using the Bellman equation [5]:
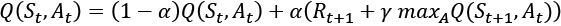
The  is the learning rate, and its value lies in the range [0,1]. The first term represents the...
is the learning rate, and its value lies in the range [0,1]. The first term represents the...



