























































DBSCAN Algorithm
The density-based spatial clustering of applications with noise (DBSCAN) algorithm groups together points that are close to each other (with many neighbors) and marks those points that are further away with no close neighbors as outliers.
According to this, and as its name states, the algorithm classifies data points based on the density of all data points in the data space.
Understanding the Algorithm
The DBSCAN algorithm requires two main parameters: epsilon and the minimum number of observations.
Epsilon, also known as eps, is the maximum distance that defines the radius within which the algorithm searches for neighbors. The minimum number of observations, on the other hand, refers to the number of data points required to form a high-density area (min_samples). However, the latter is optional in scikit-learn as the default value is set to 5:
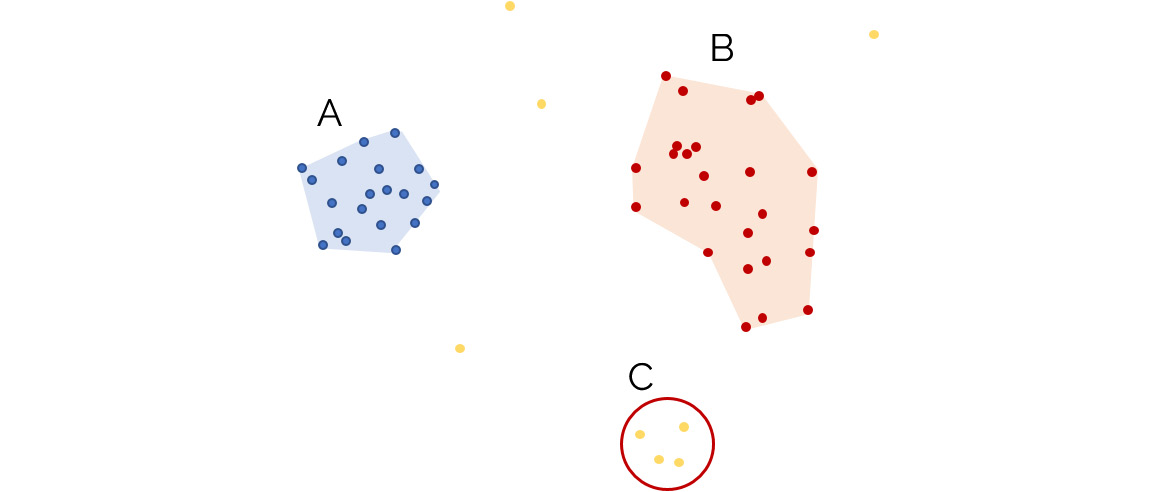
Figure 2.12: An illustration of how the DBSCAN algorithm classifies data into clusters
In the preceding diagram, the dots to the left are assigned to cluster A, while the dots to the upper right are assigned to cluster B. Moreover, the dots at the bottom right (C) are considered to be outliers, as well as any other data point in the data space, as they do not meet the required parameters to belong to a high-density area (that is, the minimum number of samples is not met, which, in this example, was set to 5).
Note
Similar to the bandwidth parameter, the epsilon value should be coherent with the distribution of the data points in the dataset, considering that it represents a radius around each data point.
According to this, each data point can be classified as follows:
- A core point: A point that has at least the minimum number of data points within its
epsradius. - A border point: A point that is within the eps radius of a core point, but does not have the required number of data points within its own radius.
- A noise point: All points that do not meet the preceding descriptions.
Note
To explore all the parameters of the DBSCAN algorithm in scikit-learn, visit http://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html.
Exercise 2.04: Importing and Training the DBSCAN Algorithm over a Dataset
This exercise discusses how to import and train the DBSCAN algorithm over a dataset. We will be using the circles dataset from the previous exercises. Perform the following steps to complete this exercise:
- Open the Jupyter Notebook that you used for the previous exercise.
- Import the DBSCAN algorithm class from scikit-learn as follows:
from sklearn.cluster import DBSCAN
- Train the model with epsilon equal to
0.1:est_dbscan = DBSCAN(eps=0.1) pred_dbscan = est_dbscan.fit_predict(data)
First, the model is instantiated with
epsof0.1. Then, we use thefit_predict()function to fit the model to the data and assign a cluster to each data point. This bundled function, which includes both thefitandpredictmethods, is used because the DBSCAN algorithm in scikit-learn does not contain apredict()method alone.Again, the value of
0.1was chosen after trying out all other possible values. - Plot the results from the clustering process:
plt.scatter(data.iloc[:,0], data.iloc[:,1], c=pred_dbscan) plt.show()
The output is as follows:
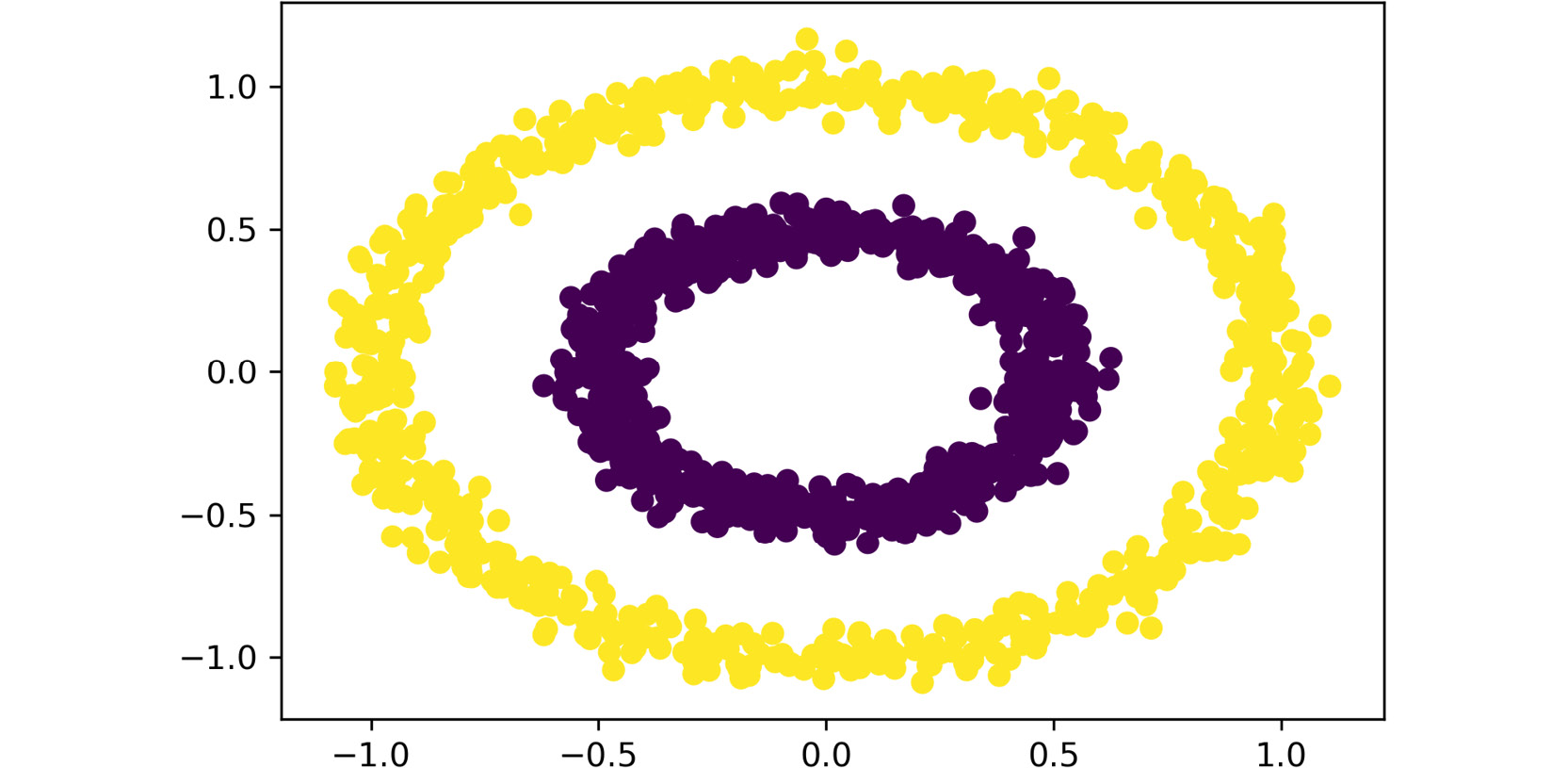
Figure 2.13: The plot obtained with the preceding code
As before, both features are passed as inputs to the scatter function. Also, the labels that were obtained from the clustering process are used as the colors to display the data points.
The total number of clusters that have been created is two.
As you can see, the total number of clusters created by each algorithm is different. This is because, as mentioned previously, each of these algorithms defines similarity differently and, as a consequence, each interprets the data differently.
Due to this, it is crucial to test different algorithms over the data to compare the results and define which one generalizes better to the data. The following topic will explore some methods that we can use to evaluate performance to help choose an algorithm.
Note
To access the source code for this exercise, please refer to https://packt.live/2Bcanxa.
You can also run this example online at https://packt.live/2UKHFdp. You must execute the entire Notebook in order to get the desired result.
You have successfully imported and trained the DBSCAN algorithm.
In conclusion, the DBSCAN algorithm bases its clustering classification on the density of data points in the data space. This means that clusters are formed by data points with many neighbors. This is done by considering that core points are those that contain a minimum number of neighbors within a set radius, border points are those that are located inside the radius of a core point but do not have the minimum number of neighbors within their own radius, and noise points are those that do not meet any of the specifications.
Activity 2.04: Applying the DBSCAN Algorithm to the Dataset
You will apply the DBSCAN algorithm to the dataset as well. This is basically because it is good practice to test out different algorithms when solving a data problem in order to choose the one that best fits the data, considering that there is no one model that performs well for all data problems. Using the previously loaded Wholesale Consumers dataset, apply the DBSCAN algorithm to the data and classify the data into clusters. Perform the following steps:
- Open the Jupyter Notebook that you used for the previous activity.
- Train the model and assign a cluster to each data point in your dataset. Plot the results.
Note
The solution for this activity can be found via this link.
The visualization of clusters will differ based on the epsilon and the features chosen to be plotted.






















