






















































Deploying Spark machine learning pipelines
The following figure illustrates a learning pipeline at a conceptual level. However, real-life ML pipelines are a lot more complicated, with several models being trained, tuned, combined, and so on:

The next figure shows the core elements of a typical machine learning application split into two parts: the modeling, including model training, and the deployed model (used on streaming data to output the results):
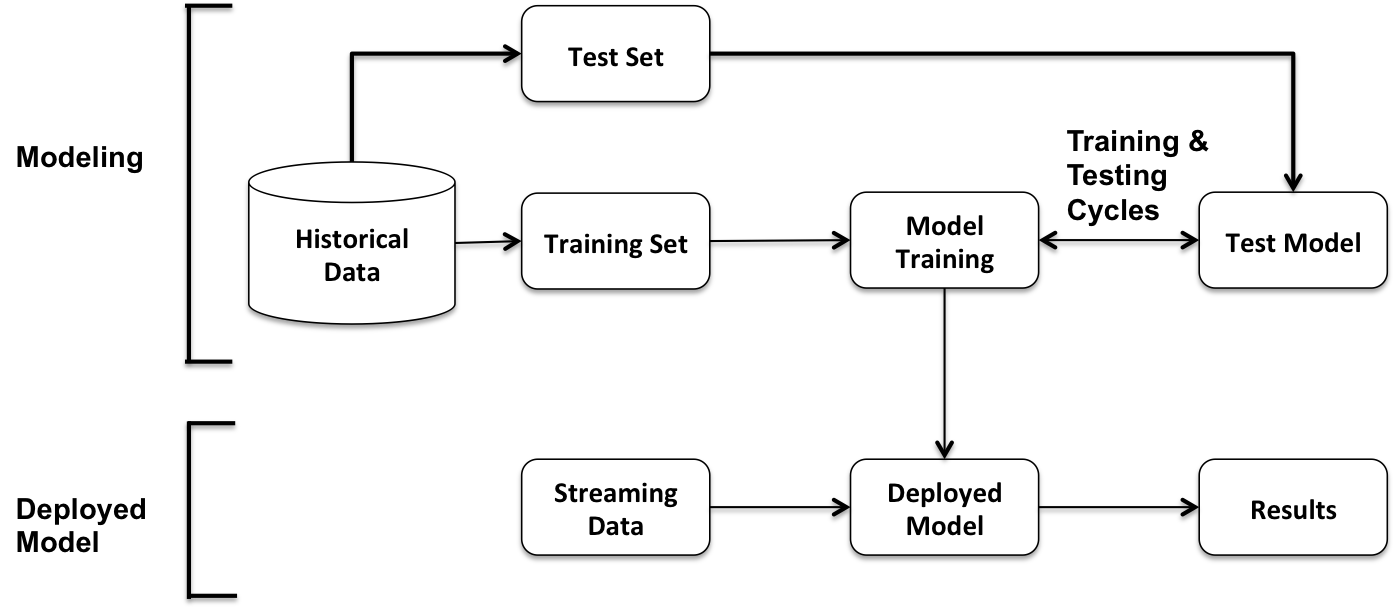
Typically, data scientists experiment or do their modeling work in Python and/or R. Their work is then reimplemented in Java/Scala before deployment in a production environment. Enterprise production environments often consist of web servers, application servers, databases, middleware, and so on. The conversion of prototypical models to production-ready models results in additional design and development effort that lead to delays in rolling out updated models.
We can use Spark MLlib 2.x model serialization to directly use the models and pipelines...





