






















































Single-node training is too slow
The vanilla model training process is to load both the training data and ML model into the same accelerator (for example, a GPU), which is called single-node training. There are mainly three steps that occur in a single node training model:
- Input pre-processing
- Training
- Validation
The following diagram shows what this looks like in a typical model training workflow:
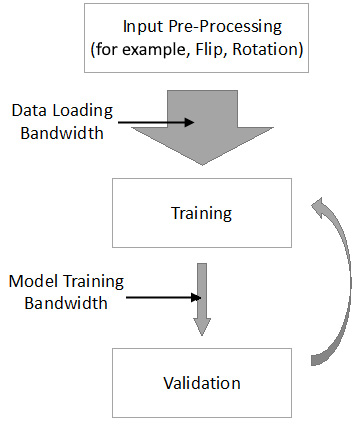
Figure 1.1 – Model training workflow on a single node
As you can see, after input pre-processing, the augmented input data is loaded into the memory of the accelerators (such as GPUs). Following that, the model is trained on the loaded input data batch and validates our trained model iteratively. The goal of this section is to discuss why single-node training is way too slow. First, we will show the real bottleneck in single-node training and then describe how data parallelism mitigates this bottleneck.
The mismatch between data loading bandwidth and model training bandwidth
Now, let's focus on the two kinds of bandwidth (BW) in this data pipeline, namely data loading bandwidth and model training bandwidth, as shown in the preceding diagram. Nowadays, we have more and more input data. Hence, we would ideally want the data loading bandwidth to be as large as possible (the wide gray arrow in the preceding diagram). However, due to the limited on-device memory of the GPUs or other accelerators, the real model training bandwidth is also limited (the narrow gray arrow in the preceding diagram).
Although it is generally believed that the larger input data size leads to a longer training time in single-node training, this is not true from the data flow perspective. From a system perspective, the mismatch between data loading bandwidth and model training bandwidth is the real issue. If we can match data loading bandwidth and model training bandwidth in single-node training, it is unnecessary to conduct in-parallel model training since distributed data processing will always introduce control overheads.
Real Bottleneck
A large input data size is not the fundamental cause of long training times in terms of single nodes. The mismatch between data loading bandwidth and model training bandwidth is the key issue.
Now that we know the reason behind the delay in single-node training when faced with large input data, let's move on to the next subtopic. Next, we will quantitively show the training times of some classic deep learning models by using standard datasets. This should help you understand why data parallel training is a must-have to deal with the mismatch between data loading bandwidth and model training bandwidth.
Single-node training time on popular datasets
Let's directly jump into training time analysis using a single GPU. We will use an NVIDIA Tesla M60 GPU as the accelerator. First, we will train both VGG-19 and ResNet-164 on the CIFAR-10 and CIFAR-100 datasets. The following diagram shows the corresponding total training time for reaching a model test accuracy over 91%:
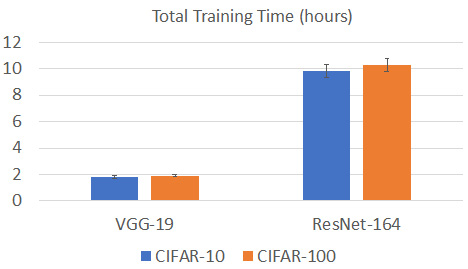
Figure 1.2 – Model training time of a single node on the CIFAR-10/100 datasets
As we can see, the total training time of VGG-19 is around 2 hours for both the CIFAR-10 and CIFAR-100 datasets, while for ResNet-164, the total training time for both the CIFAR-10 and CIFAR-100 datasets is around 10 hours.
It seems that the standard model training time, when using a single GPU on the CIFAR-10/100 dataset, is neither short nor long, which is acceptable. This is mainly because of low image resolution. For the CIFAR-10/100 datasets, the resolution of each image is very low at 32x32. Thus, the intermediate results that are generated during the model training stage are relatively small, since the activation matrices in the intermediate results are always less than 32x32. Since we generate smaller activations during training in a given fixed hardware memory size, we can train more input images at once. Consequently, we can achieve a higher model training bandwidth, which mitigates the mismatch between data loading bandwidth and model training bandwidth.
Now, let's look at a modern ML model training dataset, such as ImageNet-1K. We have maintained a similar training environment setup to what we had for our CIFAR-10/100 training jobs. The difference is that we are training the VGG-19 and ResNet-50 models. The following diagram shows the corresponding total training time with a single GPU setting:
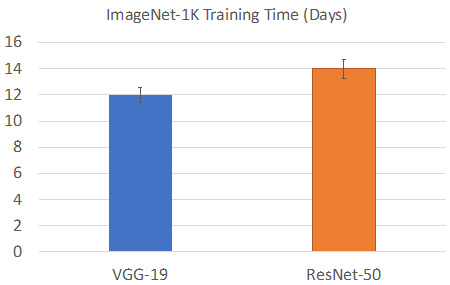
Figure 1.3 – Model training time for a single node on the ImageNet-1K dataset
As we can see, the training time on a single GPU is unacceptable. It takes around 2 weeks to train a single model, such as VGG-19 or ResNet-50. The main reason for this much slower training speed on the ImageNet-1K dataset is the higher image resolution, which is now around 256x256. Having a higher image resolution means that each training image will have a bigger memory footprint for storing its activations, which means that we can only train a smaller amount of images at once. Thus, the gap between model training bandwidth and data loading bandwidth is larger. Furthermore, the training time can be even longer for wider and deeper model training.
For our machine learning practitioners, the whole model updating cycle is way too long if we only limit ourselves to using a single GPU. This long training time is amplified since we need to try multiple sets of hyperparameters and find the best training recipes.
Therefore, we need to adopt the data parallel training paradigm to mitigate this mismatch between data loading bandwidth and model training bandwidth.
Accelerating the training process with data parallelism
So far, we have discussed why data parallel training is a must-have due to the mismatch between data loading bandwidth and model training bandwidth. Before we dive into the details of how data parallel training works, let's look at the speed-ups that data parallelism can achieve over single node training.
Let's take ResNet-50 training on the ImageNet-1K dataset as an example. By using a proper hyperparameter setup, the following diagram shows the normalized speedups over different GPU training baselines:
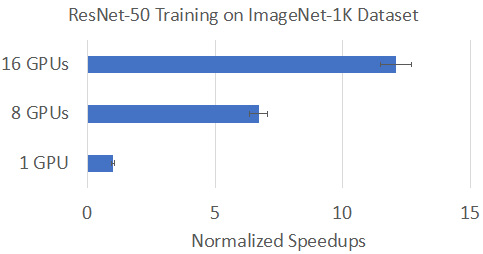
Figure 1.4 – Normalized speedups over a single GPU baseline
As we can see, we have tested the system throughput for the data parallel training process over a single GPU training baseline. By incorporating multiple GPUs into the same training job, we expanded our model training bandwidth significantly with parallelism. Ideally, the extended model training bandwidth should be linearly increased by the number of GPUs involved. Due to system control overheads and network communications introduced in data parallel training, we cannot achieve linear scaling perfectly.
However, even with system overhead involved in data parallel training, the speed-up numbers are still significant compared to a single GPU training baseline. As depicted in the preceding diagram, by incorporating 8 GPUs for data parallel training, we can increase training throughput by more than 6x. With 16 GPUs involved in the same data parallel training job, the speed-up number is even better as it can achieve near 12x higher throughput compared to the single GPU baseline. Let's convert these throughput speed-up numbers into training time: if data parallel training using 16 GPUs, we can reduce ResNet-50 training on the ImageNet-1K dataset from 14 days to around just 1-2 days.
In addition, this speed-up number can continue growing when we have more GPUs involved in the same data parallel training job. With state-of-the-art hardware such as NVIDIA's DGX-1 and DGX-2 machines, the training time of ResNet-50 on the ImageNet-1K dataset can be significantly reduced to less than 1 hour if we incorporate hundreds of GPUs into this data parallel model training job.
To conclude this section, single-node model training takes up a lot of time, which is mainly due to the mismatch problem between the data loading bandwidth and the model training bandwidth. By incorporating data parallelism, we can increase the model training bandwidth proportionally to the number of accelerators involved in the same training job.

